Full Text Search
在 Zilliz Cloud 中,Full Text Search 是对基于稠密向量的语义搜索的补充。它能够在大规模文本集合中查找包含特定术语或短语的文本,弥补语义搜索的遗漏,从而提升整体搜索效果。它支持直接插入和使用原始文本数据进行相似性搜索,Milvus 会自动将文本转换为稀疏向量表示。Full Text Search 使用 BM25 算法进行相关性评分,根据查询文本返回最相关的文档,从而提高文本搜索的整体精度。
该功能适用于需要精准术语匹配的相关性搜索场景,如电商中检索产品序列号、客户支持中的工单跟踪,以及法律或医学数据库中的特定术语查找。
将 Full Text Search 与基于语义的稠密向量搜索结合使用,可以提升搜索结果的准确性和相关性。更多信息请参考 Hybrid Search。
Zilliz Cloud 支持通过代码或通过 Web 控制台开启 Full Text Search 功能。本文着重介绍如何通过代码开启 Full Text Search,如需了解 Web 控制台操作,请参考管理 Collection (控制台)。
概述
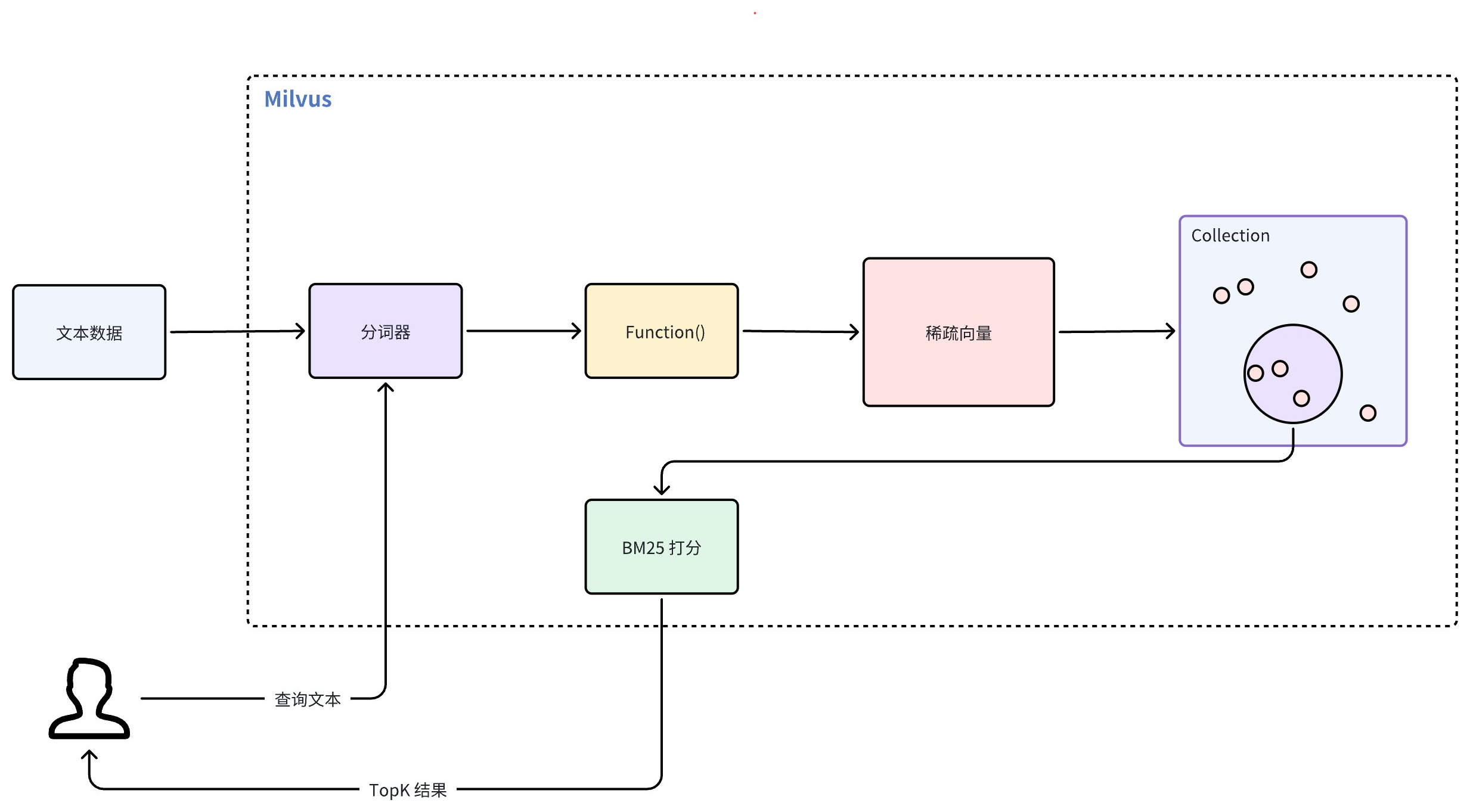
Full Text Search 简化了基于文本数据的搜索流程,无需您提前将数据转换为向量。其工作流程如下:
-
文本输入:直接插入原始文本文档或提供查询文本,无需手动生成向量。
-
分词:Milvus 使用分词器(Tokenizer)将输入文本分割成独立的、可搜索的词语。
-
Function 处理:内置 Function 接收分词结果并将其转换为稀疏向量表示。
-
Collection 存储:Milvus 将这些稀疏向量存储在 Collection 中,以便高效检索。
-
BM25 评分:在搜索过程中,Milvus 使用 BM25 算法计算文档得分,并根据查询文本的相关性对匹配结果进行排序。
要使用 Full Text Search,主要有以下几个步骤:
-
创建 Collection:设置包含必要字段的 Collection,并定义一个将原始文本转换为稀疏向量的 Function。
-
插入数据:将原始文本文档导入 Collection。
-
执行搜索:使用查询文本搜索 Collection,并获取相关结果。
创建 Collection
要启用 Full Text Search,需要创建一个包含特定 Schema 的 Collection。Schema 必须包含以下三个关键字段:
-
主键字段:用于唯一标识 Collection 中的每个 Entity。
-
VARCHAR 字段:用于存储原始文本文档,并设置
enable_analyzer=True以使 Milvus 能够对文本进行分词处理。 -
SPARSE_FLOAT_VECTOR 字段:用于存储稀疏向量,Milvus 会自动为
VARCHAR字段生成这些向量。
定义 Collection Schema
首先,创建 Schema 并添加必要字段:
- Python
- Java
- Go
- NodeJS
- cURL
from pymilvus import MilvusClient, DataType, Function, FunctionType
client = MilvusClient(
uri="https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530",
token="YOUR_CLUSTER_TOKEN"
)
schema = client.create_schema()
schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True, auto_id=True) # Primary field
# highlight-start
schema.add_field(field_name="text", datatype=DataType.VARCHAR, max_length=1000, enable_analyzer=True) # Text field
schema.add_field(field_name="sparse", datatype=DataType.SPARSE_FLOAT_VECTOR) # Sparse vector field; no dim required for sparse vectors
# highlight-end
import io.milvus.v2.common.DataType;
import io.milvus.v2.service.collection.request.AddFieldReq;
import io.milvus.v2.service.collection.request.CreateCollectionReq;
CreateCollectionReq.CollectionSchema schema = CreateCollectionReq.CollectionSchema.builder()
.build();
schema.addField(AddFieldReq.builder()
.fieldName("id")
.dataType(DataType.Int64)
.isPrimaryKey(true)
.autoID(true)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("text")
.dataType(DataType.VarChar)
.maxLength(1000)
.enableAnalyzer(true)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("sparse")
.dataType(DataType.SparseFloatVector)
.build());
import (
"context"
"fmt"
"github.com/milvus-io/milvus/client/v2/column"
"github.com/milvus-io/milvus/client/v2/entity"
"github.com/milvus-io/milvus/client/v2/index"
"github.com/milvus-io/milvus/client/v2/milvusclient"
)
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
milvusAddr := "https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530"
token := "YOUR_CLUSTER_TOKEN"
client, err := milvusclient.New(ctx, &milvusclient.ClientConfig{
Address: milvusAddr,
APIKey: token
})
if err != nil {
fmt.Println(err.Error())
// handle error
}
defer client.Close(ctx)
schema := entity.NewSchema()
schema.WithField(entity.NewField().
