Boost Ranker
Boost Ranker 不单纯依赖基于向量距离计算的语义相似度,而是让你能够以有意义的方式影响搜索结果。它非常适合使用元数据过滤快速调整搜索结果的场景。
当搜索请求包含 Boost Ranker 函数时,Zilliz Cloud 使用该函数内的可选过滤条件在搜索结果候选集中查找匹配项,并通过应用指定的权重来提升这些匹配项的得分,从而在最终结果中提升或降低匹配实体的排名。
何时使用 Boost Ranker
与依赖交叉编码器模型或融合算法的其他 Ranker 不同,Boost Ranker 直接将可选的元数据驱动规则注入排序过程,这使其更适用于以下场景。
用例 | 示例 | 为什么Boost Ranker效果良好 |
|---|---|---|
业务驱动的内容优先级排序 |
| 无需重建索引或修改向量嵌入模型(这些操作可能很耗时),你可以通过实时应用可选的元数据过滤器,立即提升或降低搜索结果中特定项目的排名。这种机制实现了灵活、动态的搜索排名,能轻松适应不断变化的业务需求。 |
战略性内容降权 |
|
您还可以组合多个 Boost Ranker,以实现更动态、更稳健的基于权重的排序策略。
Boost Ranker 工作机制
下图展示了Boost Ranker 的主要工作流程。
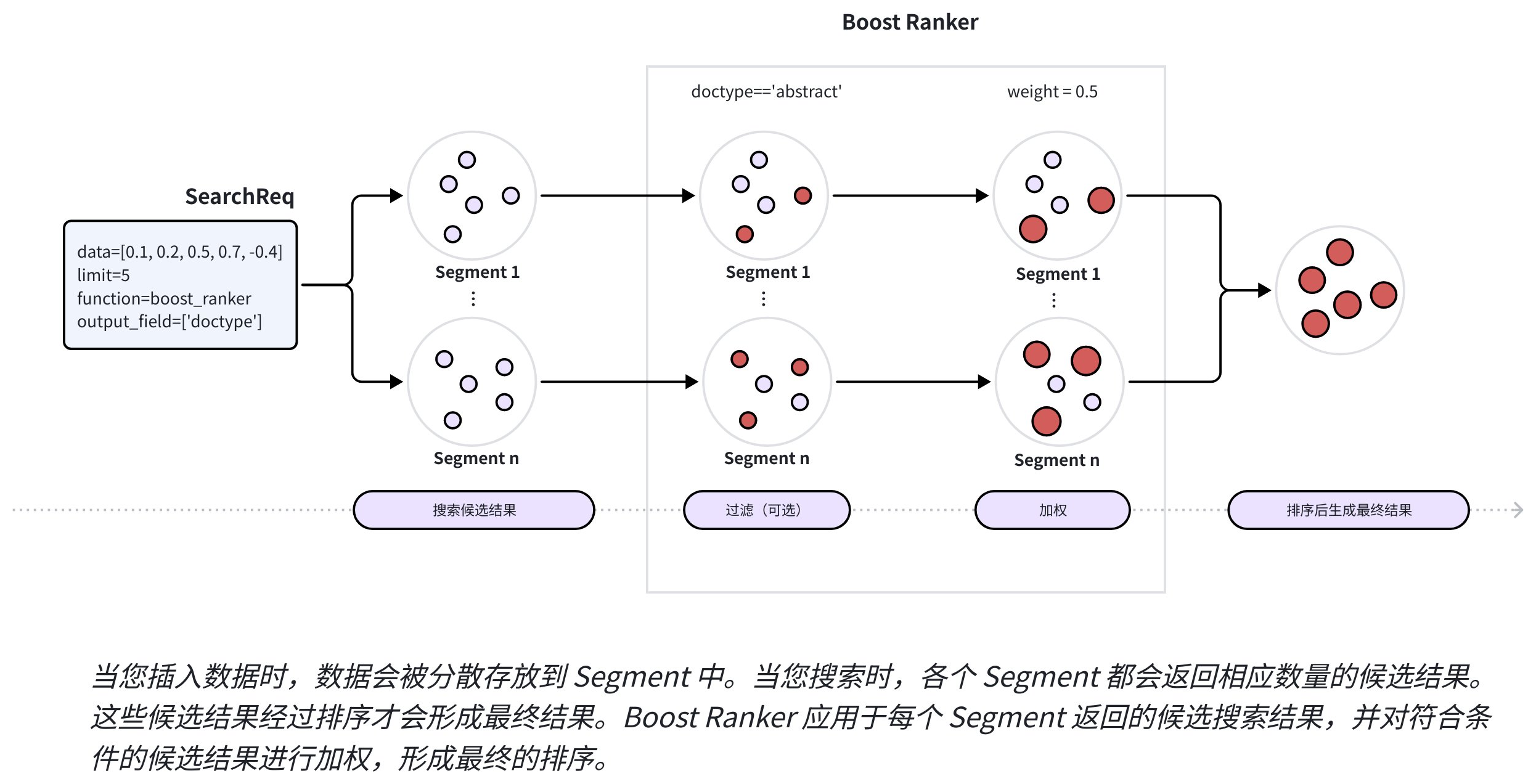
当你插入数据时,Zilliz Cloud 会将它们分配到不同的 Segment 中。当你进行搜索时,每个 Segment 都会返回一组指定数量候选结果,Zilliz Cloud 会对所有 Segment 返回的候选结果进行排序,并将其归约为指定数量的最终结果。在接收到携带 Boost Ranker 的搜索请求时,Zilliz Cloud 会将 Boost Ranker 应用于每个 Segment 返回的候选搜索结果,以防止可能的精度损失并提高召回率。
在最终确定结果之前,Zilliz Cloud 会使用 Boost Ranker 对这些候选结果进行如下处理:
-
应用在 Boost Ranker 中指定的可选过滤表达式,以识别与该表达式匹配的 Entity。
-
应用 Boost Ranker 中指定的权重来提升已识别 Entity 的得分。
暂时不支持将 Boost Ranker 用于多向量混合搜索(Hybrid Search)中多路结果的重排。
Boost Ranker 示例
以下示例展示了在单向量搜索中使用 Boost Ranker 的情况,该搜索需要返回前五个最相关的实体,并为具有摘要文档类型的实体的得分添加权重。
-
分阶段收集搜索结果候选对象。
下表假设 Milvus 将实体分配到两个段(0001 和 0002)中,每个段返回五个候选实体。
ID
Doc Type
得分
排名
段
117
Abstract
0.344
1
0001
89
Abstract
0.456
2
0001
257
Body
0.578
3
0001
358
Title
0.788
4
0001
168
Body
0.899
5
0001
46
Body
0.189
1
0002
48
Body
0265
2
0002
561
Abstract
0.366
3
0002
344
Abstract
0.444
4
0002
276
Abstract
0.845
5
0002
-
应用在Boost Ranker中指定的过滤表达式(
doctype='abstract')。如以下表格中的
DocType字段所示,Milvus 会标记所有doctype为abstract的 Entity,以便进一步处理。ID
Doc Type
得分
排名
段
117
Abstract
0.344
1
0001
89
Abstract
0.456
2
0001
257
Body
0.578
3
0001
358
Title
0.788
4
0001
168
Body
0.899
5
0001
46
Body
0.189
1
0002
48
Body
0265
2
0002
561
Abstract
0.366
3
0002
344
Abstract
0.444
4
0002
276
Abstract
0.845
5
0002
-
应用在Boost Ranker中指定的权重(
权重=0.5)。上一步中所有已识别的实体都将乘以提升排名器中指定的权重,从而导致其排名发生变化。
ID
Doc Type
得分
加权分数
(=得分×权重)
排名
段
117
Abstract
0.344
0.172
1
0001
89
Abstract
0.456
0.228
2
0001
257
Body
0.578
0.578
3
0001
358
Title
0.788
0.788
4
0001
168
Body
0.899
0.899
5
0001
561
Abstract
0.366
0.183
1
0002
46
Body
0.189
0.189
2
0002
344
Abstract
0.444
0.222
3
0002
48
Body
0.265
0.265
4
0002
276
Abstract
0.845
0.423
5
0002
📘注释权重必须是你选择的一个浮点数。在像上述示例这样的情况下,分数越小表示相关性越高,使用小于1的权重。否则,使用大于1的权重。
-
根据加权分数汇总所有细分市场的候选人,以确定最终结果。
ID
Doc Type
得分
加权得分
排名
段
117
Abstract
