多向量混合搜索
在许多应用中,可以通过丰富的信息集来搜索对象,例如标题和描述,或者通过多种模态,如文本、图像和音频。例如,如果文本或图像与搜索查询的语义匹配,则应搜索包含一段文本和一张图像的推文。混合搜索通过结合跨这些不同字段的搜索来增强搜索体验。Zilliz Cloud 通过允许在多个向量字段上进行搜索,同时执行多个近似最近邻(ANN)搜索来支持这一点。如果您想同时搜索文本和图像、描述同一对象的多个文本字段,或者密集和稀疏向量以提高搜索质量,多向量混合搜索特别有用。
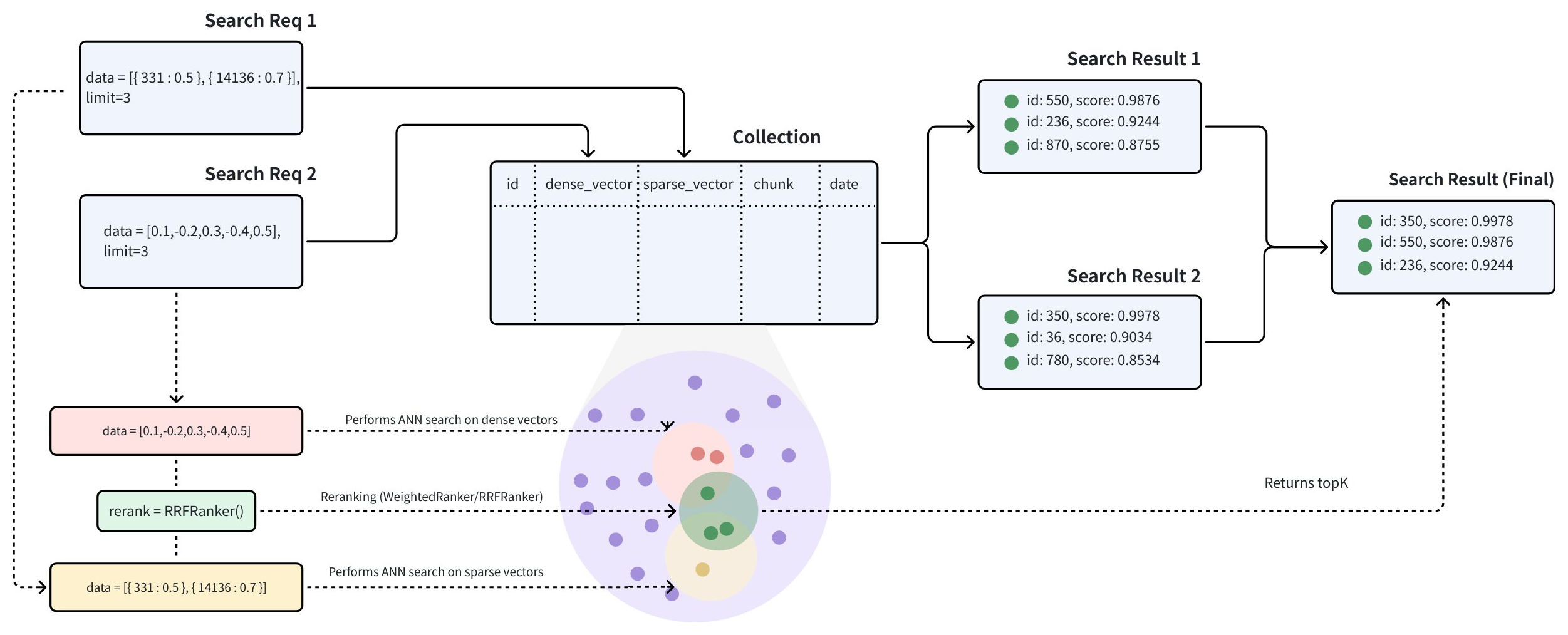
多向量混合搜索整合了不同的搜索方法或跨多种模态的嵌入:
-
稀疏-密集向量搜索:稠密向量非常适合捕捉语义关系,而稀疏向量对于精确的关键字匹配非常有效。混合搜索结合了这些方法,提供了广泛的概念理解和准确的术语相关性,从而改善了搜索结果。通过利用每种方法的优势,混合搜索克服了不可分割方法的局限性,为复杂查询提供了更好的性能。这里有一个更详细的混合检索指南,它将语义搜索与全文搜索相结合。
-
多模态向量搜索:多模态向量搜索是一种强大的技术,它允许你跨多种数据类型进行搜索,包括文本、图像、音频等。这种方法的主要优势在于它能够将不同的模态统一成无缝且连贯的搜索体验。例如,在产品搜索中,用户可能输入文本查询来查找同时用文本和图像描述的产品。通过混合搜索方法结合这些模态,你可以提高搜索准确性或丰富搜索结果。
示例
让我们考虑一个现实世界的用例,其中每个产品都包含文本描述和图像。根据可用数据,我们可以进行三种类型的搜索:
-
语义文本搜索:这涉及使用密集向量查询产品的文本描述。文本嵌入可以使用 BERT 和Transformers 等模型或 OpenAI 等服务生成。
-
全文搜索:在这里,我们使用与稀疏向量的关键词匹配来查询产品的文本描述。像 BM25 这样的算法或 BGE-M3、SPLADE 等稀疏嵌入模型可用于此目的。
-
多模态图像搜索:此方法使用带有密集向量的文本查询对图像进行查询。图像嵌入可以使用 CLIP 等模型生成。
本指南将结合产品的原始文本描述和图像嵌入,为您详细介绍一个结合上述搜索方法的多模态混合搜索示例。我们将展示如何存储多向量数据,并使用重排序策略执行混合搜索。
创建具有多个向量字段的集合
创建集合的过程涉及三个关键步骤:定义 Collection Schema、配置索引参数和创建 Collection。
定义 Schema
对于多向量混合搜索,我们应该在 Collection Schema 中定义多个向量字段。有关集合中允许的向量字段数量限制的详细信息,请参阅使用限制。
此示例将以下字段纳入架构中:
-
id:用作存储文本 ID 的主键。该字段的数据类型为INT64。 -
text:用于存储文本内容。该字段的数据类型为VARCHAR,最大长度为1000字节。enable_analyzer选项设置为True,以方便进行全文搜索。 -
text_dense:用于存储文本的密集向量。此字段的数据类型为FLOAT_VECTOR,向量维度为768。 -
text_sparse:用于存储文本的稀疏向量。该字段的数据类型为SPARSE_FLOAT_VECTOR。 -
image_dense: 用于存储产品图像的密集向量。该字段的数据类型为FLOAT_VETOR,向量维度为 512。
由于我们将使用内置的 BM25 算法对文本字段执行全文搜索,因此有必要在模式中添加 Milvus 函数。有关更多详细信息,请参阅 Full Text Search。
- Python
- Java
- Go
- NodeJS
- cURL
from pymilvus import (
MilvusClient, DataType, Function, FunctionType
)
client = MilvusClient(
uri="https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530",
token="YOUR_CLUSTER_TOKEN"
)
# Init schema with auto_id disabled
schema = client.create_schema(auto_id=False)
# Add fields to schema
schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True, description="product id")
schema.add_field(field_name="text", datatype=DataType.VARCHAR, max_length=1000, enable_analyzer=True, description="raw text of product description")
schema.add_field(field_name="text_dense", datatype=DataType.FLOAT_VECTOR, dim=768, description="text dense embedding")
schema.add_field(field_name="text_sparse", datatype=DataType.SPARSE_FLOAT_VECTOR, description="text sparse embedding auto-generated by the built-in BM25 function")
schema.add_field(field_name="image_dense", datatype=DataType.FLOAT_VECTOR, dim=512, description="image dense embedding")
# Add function to schema
bm25_function = Function(
name="text_bm25_emb",
input_field_names=["text"],
output_field_names=["text_sparse"],