WithName("id").
WithDataType(entity.FieldTypeInt64).
WithIsPrimaryKey(true).
WithIsAutoID(true),
).WithField(entity.NewField().
WithName("text").
WithDataType(entity.FieldTypeVarChar).
WithEnableAnalyzer(true).
WithMaxLength(1000),
).WithField(entity.NewField().
WithName("sparse").
WithDataType(entity.FieldTypeSparseVector),
)
import { MilvusClient, DataType } from "@zilliz/milvus2-sdk-node";
const address = "https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530";
const token = "YOUR_CLUSTER_TOKEN";
const client = new MilvusClient({address, token});
const schema = [
{
name: "id",
data_type: DataType.Int64,
is_primary_key: true,
},
{
name: "text",
data_type: "VarChar",
enable_analyzer: true,
enable_match: true,
max_length: 1000,
},
{
name: "sparse",
data_type: DataType.SparseFloatVector,
},
];
console.log(res.results)
export schema='{
"autoId": true,
"enabledDynamicField": false,
"fields": [
{
"fieldName": "id",
"dataType": "Int64",
"isPrimary": true
},
{
"fieldName": "text",
"dataType": "VarChar",
"elementTypeParams": {
"max_length": 1000,
"enable_analyzer": true
}
},
{
"fieldName": "sparse",
"dataType": "SparseFloatVector"
}
]
}'
在此配置中:
-
id:作为主键,并通过auto_id=True自动生成。 -
text:用于存储原始文本数据以进行 Full Text Search 操作。数据类型必须为VARCHAR,因为这是 Zilliz Cloud 的文本存储类型。设置enable_analyzer=True以允许 Zilliz Cloud 对文本进行分词。默认情况下,Milvus 使用
defaultAnalyzer 进行分词。对于中文文本,可以考虑使用内置的 Chinese Analyzer。也可以根据需要配置多语言 Analyzer。在使用非默认的 Analyzer 时,需要在创建字段时指定
analyzer_params参数。以此处的text为例,可以参考如下示例使用内置的 Chinese Analayzer。- Python
- Java
- NodeJS
- Go
- cURL
analyzer_params = {"tokenizer": "jieba","filter": ["cnalphanumonly"]}Map<String, Object> analyzerParams = new HashMap<>();analyzerParams.put("tokenizer", "jieba");analyzerParams.put("filter", Collections.singletonList("cnalphanumonly"));const analyzer_params = {"tokenizer": "jieba","filter": ["cnalphanumonly"]};analyzerParams = map[string]any{"tokenizer": "jieba", "filter": []any{"cnalphanumonly"}}# restfulanalyzerParams='{"tokenizer": "jieba","filter": ["cnalphanumonly"]}'并在
text字段的 Schema 中引用。- Python
- Java
- NodeJS
- Go
- cURL
schema.add_field(field_name="text",datatype=DataType.VARCHAR,max_length=1000,analyzer_params=analyzer_params,enable_analyzer=True)schema.addField(AddFieldReq.builder().fieldName("text").dataType(DataType.VarChar).maxLength(1000).analyzerParams(analyzerParams).enableAnalyzer(true).build());const schema = [{...},{name: "text",data_type: "VarChar",analyzer_params: analyzer_params,enable_analyzer: true,enable_match: true,max_length: 1000,},{...}]schema := entity.NewSchema()schema.WithField(...,).WithField(entity.NewField().WithName("text").WithDataType(entity.FieldTypeVarChar).WithEnableAnalyzer(true).WithMaxLength(1000),).WithField(...,)textField='{"fieldName": "text","dataType": "VarChar","elementTypeParams": {"max_length": 1000,"analyzer_params": '$analyzerParams',"enable_analyzer": true}}'针对多语言混用的文本及 Analyzer 的最佳实践,可以参考最佳实践:如何选择合适的 Analyzer。
-
sparse:向量字段,用于存储 Milvus 为文本数据生成的稀疏向量表示。数据类型必须为SPARSE_FLOAT_VECTOR。
然后,创建一个将文本转换为稀疏向量的 Function,并将其添加到 Schema 中:
- Python
- Java
- Go
- NodeJS
- cURL
bm25_function = Function(
name="text_bm25_emb", # Function name
input_field_names=["text"], # Name of the VARCHAR field containing raw text data
output_field_names=["sparse"], # Name of the SPARSE_FLOAT_VECTOR field reserved to store generated embeddings
# highlight-next-line
function_type=FunctionType.BM25, # Set to \`BM25\`
)
schema.add_function(bm25_function)
import io.milvus.common.clientenum.FunctionType;
import io.milvus.v2.service.collection.request.CreateCollectionReq.Function;
import java.util.*;
schema.addFunction(Function.builder()
.functionType(FunctionType.BM25)
.name("text_bm25_emb")
.inputFieldNames(Collections.singletonList("text"))
.outputFieldNames(Collections.singletonList("sparse"))
.build());
function := entity.NewFunction().