0.344
0.172
1
0001
561
Abstract
0.366
0.183
2
0002
46
Body
0.189
0.189
3
0002
344
Abstract
0.444
0.222
4
0002
89
Abstract
0.456
0.228
5
0001
使用 Boost Ranker
在本节中,您将看到如何使用Boost Ranker影响单向量搜索结果的示例。
创建一个 Boost Ranker
在将 Boost Ranker 作为搜索请求的重排器传递之前,您应该按照以下方式将 Boost Ranker 正确定义为重排函数:
- Python
- Java
- Go
- NodeJS
- cURL
from pymilvus import Function, FunctionType
rerank = Function(
name="boost",
input_field_names=[], # Must be an empty list
function_type=FunctionType.RERANK,
params={
"reranker": "boost",
"filter": "doctype == 'abstract'",
"random_score": {
"seed": 126,
"field": "id"
},
"weight": 0.5
}
)
import io.milvus.v2.service.vector.request.ranker.BoostRanker;
BoostRanker rerank = BoostRanker.builder()
.name("boost")
.filter("doctype == \"abstract\"")
.weight(5.0f)
.randomScoreField("id")
.randomScoreSeed(126)
.build();
// go
import {FunctionType} from '@zilliz/milvus2-sdk-node';
const rerank = {
name: "boost",
input_field_names: [],
type: FunctionType.RERANK,
params: {
reranker: "boost",
filter: "doctype == 'abstract'",
random_score: {
seed: 126,
field: "id",
},
weight: 0.5,
},
};
# restful
参数 | 必选? | 描述 | 值/示例 |
|---|---|---|---|
| 是 | 此函数的唯一标识符 |
|
| 是 | 要应用该函数的向量字段列表(对于RRF排序器必须为空) |
|
| 是 | 要调用的函数类型;使用 |
|
| 是 | 指定重排器的类型。 必须设置为 |
|
| 是 | 指定将与原始搜索结果中任何匹配实体的得分相乘的权重。 该值应为浮点数。
|
|
| 否 | 指定用于在搜索结果实体中匹配实体的筛选表达式。它可以是过滤表达式概览中提到的任何有效基本筛选表达式。 注意:仅使用基本运算符,例如 |
|
| 否 | 指定一个随机函数,该函数会随机生成一个介于
|
|
使用单个 Boost Ranker 进行搜索
一旦Boost Ranker函数准备就绪,您就可以在搜索请求中引用它。以下示例假设您已经创建了一个包含以下字段的集合:id、vector和doctype。
- Python
- Java
- Go
- NodeJS
- cURL
from pymilvus import MilvusClient
# Connect to the Milvus server
client = MilvusClient(
uri="https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530",
token="YOUR_CLUSTER_TOKEN"
)
# Assume you have a collection set up
# Conduct a similarity search using the created ranker
client.search(
collection_name="my_collection",
data=[[-0.619954382375778, 0.4479436794798608, -0.17493894838751745, -0.4248030059917294, -0.8648452746018911]],
anns_field="vector",
params={},
output_field=["doctype"],
ranker=rerank
)
import io.milvus.v2.client.ConnectConfig;
import io.milvus.v2.client.MilvusClientV2;
import io.milvus.v2.service.vector.request.SearchReq;
import io.milvus.v2.service.vector.response.SearchResp;
import io.milvus.v2.service.vector.request.data.FloatVec;
MilvusClientV2 client = new MilvusClientV2(ConnectConfig.builder()