function_type=FunctionType.BM25,
)
schema.add_function(bm25_function)
import io.milvus.v2.client.ConnectConfig;
import io.milvus.v2.client.MilvusClientV2;
import io.milvus.v2.common.DataType;
import io.milvus.common.clientenum.FunctionType;
import io.milvus.v2.service.collection.request.AddFieldReq;
import io.milvus.v2.service.collection.request.CreateCollectionReq;
import io.milvus.v2.service.collection.request.CreateCollectionReq.Function;
import java.util.*;
MilvusClientV2 client = new MilvusClientV2(ConnectConfig.builder()
.uri("https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530")
.token("YOUR_CLUSTER_TOKEN")
.build());
CreateCollectionReq.CollectionSchema schema = client.createSchema();
schema.addField(AddFieldReq.builder()
.fieldName("id")
.dataType(DataType.Int64)
.isPrimaryKey(true)
.autoID(false)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("text")
.dataType(DataType.VarChar)
.maxLength(1000)
.enableAnalyzer(true)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("text_dense")
.dataType(DataType.FloatVector)
.dimension(768)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("text_sparse")
.dataType(DataType.SparseFloatVector)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("image_dense")
.dataType(DataType.FloatVector)
.dimension(512)
.build());
schema.addFunction(Function.builder()
.functionType(FunctionType.BM25)
.name("text_bm25_emb")
.inputFieldNames(Collections.singletonList("text"))
.outputFieldNames(Collections.singletonList("text_sparse"))
.build());
import (
"context"
"fmt"
"github.com/milvus-io/milvus/client/v2/column"
"github.com/milvus-io/milvus/client/v2/entity"
"github.com/milvus-io/milvus/client/v2/index"
"github.com/milvus-io/milvus/client/v2/milvusclient"
)
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
milvusAddr := "https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530"
client, err := milvusclient.New(ctx, &milvusclient.ClientConfig{
Address: milvusAddr,
})
if err != nil {
fmt.Println(err.Error())
// handle error
}
defer client.Close(ctx)
function := entity.NewFunction().
WithName("text_bm25_emb").
WithInputFields("text").
WithOutputFields("text_sparse").
WithType(entity.FunctionTypeBM25)
schema := entity.NewSchema()
schema.WithField(entity.NewField().
WithName("id").
WithDataType(entity.FieldTypeInt64).
WithIsPrimaryKey(true),
).WithField(entity.NewField().
WithName("text").
WithDataType(entity.FieldTypeVarChar).
WithEnableAnalyzer(true).
WithMaxLength(1000),
).WithField(entity.NewField().
WithName("text_dense").
WithDataType(entity.FieldTypeFloatVector).
WithDim(768),
).WithField(entity.NewField().