WithName("text_bm25_emb").
WithInputFields("text").
WithOutputFields("sparse").
WithType(entity.FunctionTypeBM25)
schema.WithFunction(function)
const functions = [
{
name: 'text_bm25_emb',
description: 'bm25 function',
type: FunctionType.BM25,
input_field_names: ['text'],
output_field_names: ['sparse'],
params: {},
},
];
export schema='{
"autoId": true,
"enabledDynamicField": false,
"fields": [
{
"fieldName": "id",
"dataType": "Int64",
"isPrimary": true
},
{
"fieldName": "text",
"dataType": "VarChar",
"elementTypeParams": {
"max_length": 1000,
"enable_analyzer": true
}
},
{
"fieldName": "sparse",
"dataType": "SparseFloatVector"
}
],
"functions": [
{
"name": "text_bm25_emb",
"type": "BM25",
"inputFieldNames": ["text"],
"outputFieldNames": ["sparse"],
"params": {}
}
]
}'
参数 | 描述 |
|---|---|
| Function 的名称。该 Function 将 |
| 需要进行文本到稀疏向量转换的 |
| 用于存储 Milvus 内部自动生成的稀疏向量的字段名称。 |
| 使用的 Function 类型。设置为 |
对于包含多个需要进行文本到稀疏向量转换的 VARCHAR 字段的 Collection,请为 Schema 添加单独的 Function,并确保每个 Function 具有唯一的名称和 output_field_names 值。
配置索引参数
在定义包含必要字段和内置 Function 的 Schema 后,需要为 Collection 设置向量索引以加速查询。本例中使用 AUTOINDEX 作为 index_type,表示让 Zilliz Cloud 根据数据结构自动选择和配置最适合的索引类型。
- Python
- Java
- Go
- NodeJS
- cURL
index_params = client.prepare_index_params()
index_params.add_index(
field_name="sparse",
index_type="AUTOINDEX",
metric_type="BM25"
)
import io.milvus.v2.common.IndexParam;
Map<String,Object> params = new HashMap<>();
params.put("inverted_index_algo", "DAAT_MAXSCORE");
params.put("bm25_k1", 1.2);
params.put("bm25_b", 0.75);
List<IndexParam> indexes = new ArrayList<>();
indexes.add(IndexParam.builder()
.fieldName("sparse")
.indexType(IndexParam.IndexType.AUTOINDEX)
.metricType(IndexParam.MetricType.BM25)
.extraParams(params)
.build());
indexOption := milvusclient.NewCreateIndexOption("my_collection", "sparse",
index.NewAutoIndex(entity.MetricType(entity.BM25)))
.WithExtraParam("inverted_index_algo", "DAAT_MAXSCORE")
.WithExtraParam("bm25_k1", 1.2)
.WithExtraParam("bm25_b", 0.75)
const index_params = [
{
field_name: "sparse",
metric_type: "BM25",
index_type: "SPARSE_INVERTED_INDEX",
params: {
"inverted_index_algo": "DAAT_MAXSCORE",
"bm25_k1": 1.2,
"bm25_b": 0.75
}
},
];
export indexParams='[
{
"fieldName": "sparse",
"metricType": "BM25",
"indexType": "AUTOINDEX",
"params":{
"inverted_index_algo": "DAAT_MAXSCORE",
"bm25_k1": 1.2,
"bm25_b": 0.75
}
}
]'
参数 | 描述 |
|---|---|
| 要索引的向量字段名称。对于 Full Text Search,应设置为存储稀疏向量的字段,在本例中为 |
| 要创建的索引类型。 |
| 设置为 |
| 特定于索引的附加参数字典。 |
| 用于构建和查询索引的算法。有效值:
|
| 控制词频饱和度。较高的值会增加词频在文档排名中的重要性。取值范围:[1.2, 2.0]。 |
| 控制文档长度归一化的程度。通常使用 0 到 1 之间的值,常见的默认值约为0.75。值为 1 表示不进行长度归一化,而值为 0 表示完全归一化。 |
创建 Collection
使用定义的 Schema 和索引参数创建 Collection:
- Python
- Java
- Go
- NodeJS
- cURL
client.create_collection(
collection_name='my_collection',
schema=schema,
index_params=index_params
)
import io.milvus.v2.service.collection.request.CreateCollectionReq;
CreateCollectionReq requestCreate = CreateCollectionReq.builder()
.collectionName("my_collection")
.collectionSchema(schema)
.indexParams(indexes)
.build();
client.createCollection(requestCreate);
err = client.CreateCollection(ctx,
milvusclient.NewCreateCollectionOption("my_collection", schema).