.uri("https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530")
.token("YOUR_CLUSTER_TOKEN")
.build());
SearchResp searchReq = client.search(SearchReq.builder()
.collectionName("my_collection")
.data(Collections.singletonList(new FloatVec(new float[]{-0.619954f, 0.447943f, -0.174938f, -0.424803f, -0.864845f})))
.annsField("vector")
.outputFields(Collections.singletonList("doctype"))
.functionScore(FunctionScore.builder()
.addFunction(rerank)
.build())
.build());
SearchResp searchResp = client.search(searchReq);
// go
import { MilvusClient } from '@zilliz/milvus2-sdk-node';
// Connect to the Milvus server
const client = new MilvusClient({
address: 'https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530',
token: 'YOUR_CLUSTER_TOKEN'
});
// Assume you have a collection set up
// Conduct a similarity search
const searchResults = await client.search({
collection_name: 'my_collection',
data: [-0.619954382375778, 0.4479436794798608, -0.17493894838751745, -0.4248030059917294, -0.8648452746018911],
anns_field: 'vector',
output_fields: ['doctype'],
rerank: rerank,
});
console.log('Search results:', searchResults);
# restful
使用多个 Boost Ranker 进行搜索
您可以在单个搜索中组合多个 Boost Ranker,以影响搜索结果。为此,您可以创建多个 Boost Ranker,并在 FunctionScore 实例中引用它们,并将 FunctionScore 实例用作搜索请求中的 Ranker。
以下示例展示了如何通过应用介于 0.8 和 1.2 之间的权重来修改所有已识别实体的分数。
- Python
- Java
- Go
- NodeJS
- cURL
from pymilvus import MilvusClient, Function, FunctionType, FunctionScore
# Create a Boost Ranker with a fixed weight
fix_weight_ranker = Function(
name="boost",
input_field_names=[], # Must be an empty list
function_type=FunctionType.RERANK,
params={
"reranker": "boost",
"weight": 0.8
}
)
# Create a Boost Ranker with a randomly generated weight between 0 and 0.4
random_weight_ranker = Function(
name="boost",
input_field_names=[], # Must be an empty list
function_type=FunctionType.RERANK,
params={
"reranker": "boost",
"random_score": {
"seed": 126,
},
"weight": 0.4
}
)
# Create a Function Score
ranker = FunctionScore(
functions=[
fix_weight_ranker,
random_weight_ranker
],
params={
"boost_mode": "Multiply",
"function_mode": "Sum"
}
)
# Conduct a similarity search using the created Function Score
client.search(
collection_name="my_collection",
data=[[-0.619954382375778, 0.4479436794798608, -0.17493894838751745, -0.4248030059917294, -0.8648452746018911]],