WithName("text_sparse").
WithDataType(entity.FieldTypeSparseVector),
).WithField(entity.NewField().
WithName("image_dense").
WithDataType(entity.FieldTypeFloatVector).
WithDim(512),
).WithFunction(function)
import { MilvusClient, DataType } from "@zilliz/milvus2-sdk-node";
const address = "https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530";
const token = "YOUR_CLUSTER_TOKEN";
const client = new MilvusClient({address, token});
// Define fields
const fields = [
{
name: "id",
data_type: DataType.Int64,
is_primary_key: true,
auto_id: false
},
{
name: "text",
data_type: DataType.VarChar,
max_length: 1000,
enable_match: true
},
{
name: "text_dense",
data_type: DataType.FloatVector,
dim: 768
},
{
name: "text_sparse",
data_type: DataType.SPARSE_FLOAT_VECTOR
},
{
name: "image_dense",
data_type: DataType.FloatVector,
dim: 512
}
];
// define function
const functions = [
{
name: "text_bm25_emb",
description: "text bm25 function",
type: FunctionType.BM25,
input_field_names: ["text"],
output_field_names: ["text_sparse"],
params: {},
},
];
export bm25Function='{
"name": "text_bm25_emb",
"type": "BM25",
"inputFieldNames": ["text"],
"outputFieldNames": ["text_sparse"],
"params": {}
}'
export schema='{
"autoId": false,
"functions": [$bm25Function],
"fields": [
{
"fieldName": "id",
"dataType": "Int64",
"isPrimary": true
},
{
"fieldName": "text",
"dataType": "VarChar",
"elementTypeParams": {
"max_length": 1000,
"enable_analyzer": true
}
},
{
"fieldName": "text_dense",
"dataType": "FloatVector",
"elementTypeParams": {
"dim": "768"
}
},
{
"fieldName": "text_sparse",
"dataType": "SparseFloatVector"
},
{
"fieldName": "image_dense",
"dataType": "FloatVector",
"elementTypeParams": {
"dim": "512"
}
}
]
}'
创建索引
定义 Collection Schema 后,下一步是配置向量索引并指定相似度类型。在给定示例中:
-
text_dense_index:为文本稠密向量字段创建了一个类型为AUTOINDEX且度量类型为IP的索引。 -
text_sparse_index:类型为SPARSE_INVERTED_INDEX且BM25度量类型的索引用于文本稀疏向量字段。 -
image_dense_index:为图像密集向量字段创建了一个类型为AUTOINDEX、度量类型为IP的索引。
- Python
- Java
- Go
- NodeJS
- cURL
# Prepare index parameters
index_params = client.prepare_index_params()
# Add indexes
index_params.add_index(
field_name="text_dense",
index_name="text_dense_index",
index_type="AUTOINDEX",
metric_type="IP"
)
index_params.add_index(
field_name="text_sparse",
index_name="text_sparse_index",
index_type="AUTOINDEX",
metric_type="BM25"
)
index_params.add_index(
field_name="image_dense",
index_name="image_dense_index",
index_type="AUTOINDEX",
metric_type="IP"
)
import io.milvus.v2.common.IndexParam;
import java.util.*;
Map<String, Object> denseParams = new HashMap<>();
IndexParam indexParamForTextDense = IndexParam.builder()