WithIndexOptions(indexOption))
if err != nil {
fmt.Println(err.Error())
// handle error
}
await client.create_collection(
collection_name: 'my_collection',
schema: schema,
index_params: index_params,
functions: functions
);
export CLUSTER_ENDPOINT="https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530"
export TOKEN="YOUR_CLUSTER_TOKEN"
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/collections/create" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
-d "{
\"collectionName\": \"my_collection\",
\"schema\": $schema,
\"indexParams\": $indexParams
}"
插入文本数据
在设置好 Collection 和索引后,即可插入文本数据。只需提供原始文本,之前定义的内置 Function 会自动为每条文本生成对应的稀疏向量。
- Python
- Java
- Go
- NodeJS
- cURL
client.insert('my_collection', [
{'text': 'information retrieval is a field of study.'},
{'text': 'information retrieval focuses on finding relevant information in large datasets.'},
{'text': 'data mining and information retrieval overlap in research.'},
])
import com.google.gson.Gson;
import com.google.gson.JsonObject;
import io.milvus.v2.service.vector.request.InsertReq;
Gson gson = new Gson();
List<JsonObject> rows = Arrays.asList(
gson.fromJson("{\"text\": \"information retrieval is a field of study.\"}", JsonObject.class),
gson.fromJson("{\"text\": \"information retrieval focuses on finding relevant information in large datasets.\"}", JsonObject.class),
gson.fromJson("{\"text\": \"data mining and information retrieval overlap in research.\"}", JsonObject.class)
);
client.insert(InsertReq.builder()
.collectionName("my_collection")
.data(rows)
.build());
// go
await client.insert({
collection_name: 'my_collection',
data: [
{'text': 'information retrieval is a field of study.'},
{'text': 'information retrieval focuses on finding relevant information in large datasets.'},
{'text': 'data mining and information retrieval overlap in research.'},
]);
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/insert" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
-d '{
"data": [
{"text": "information retrieval is a field of study."},
{"text": "information retrieval focuses on finding relevant information in large datasets."},
{"text": "data mining and information retrieval overlap in research."}
],
"collectionName": "my_collection"
}'
执行 Full Text Search
在向 Collection 插入数据后,可以使用原始查询文本执行 Full Text Search。Milvus 会自动将查询文本转换为稀疏向量,并使用 BM25 算法对匹配的搜索结果进行相关性排序。
- Python
- Java
- Go
- NodeJS
- cURL
search_params = {
'params': {'level': 10},
}
res = client.search(
collection_name='my_collection',
# highlight-start
data=['whats the focus of information retrieval?'],
anns_field='sparse',
output_fields=['text'], # Fields to return in search results; sparse field cannot be output
# highlight-end
limit=3,
search_params=search_params
)
print(res)
import io.milvus.v2.service.vector.request.SearchReq;
import io.milvus.v2.service.vector.request.data.EmbeddedText;
import io.milvus.v2.service.vector.response.SearchResp;
Map<String,Object> searchParams = new HashMap<>();
searchParams.put("level", 10);
SearchResp searchResp = client.search(SearchReq.builder()
.collectionName("my_collection")
.data(Collections.singletonList(new EmbeddedText("whats the focus of information retrieval?")))