anns_field="vector",
params={},
output_field=["doctype"],
ranker=ranker
)
import io.milvus.common.clientenum.FunctionType;
import io.milvus.v2.service.collection.request.CreateCollectionReq;
CreateCollectionReq.Function fixWeightRanker = CreateCollectionReq.Function.builder()
.functionType(FunctionType.RERANK)
.name("boost")
.param("reranker", "boost")
.param("weight", "0.8")
.build();
CreateCollectionReq.Function randomWeightRanker = CreateCollectionReq.Function.builder()
.functionType(FunctionType.RERANK)
.name("boost")
.param("reranker", "boost")
.param("weight", "0.4")
.param("random_score", "{\"seed\": 126}")
.build();
Map<String, String> params = new HashMap<>();
params.put("boost_mode","Multiply");
params.put("function_mode","Sum");
FunctionScore ranker = FunctionScore.builder()
.addFunction(fixWeightRanker)
.addFunction(randomWeightRanker)
.params(params)
.build()
SearchResp searchReq = client.search(SearchReq.builder()
.collectionName("my_collection")
.data(Collections.singletonList(new FloatVec(new float[]{-0.619954f, 0.447943f, -0.174938f, -0.424803f, -0.864845f})))
.annsField("vector")
.outputFields(Collections.singletonList("doctype"))
.addFunction(ranker)
.build());
SearchResp searchResp = client.search(searchReq);
// go
import {FunctionType} from '@zilliz/milvus2-sdk-node';
const fix_weight_ranker = {
name: "boost",
input_field_names: [],
type: FunctionType.RERANK,
params: {
reranker: "boost",
weight: 0.8,
},
};
const random_weight_ranker = {
name: "boost",
input_field_names: [],
type: FunctionType.RERANK,
params: {
reranker: "boost",
random_score: {
seed: 126,
},
weight: 0.4,
},
};
const ranker = {
functions: [fix_weight_ranker, random_weight_ranker],
params: {
boost_mode: "Multiply",
function_mode: "Sum",
},
};
await client.search({
collection_name: "my_collection",
data: [[-0.619954382375778, 0.4479436794798608, -0.17493894838751745, -0.4248030059917294, -0.8648452746018911]],
anns_field: "vector",
params: {},
output_field: ["doctype"],
ranker: ranker
});
# restful
具体来说,有两个 Boost Ranker:一个对所有找到的实体应用固定权重,而另一个则为它们分配随机权重。然后,我们在 FunctionScore 中引用这两个 Boost Ranker,该 Ranker 还定义了权重如何影响找到的实体的得分。
下表列出了创建 FunctionScore 实例所需的参数。
参数 | 必填项? | 描述 | 值/示例 |
|---|---|---|---|
| 是 | 以列表形式指定目标 Ranker 的名称。 |
|
| 否 | 指定指定的权重如何影响任何匹配实体的得分。 可能的值为:
|
|
| 否 | 指定如何处理来自各种 Boost Ranker 的加权值。 可能的值为:
|
|