.fieldName("text_dense")
.indexName("text_dense_index")
.indexType(IndexParam.IndexType.AUTOINDEX)
.metricType(IndexParam.MetricType.IP)
.build();
Map<String, Object> sparseParams = new HashMap<>();
sparseParams.put("inverted_index_algo": "DAAT_MAXSCORE");
IndexParam indexParamForTextSparse = IndexParam.builder()
.fieldName("text_sparse")
.indexName("text_sparse_index")
.indexType(IndexParam.IndexType.SPARSE_INVERTED_INDEX)
.metricType(IndexParam.MetricType.BM25)
.extraParams(sparseParams)
.build();
IndexParam indexParamForImageDense = IndexParam.builder()
.fieldName("image_dense")
.indexName("image_dense_index")
.indexType(IndexParam.IndexType.AUTOINDEX)
.metricType(IndexParam.MetricType.IP)
.build();
List<IndexParam> indexParams = new ArrayList<>();
indexParams.add(indexParamForTextDense);
indexParams.add(indexParamForTextSparse);
indexParams.add(indexParamForImageDense);
indexOption1 := milvusclient.NewCreateIndexOption("my_collection", "text_dense",
index.NewAutoIndex(index.MetricType(entity.IP)))
indexOption2 := milvusclient.NewCreateIndexOption("my_collection", "text_sparse",
index.NewSparseInvertedIndex(entity.BM25, 0.2))
indexOption3 := milvusclient.NewCreateIndexOption("my_collection", "image_dense",
index.NewAutoIndex(index.MetricType(entity.IP)))
)
const index_params = [{
field_name: "text_dense",
index_name: "text_dense_index",
index_type: "AUTOINDEX",
metric_type: "IP"
},{
field_name: "text_sparse",
index_name: "text_sparse_index",
index_type: "IndexType.SPARSE_INVERTED_INDEX",
metric_type: "BM25",
params: {
inverted_index_algo: "DAAT_MAXSCORE",
}
},{
field_name: "image_dense",
index_name: "image_dense_index",
index_type: "AUTOINDEX",
metric_type: "IP"
}]
export indexParams='[
{
"fieldName": "text_dense",
"metricType": "IP",
"indexName": "text_dense_index",
"indexType":"AUTOINDEX"
},
{
"fieldName": "text_sparse",
"metricType": "BM25",
"indexName": "text_sparse_index",
"indexType": "SPARSE_INVERTED_INDEX",
"params":{"inverted_index_algo": "DAAT_MAXSCORE"}
},
{
"fieldName": "image_dense",
"metricType": "IP",
"indexName": "image_dense_index",
"indexType":"AUTOINDEX"
}
]'
创建 Collection
创建一个名为demo的 Collection,其 Schema 和索引已在前面两个步骤中配置。
- Python
- Java
- Go
- NodeJS
- cURL
client.create_collection(
collection_name="my_collection",
schema=schema,
index_params=index_params
)
CreateCollectionReq createCollectionReq = CreateCollectionReq.builder()
.collectionName("my_collection")
.collectionSchema(schema)
.indexParams(indexParams)
.build();
client.createCollection(createCollectionReq);
err = client.CreateCollection(ctx,
milvusclient.NewCreateCollectionOption("my_collection", schema).
