最佳实践:如何选择合适的 Analyzer
本指南侧重于 Analyzer 选择的实际决策方法。关于 Analyzer 组件的技术细节以及如何添加 Analyzer 参数,请参考 Analyzer 概述。
快速了解 Analyzer
在 Zilliz Cloud 中,Analyzer 会处理存储在字段中的文本,使其可用于 Full Text Search(BM25)、Phrase Match 或 Text Match。可以将它视作一个文本处理器,把原始内容转化为可搜索的 token。一个 Analyzer 的工作分为两个阶段:
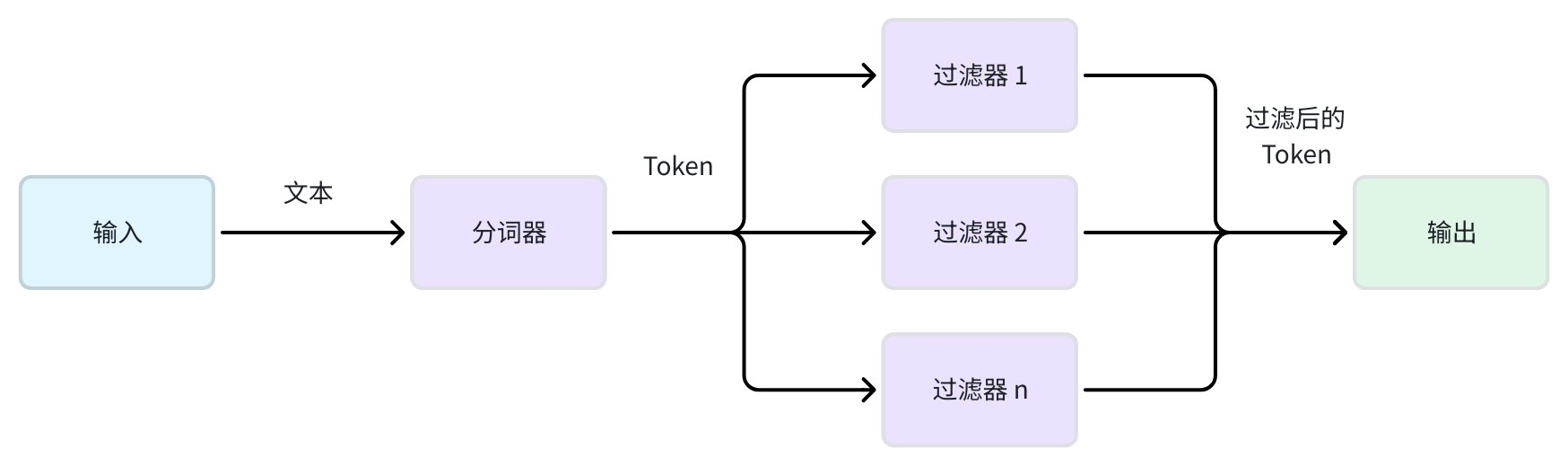
-
分词 (Tokenization, 必需):通过 tokenizer 将连续的文本拆分为独立且有意义的 token。不同语言和内容类型的分词方式差异很大。
-
Token 过滤 (可选):在分词后应用过滤器,用于修改、删除或优化 token。例如,将所有 token 转换为小写、去掉常见停用词,或将单词还原为词根。
示例:
输入: "Hello World!"
1. 分词 → ["Hello", "World", "!"]
2. 小写与标点过滤 → ["hello", "world"]
为什么选择合适的 Analyzer 很重要
选择不当的 Analyzer 可能导致相关文档无法被搜索到,或返回无关结果。
下表总结了因错误选择 Analyzer 而导致的常见问题,并提供了可操作的解决方案:
问题 | 症状 | 示例 | 错误原因 | 解决方案 |
|---|---|---|---|---|
过度分词 | 技术术语、标识符或 URL 搜索不到 |
| standard Analyzer | 使用 whitespace tokenizer 并结合 alphanumonly 过滤器 |
分词不足 | 多词短语的一部分无法匹配完整短语 |
| 使用 whitespace tokenizer | |
语言不匹配 | 特定语言搜索无效或结果异常 |
| 使用 english Analyzer | 使用特定语言的 Analyzer,如 Chinese |
第一步:你是否需要选择 Analyzer?