.annsField("sparse")
.topK(3)
.searchParams(searchParams)
.outputFields(Collections.singletonList("text"))
.build());
annSearchParams := index.NewCustomAnnParam()
resultSets, err := client.Search(ctx, milvusclient.NewSearchOption(
"my_collection", // collectionName
3, // limit
[]entity.Vector{entity.Text("whats the focus of information retrieval?")},
).WithConsistencyLevel(entity.ClStrong).
WithANNSField("sparse").
WithAnnParam(annSearchParams).
WithOutputFields("text"))
if err != nil {
fmt.Println(err.Error())
// handle error
}
for _, resultSet := range resultSets {
fmt.Println("IDs: ", resultSet.IDs.FieldData().GetScalars())
fmt.Println("Scores: ", resultSet.Scores)
fmt.Println("text: ", resultSet.GetColumn("text").FieldData().GetScalars())
}
await client.search(
collection_name: 'my_collection',
data: ['whats the focus of information retrieval?'],
anns_field: 'sparse',
output_fields: ['text'],
limit: 3,
params: {'level': 10},
)
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/search" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
--data-raw '{
"collectionName": "my_collection",
"data": [
"whats the focus of information retrieval?"
],
"annsField": "sparse",
"limit": 3,
"outputFields": [
"text"
],
"searchParams":{
"params":{}
}
}'
参数 | 描述 |
|---|---|
| 包含搜索参数的字典。 |
| 使用简化的调优手段控制搜索精度。更多详情,可参考召回调优 |
| 原文查询文本。Zilliz Cloud 使用 BM25 函数自动将查询请求中的文本转换成对应的稀疏向量。因此,请勿提供预算的向量。 |
| 用于存储 Milvus 内部自动生成的稀疏向量的向量字段名称。 |
| 搜索结果中要返回的字段名列表。支持除包含 BM25 生成嵌入的稀疏向量字段之外的所有字段。常见的输出字段包括主键字段(例如 id )和原始文本字段(例如 text )。更多信息请参考 FAQ。 |
| 返回的匹配结果的最大数量。 |
常见问题
在全文搜索中,我能否输出或访问由 BM25 函数生成的稀疏向量?
不行。BM25 函数生成的稀疏向量在全文搜索中无法直接访问或输出。详情如下:
-
BM25 函数在内部生成稀疏向量,用于排序和检索
-
这些向量存储在稀疏字段中,但不能包含在输出字段中
-
你只能输出原始文本字段和元数据(如id、文本)
示例:
# ❌ This throws an error - you cannot output the sparse field
client.search(
collection_name='my_collection',
data=['query text'],
anns_field='sparse',
# highlight-next-line
output_fields=['text', 'sparse'] # 'sparse' causes an error
limit=3,
search_params=search_params
)
# ✅ This works - output text fields only
client.search(
collection_name='my_collection',
data=['query text'],
anns_field='sparse',
# highlight-next-line
output_fields=['text']
limit=3,
search_params=search_params
)
如果无法访问,为何还要定义稀疏向量字段呢?{#}
稀疏向量字段作为内部搜索索引,类似于用户不会直接与之交互的数据库索引。
设计原理:
-
关注点分离:你处理文本(输入/输出),Milvus处理矢量(内部处理)
-
性能:预计算的稀疏矢量可在查询期间实现快速的BM25排序
-
用户体验:将复杂的矢量运算抽象化,隐藏在简单的文本界面之后
如果您需要访问向量:
-
使用预计算的稀疏向量代替全文搜索
-
为自定义稀疏向量工作流创建单独的 Collection
详情请参考稀疏向量。