WithIndexOptions(indexOption1, indexOption2))
if err != nil {
fmt.Println(err.Error())
// handle error
}
res = await client.createCollection({
collection_name: "my_collection",
fields: fields,
index_params: index_params,
})
export CLUSTER_ENDPOINT="https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530"
export TOKEN="YOUR_CLUSTER_TOKEN"
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/collections/create" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
-d "{
\"collectionName\": \"my_collection\",
\"schema\": $schema,
\"indexParams\": $indexParams
}"
插入数据
本节根据之前定义的 Schema 将数据插入到 my_collection 中。在插入过程中,请确保除了具有自动生成值的字段外,所有字段都以正确的格式提供了数据。在这个示例中:
-
id:表示产品 ID 的整数 -
text: 包含产品描述的字符串 -
text_dense:一个包含 768 个浮点值的列表,代表文本描述的密集嵌入 -
image_dense: 一个包含 512 个浮点值的列表,代表产品图像的密集嵌入
您可以使用相同或不同的模型为每个字段生成稠密向量。在这个示例中,两个稠密向量的维度不同,这表明它们是由不同的模型生成的。在后续定义每个搜索时,请务必使用相应的模型来生成合适的查询向量。
由于此示例使用内置的 BM25 函数从文本字段生成稀疏向量,因此您无需手动提供稀疏向量。但是,如果您选择不使用 BM25,则必须自行预先计算并提供稀疏嵌入。
- Python
- Java
- Go
- NodeJS
- cURL
import random
# Generate example vectors
def generate_dense_vector(dim):
return [random.random() for _ in range(dim)]
data=[
{
"id": 0,
"text": "Red cotton t-shirt with round neck",
"text_dense": generate_dense_vector(768),
"image_dense": generate_dense_vector(512)
},
{
"id": 1,
"text": "Wireless noise-cancelling over-ear headphones",
"text_dense": generate_dense_vector(768),
"image_dense": generate_dense_vector(512)
},
{
"id": 2,
"text": "Stainless steel water bottle, 500ml",
"text_dense": generate_dense_vector(768),
"image_dense": generate_dense_vector(512)
}
]
res = client.insert(
collection_name="my_collection",
data=data
)
import com.google.gson.Gson;
import com.google.gson.JsonObject;
import io.milvus.v2.service.vector.request.InsertReq;
Gson gson = new Gson();
JsonObject row1 = new JsonObject();
row1.addProperty("id", 0);
row1.addProperty("text", "Red cotton t-shirt with round neck");
row1.add("text_dense", gson.toJsonTree(text_dense1));
row1.add("image_dense", gson.toJsonTree(image_dense));
JsonObject row2 = new JsonObject();
row2.addProperty("id", 1);
row2.addProperty("text", "Wireless noise-cancelling over-ear headphones");
row2.add("text_dense", gson.toJsonTree(text_dense2));
row2.add("image_dense", gson.toJsonTree(image_dense2));
JsonObject row3 = new JsonObject();
row3.addProperty("id", 2);
row3.addProperty("text", "Stainless steel water bottle, 500ml");
row3.add("text_dense", gson.toJsonTree(dense3));
row3.add("image_dense", gson.toJsonTree(sparse3));
List<JsonObject> data = Arrays.asList(row1, row2, row3);
InsertReq insertReq = InsertReq.builder()
.collectionName("my_collection")
.data(data)
.build();
InsertResp insertResp = client.insert(insertReq);
_, err = client.Insert(ctx, milvusclient.NewColumnBasedInsertOption("my_collection").
WithInt64Column("id", []int64{0, 1, 2}).