如果未指定 Analyzer,在使用全文检索等功能时,Zilliz Cloud 会自动应用 **standard** Analyzer。
它会:
-
按空格和标点分词
-
将所有 token 转为小写
-
移除内置的常见英文停用词和大多数标点
示例:
输入: "The Milvus vector database is built for scale!"
输出: ['the', 'milvus', 'vector', 'database', 'is', 'built', 'scale']
第二步:判断 Standard Analyzer 是否满足业务需求
使用下表快速判断默认的 Standard Analyzer 是否满足你的需求。如果不满足,你需要通过不同路径选择其他 Analyzer。
内容 | standard Analyzer 是否合适? | 原因 | 需要什么 |
|---|---|---|---|
英文博客 | ✅ 是 | 默认即可 | 使用默认 |
中文文档 | ❌ 否 | 中文无空格,整段视作单 token | 使用内置 chinese Analyzer |
技术文档 | ❌ 否 | 符号丢失,如 C++ → C | 使用 whitespace tokenizer + alphanumonly filter |
法语/西班牙语 | ⚠️ 可能 | café 与 cafe 不匹配 | 使用 asciifolding filter |
多语言或未知语言 | ❌ 否 | standard 无法处理不同字符集 | 使用 icu tokenizer 或多语言方案 |
第三步:通过不同路径选择 Analyzer
如果默认的标准分析器无法满足需求,请选择以下两种路径之一:
-
路径 A:使用内置 Analyzer(开箱即用的语言专用 Analyzer)
-
路径 B:创建自定义 Analyzer(手动定义 Tokenizer 和一组 Filter)
路径 A:使用内置 Analyzer
内置 Analyzer 是预配置方案,适合常见语言。
可选内置 Analyzer
Analyzer | 语言支持 | 组件 | 说明 |
|---|---|---|---|
英语/法语/西班牙语等 |
| 通用方案 | |
英语 |
| 英语专用,推荐 | |
中文 |
| 默认简体字典 |
示例
# Using built-in English analyzer
analyzer_params = {
"type": "english"
}
# Applying analyzer config to target VARCHAR field in your collection schema
schema.add_field(
field_name='text',
datatype=DataType.VARCHAR,
max_length=200,
enable_analyzer=True,
# highlight-next-line
analyzer_params=analyzer_params,
)
路径 B:创建自定义 Analyzer
当内置选项不足时,可以通过 tokenizer + filter 自由组合。
步骤 1:选择 tokenizer
根据语言选择合适的 tokenizer:
西方语言
对于通过空格分隔的语言,有以下选择:
Tokenizer | 工作原理 | 适用场景 | 示例 |
|---|---|---|---|
基于空格和标点拆分文本 | 通用文本,包含混合标点的内容 |
| |
仅基于空格字符拆分 | 已预处理的内容,用户自定义格式的文本 |
|
东亚语言
基于词典的语言需要专用的 tokenizer 才能进行正确的分词:
中文
Tokenizer | 工作原理 | 适用场景 | 示例 |
|---|---|---|---|
基于中文词典的分词,结合智能算法 | 推荐用于中文内容——结合词典与智能算法,专为中文设计 |
| |
纯词典驱动的中文形态学分析(使用 cc-cedict 词典) | 为日韩分词设计,也可用于分词中文,但性能不如 jieba |
|
日语和韩语
Tokenizer | 工作原理 | 适用场景 | 示例 | Examples |
|---|---|---|---|---|
Japanese | ipadic (通用), ipadic-neologd (现代词汇), unidic (学术) | 形态学分析,支持专有名词处理 |
| |
Korean | 韩语形态学分析 |
|
多语言或未知语言
适用于文档中语言不可预测或混合的情况:
Tokenizer | 工作原理 | 适用场景 | 示例 | Examples |
|---|---|---|---|---|
基于 Unicode 的分词(ICU - International Components for Unicode) | 混合文字、未知语言,或只需简单分词时 |
|
icu 的使用场景:
-
内容包含混合语言,且语言识别不可行。
-
不希望使用多语言 Analyzer 或 language identifier 带来的额外开销。
-
文本以某一主语言为主,夹杂少量外语单词,这些外语对整体语义影响不大(如英文文本中偶尔出现日语/法语品牌名或技术术语)。
替代方案:如果需要更精确地处理多语言内容,建议使用 多语言 Analyzer 或 Language Identifier。
步骤 2:添加过滤器以提高精度
在选择好 tokenizer 之后,根据你的具体搜索需求和内容特性应用过滤器。
常用过滤器
这些过滤器在大多数以空格分隔的语言(英语、法语、德语、西班牙语等)中至关重要,并能显著提升搜索质量:
Filter | 工作原理 | 使用场景 | 示例 |
|---|---|---|---|
将所有 token 转换为小写 | 通用——适用于所有区分大小写的语言 |
| |
将单词还原为词根 | 适用于有词形变化的语言(英语、法语、德语等) | 英语示例:
| |
移除常见的无意义词(停用词) | 大多数语言,尤其是空格分隔的语言 |
|
对于东亚语言(中文、日语、韩语等),请重点使用语言特定的过滤器。这些语言的文本处理方式不同,通常不需要或无法从词干提取中获益。
文本规范化过滤器
这些过滤器用于标准化文本差异,提高匹配一致性:
Filter | 工作原理 | 使用场景 | 示例 |
|---|---|---|---|
将带重音符的字符转换为 ASCII 等效字符 | 国际化内容、用户生成内容 |
|
Token 过滤
这些过滤器控制哪些 token 会被保留,通常基于字符类型或长度:
Filter | 工作原理 | 使用场景 | 示例 |
|---|---|---|---|
移除单独存在的标点 token | 清理 |
| |
仅保留字母和数字 | 技术类内容、干净的文本处理 |
| |
移除超出指定长度范围的 token | 过滤噪声(如过长的 token) |
| |
基于自定义模式的过滤 | 特定领域的 token 需求 |
|
语言特定过滤器
Filter | Language | How It Works | Examples |
|---|---|---|---|
德语 | 将复合词拆分为可搜索的组成部分 |
| |
中文 | 保留中文字符 + 字母数字 |
| |
中文 | 仅保留中文字符 |
|
步骤 3:组合并实现
要创建自定义 Analyzer,需要在 analyzer_params 字典中定义 tokenizer 和过滤器列表。
这些过滤器会按照定义的顺序依次应用。
# Example: A custom analyzer for technical content
analyzer_params = {
"tokenizer": "whitespace",
"filter": ["lowercase", "alphanumonly"]
}
# Applying analyzer config to target VARCHAR field in your collection schema
schema.add_field(
field_name='text',
datatype=DataType.VARCHAR,
max_length=200,
enable_analyzer=True,
# highlight-next-line
analyzer_params=analyzer_params,
)
最终步骤:使用 run_analyzer 进行测试
在将配置应用到 Collection 之前,务必先验证:
# Sample text to analyze
sample_text = "The Milvus vector database is built for scale!"