WithVarcharColumn("text", []string{
"Red cotton t-shirt with round neck",
"Wireless noise-cancelling over-ear headphones",
"Stainless steel water bottle, 500ml",
}).
WithFloatVectorColumn("text_dense", 768, [][]float32{
{0.3580376395471989, -0.6023495712049978, 0.18414012509913835, ...},
{0.19886812562848388, 0.06023560599112088, 0.6976963061752597, ...},
{0.43742130801983836, -0.5597502546264526, 0.6457887650909682, ...},
}).
WithFloatVectorColumn("image_dense", 512, [][]float32{
{0.6366019600530924, -0.09323198122475052, ...},
{0.6414180010301553, 0.8976979978567611, ...},
{-0.6901259768402174, 0.6100500332193755, ...},
}).
if err != nil {
fmt.Println(err.Error())
// handle err
}
const { MilvusClient, DataType } = require("@zilliz/milvus2-sdk-node")
var data = [
{id: 0, text: "Red cotton t-shirt with round neck" , text_dense: [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, ...], image_dense: [0.6366019600530924, -0.09323198122475052, ...]},
{id: 1, text: "Wireless noise-cancelling over-ear headphones" , text_dense: [0.19886812562848388, 0.06023560599112088, 0.6976963061752597, ...], image_dense: [0.6414180010301553, 0.8976979978567611, ...]},
{id: 2, text: "Stainless steel water bottle, 500ml" , text_dense: [0.43742130801983836, -0.5597502546264526, 0.6457887650909682, ...], image_dense: [-0.6901259768402174, 0.6100500332193755, ...]}
]
var res = await client.insert({
collection_name: "my_collection",
data: data,
})
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/insert" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
-d '{
"data": [
{"id": 0, "text": "Red cotton t-shirt with round neck" , "text_dense": [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, ...], "image_dense": [0.6366019600530924, -0.09323198122475052, ...]},
{"id": 1, "text": "Wireless noise-cancelling over-ear headphones" , "text_dense": [0.19886812562848388, 0.06023560599112088, 0.6976963061752597, ...], "image_dense": [0.6414180010301553, 0.8976979978567611, ...]},
{"id": 2, "text": "Stainless steel water bottle, 500ml" , "text_dense": [0.43742130801983836, -0.5597502546264526, 0.6457887650909682, ...], "image_dense": [-0.6901259768402174, 0.6100500332193755, ...]}
],
"collectionName": "my_collection"
}'
执行混合搜索
步骤 1:创建多个 AnnSearchRequest 实例
混合搜索通过在 hybrid_search() 函数中创建多个 AnnSearchRequest 来实现,其中每个 AnnSearchRequest 代表针对特定向量字段的基本 ANN 搜索请求。因此,在进行混合搜索之前,有必要为每个向量字段创建一个 AnnSearchRequest。
此外,通过在 AnnSearchRequest 中配置 expr 参数,您可以为混合搜索设置过滤条件。请参考 Filtered Search 和 过滤表达式概览。
在混合搜索中,每个 AnnSearchRequest 仅支持一个查询数据。
为了展示各种搜索向量字段的功能,我们将使用一个示例查询构造三个 AnnSearchRequest 搜索请求。我们还将在这个过程中使用其预先计算的稠密向量。搜索请求将针对以下向量字段:
-
text_dense用于语义文本搜索,支持基于含义的上下文理解和检索,而非直接的关键词匹配。 -
text_sparse稀疏用于全文搜索或关键词匹配,专注于文本中精确的单词或短语匹配。 -
image_dense用于多模态文本到图像搜索,根据查询的语义内容检索相关产品图像。
- Python
- Java
- Go
- NodeJS
- cURL
from pymilvus import AnnSearchRequest
query_text = "white headphones, quiet and comfortable"
query_dense_vector = generate_dense_vector(768)
query_multimodal_vector = generate_dense_vector(512)
# text semantic search (dense)
search_param_1 = {
"data": [query_dense_vector],
"anns_field": "text_dense",
"limit": 2
}
request_1 = AnnSearchRequest(**search_param_1)
# full-text search (sparse)
search_param_2 = {
"data": [query_text],
"anns_field": "text_sparse",
"limit": 2
}
request_2 = AnnSearchRequest(**search_param_2)
# text-to-image search (multimodal)
search_param_3 = {
"data": [query_multimodal_vector],
"anns_field": "image_dense",
"limit": 2
}
request_3 = AnnSearchRequest(**search_param_3)
reqs = [request_1, request_2, request_3]
import io.milvus.v2.service.vector.request.AnnSearchReq;
import io.milvus.v2.service.vector.request.data.BaseVector;
import io.milvus.v2.service.vector.request.data.FloatVec;
import io.milvus.v2.service.vector.request.data.SparseFloatVec;
import io.milvus.v2.service.vector.request.data.EmbeddedText;
float[] queryDense = new float[]{-0.0475336798f, 0.0521207601f, 0.0904406682f, ...};
float[] queryMultimodal = new float[]{0.0158298651f, 0.5264158340f, ...}
List<BaseVector> queryTexts = Collections.singletonList(new EmbeddedText("white headphones, quiet and comfortable");)
List<BaseVector> queryDenseVectors = Collections.singletonList(new FloatVec(queryDense));
List<BaseVector> queryMultimodalVectors = Collections.singletonList(new FloatVec(queryMultimodal));
List<AnnSearchReq> searchRequests = new ArrayList<>();
searchRequests.add(AnnSearchReq.builder()
.vectorFieldName("text_dense")
.vectors(queryDenseVectors)
.topK(2)
.build());
searchRequests.add(AnnSearchReq.builder()
.vectorFieldName("text_sparse")
.vectors(queryTexts)
.topK(2)
.build());
searchRequests.add(AnnSearchReq.builder()
.vectorFieldName("image_dense")
.vectors(queryMultimodalVectors)
.topK(2)
.build());
queryText := entity.Text({"white headphones, quiet and comfortable"})
queryVector := []float32{0.3580376395471989, -0.6023495712049978, 0.18414012509913835, ...}
queryMultimodalVector := []float32{0.015829865178701663, 0.5264158340734488, ...}
request1 := milvusclient.NewAnnRequest("text_dense", 2, entity.FloatVector(queryVector)).
WithAnnParam(index.NewIvfAnnParam(10))
annParam := index.NewSparseAnnParam()
annParam.WithDropRatio(0.2)
request2 := milvusclient.NewAnnRequest("text_sparse", 2, queryText).
WithAnnParam(annParam)
request3 := milvusclient.NewAnnRequest("image_dense", 2, entity.FloatVector(queryMultimodalVector)).
WithAnnParam(index.NewIvfAnnParam(10))
const query_text = "white headphones, quiet and comfortable"
const query_vector = [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, ...]
const query_multimodal_vector = [0.015829865178701663, 0.5264158340734488, ...]
const search_param_1 = {
"data": query_vector,
"anns_field": "text_dense",
"limit": 2
}
const search_param_2 = {
"data": query_text,
"anns_field": "text_sparse",
"limit": 2
}
const search_param_3 = {
"data": query_multimodal_vector,
"anns_field": "image_dense",
"limit": 2
}
export req='[
{
"data": [[0.3580376395471989, -0.6023495712049978, 0.18414012509913835, ...]],
"annsField": "text_dense",
"limit": 2
},
{
"data": ["white headphones, quiet and comfortable"],
"annsField": "text_sparse",
"limit": 2
},
{
"data": [[0.015829865178701663, 0.5264158340734488, ...]],
"annsField": "image_dense",
"limit": 2
}
]'
由于参数 limit 设置为 2,每个 AnnSearchRequest 返回 2 个搜索结果。在这个例子中,创建了 3 个 AnnSearchRequest 实例,总共产生 6 个搜索结果。
步骤 2:配置重排序策略
为了合并和重新排序 ANN 搜索结果集,选择合适的重排序策略至关重要。Zilliz Cloud 提供多种重排序策略。有关这些重排序机制的更多详细信息,请参阅重排。
在这个例子中,由于没有特别强调特定的搜索查询,我们将采用 RRFRanker 策略。
- Python
- Java
- NodeJS
- Go
- cURL
ranker = Function(
name="rrf",
input_field_names=[], # Must be an empty list
function_type=FunctionType.RERANK,
params={
"reranker": "rrf",
"k": 100 # Optional
}
)
import io.milvus.common.clientenum.FunctionType;
import io.milvus.v2.service.collection.request.CreateCollectionReq.Function;
Function ranker = Function.builder()
.name("rrf")
.functionType(FunctionType.RERANK)
.param("reranker", "rrf")
.param("k", "100")
.build()
const ranker = {
name: 'rrf',
description: 'bm25 function',
type: FunctionType.RERANK,
input_field_names: [],
params: {
"reranker": "rrf",
"k": 100
},
};
import (
"github.com/milvus-io/milvus/client/v2/entity"
)
ranker := entity.NewFunction().