# Run analyzer with the defined configuration
result = client.run_analyzer(sample_text, analyzer_params)
print("Analyzer output:", result)
需要检查的常见问题
-
过度分词:技术术语被错误拆分
-
分词不足:短语未被正确拆分
-
token 丢失:重要词被过滤掉
更多用法请参考 run_analyzer。
按使用场景推荐的配置
本节为在 Zilliz Cloud 中使用 Analyzer 时的常见场景,提供推荐的 tokenizer 与 filter 组合。请选择最适合你内容类型和搜索需求的配置。
在将 Analyzer 应用到 Collection 前,建议先使用 run_analyzer 来测试和验证文本分析效果。
英文
analyzer_params = {
"tokenizer": "standard",
"filter": [
"lowercase",
{
"type": "stemmer",
"language": "english"
},
{
"type": "stop",
"stop_words": [
"_english_"
]
}
]
}
中文
{
"tokenizer": "jieba",
"filter": ["cnalphanumonly"]
}
阿拉伯语
{
"tokenizer": "standard",
"filter": [
"lowercase",
{
"type": "stemmer",
"language": "arabic"
}
]
}
孟加拉语
{
"tokenizer": "icu",
"filter": ["lowercase", {
"type": "stop",
"stop_words": [<put stop words list here>]
}]
}
法语
{
"tokenizer": "standard",
"filter": [
"lowercase",
{
"type": "stemmer",
"language": "french"
},
{
"type": "stop",
"stop_words": [
"_french_"
]
}
]
}
德语
{
"tokenizer": {
"type": "lindera",
"dict_kind": "ipadic"
},
"filter": [
"removepunct"
]
}
印度语
{
"tokenizer": "icu",
"filter": ["lowercase", {
"type": "stop",
"stop_words": [<put stop words list here>]
}]
}
韩语
{
"tokenizer": {
"type": "lindera",
"dict_kind": "ko-dic",
"filter": [
{
"kind": "korean_stop_tags",
"tags": ["SP", "SSC", "SSO", "SC", "SE", "SF", "JKS", "JKC", "JKG", "JKO", "JKB", "JKV", "JKQ", "JX", "JC", "UNK", "EP", "ETM"]
}
]
}
}
日语
{
"tokenizer": {
"type": "lindera",
"dict_kind": "ipadic"
},
"filter": [
"removepunct"
]
}
葡萄牙语
{
"tokenizer": "standard",
"filter": [
"lowercase",
{
"type": "stemmer",
"language": "portuguese"
},
{
"type": "stop",
"stop_words": [
"_portuguese_"
]
}
]
}
俄语
{
"tokenizer": "standard",
"filter": [
"lowercase",
{
"type": "stemmer",
"language": "russian"
},
{
"type": "stop",
"stop_words": [
"_russian_"
]
}
]
}
西班牙语
{
"tokenizer": "standard",
"filter": [
"lowercase",
{
"type": "stemmer",
"language": "spanish"
},
{
"type": "stop",
"stop_words": [
"_spanish_"
]
}
]
}
斯瓦希里语
{
"tokenizer": "standard",
"filter": ["lowercase", {
"type": "stop",
"stop_words": [<put stop words list here>]
}]
}
土耳其语
{
"tokenizer": "standard",
"filter": [
"lowercase",
{
"type": "stemmer",
"language": "turkish"
}
]
}
乌尔都语
{
"tokenizer": "icu",
"filter": ["lowercase", {
"type": "stop",
"stop_words": [<put stop words list here>]
}]
}
混合或多语言内容
当处理跨多种语言或文字体系不可预测的内容时,建议使用 icu analyzer。 该 Analyzer 具备 Unicode 识别能力,能有效处理混合文字和符号。
基础多语言配置(不包含词干提取):
analyzer_params = {
"tokenizer": "icu",
"filter": ["lowercase", "asciifolding"]
}
高级多语言处理:
-
使用 multi-language analyzer 配置。详情参见多语言 Analyzer。
-
在内容中实现 language identifier。详情参见 Language Identifier。
在 Zilliz Cloud 配置和预览 Analyzer
你可以直接在 Zilliz Cloud 控制台中配置和测试 Analyzer,而无需编写代码。具体可参考如下演示。