WithName("rrf").
WithType(entity.FunctionTypeRerank).
WithParam("reranker", "rrf").
WithParam("k", "100")
# Restful
export ranker='{
"functions": [
{
"name": "rrf",
"type": "Rerank",
"inputFieldNames": [],
"params": {
"reranker": "rrf",
"k": 100
}
}
]
}'
步骤 3:执行混合搜索
在启动混合搜索之前,请确保已加载 Collection。如果 Collection 中的任何向量字段缺少索引或未加载到内存中,则在执行混合搜索方法时将发生错误。
- Python
- Java
- Go
- NodeJS
- cURL
res = client.hybrid_search(
collection_name="my_collection",
reqs=reqs,
ranker=ranker,
limit=2
)
for hits in res:
print("TopK results:")
for hit in hits:
print(hit)
import io.milvus.v2.common.ConsistencyLevel;
import io.milvus.v2.service.vector.request.HybridSearchReq;
import io.milvus.v2.service.vector.response.SearchResp;
HybridSearchReq hybridSearchReq = HybridSearchReq.builder()
.collectionName("my_collection")
.searchRequests(searchRequests)
.ranker(ranker)
.topK(2)
.build();
SearchResp searchResp = client.hybridSearch(hybridSearchReq);
resultSets, err := client.HybridSearch(ctx, milvusclient.NewHybridSearchOption(
"my_collection",
2,
request1,
request2,
request3,
).WithReranker(ranker))
if err != nil {
fmt.Println(err.Error())
// handle error
}
for _, resultSet := range resultSets {
fmt.Println("IDs: ", resultSet.IDs.FieldData().GetScalars())
fmt.Println("Scores: ", resultSet.Scores)
}
const { MilvusClient, DataType } = require("@zilliz/milvus2-sdk-node")
res = await client.loadCollection({
collection_name: "my_collection"
})
import { MilvusClient, RRFRanker, WeightedRanker } from '@zilliz/milvus2-sdk-node';
const search = await client.search({
collection_name: "my_collection",
data: [search_param_1, search_param_2, search_param_3],
limit: 2,
rerank: ranker
});
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/hybrid_search" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
-d "{
\"collectionName\": \"my_collection\",
\"search\": ${req},
\"rerank\": {
\"strategy\":\"rrf\",
\"params\": ${ranker}
},
\"limit\": 2
}"
以下是输出内容:
["['id: 1, distance: 0.006047376897186041, entity: {}', 'id: 2, distance: 0.006422005593776703, entity: {}']"]
在为混合搜索指定了 limit=2 参数的情况下,Zilliz Cloud 将对从三次搜索中获得的六个结果进行重新排序。最终,它们将只返回最相似的前两个结果。
高级用法
为混合搜索临时设置时区
如果你的 Collection 包含一个 TIMESTAMPTZ 字段,你可以在混合搜索调用中设置 timezone 参数,从而在单次操作中临时覆盖数据库或 Collection 的默认时区。该参数会控制在该操作期间 TIMESTAMPTZ 值的显示与比较方式。
timezone 的值必须是有效的 IANA 时区标识符(例如 Asia/Shanghai、America/Chicago 或 UTC)。
关于如何使用 TIMESTAMPTZ 字段的更多信息,请参考 TIMESTAMPTZ 类型。
下面的示例展示了如何在一次混合搜索操作中临时指定时区:
res = client.hybrid_search(
collection_name="my_collection",
reqs=reqs,
ranker=ranker,
limit=2,
# highlight-next-line
timezone="America/Havana",
)