MINHASH_LSH
对于大规模机器学习数据集而言,高效的去重和相似度搜索至关重要,尤其是在清洗用于训练大语言模型(LLM)的语料库等场景中。当面对数百万乃至数十亿规模的文档时,传统的精确匹配方法往往因速度过慢、成本过高而难以适用。
Zilliz Cloud 中的 MINHASH_LSH 索引通过结合两种强大的技术,实现了快速、可扩展且准确的近似去重:
-
MinHash:快速生成紧凑的签名("指纹")以估算文档间的相似度。
-
局部敏感哈希(LSH):基于 MinHash 签名快速找出相似文档的集合。
本指南介绍在 Zilliz Cloud 中使用 MINHASH_LSH 的相关概念、前提条件、配置步骤以及最佳实践。
概览{#}
展开了解 MinHash LSH 工作原理
Jaccard 相似度
Jaccard 相似度用于衡量两个集合 A 和 B 之间的重叠程度,其正式定义为:
其取值范围为 0(完全不相交)到 1(完全相同)。
但在大规模数据集中,精确计算所有文档对之间的 Jaccard 相似度在时间和内存开销上都是 O(n²) 级别的,当 n 较大时,这种开销变得不可承受。因此,该方法在 LLM 训练语料清洗或网页级文档分析等场景中难以使用。
MinHash 签名:近似 Jaccard 相似度
MinHash 是一种概率技术,能够高效地估算 Jaccard 相似度。它将每个集合转换为一个紧凑的签名向量,并保留足够的信息以高效近似集合间的相似度。
核心思想:
两个集合越相似,它们的 MinHash 签名在相同位置上匹配的概率就越高。这一特性使得 MinHash 能够近似估算集合间的 Jaccard 相似度。
借助这一特性,MinHash 可以近似估算 Jaccard 相似度,而无需直接比较完整的集合。
MinHash 的处理流程包括:
-
Shingling:将文档拆分为重叠的 token 序列集合(shingle)。
-
哈希:对每个 shingle 应用多个独立的哈希函数。
-
取最小值:对每个哈希函数,记录所有 shingle 哈希值中的最小值。
完整过程如下图所示:
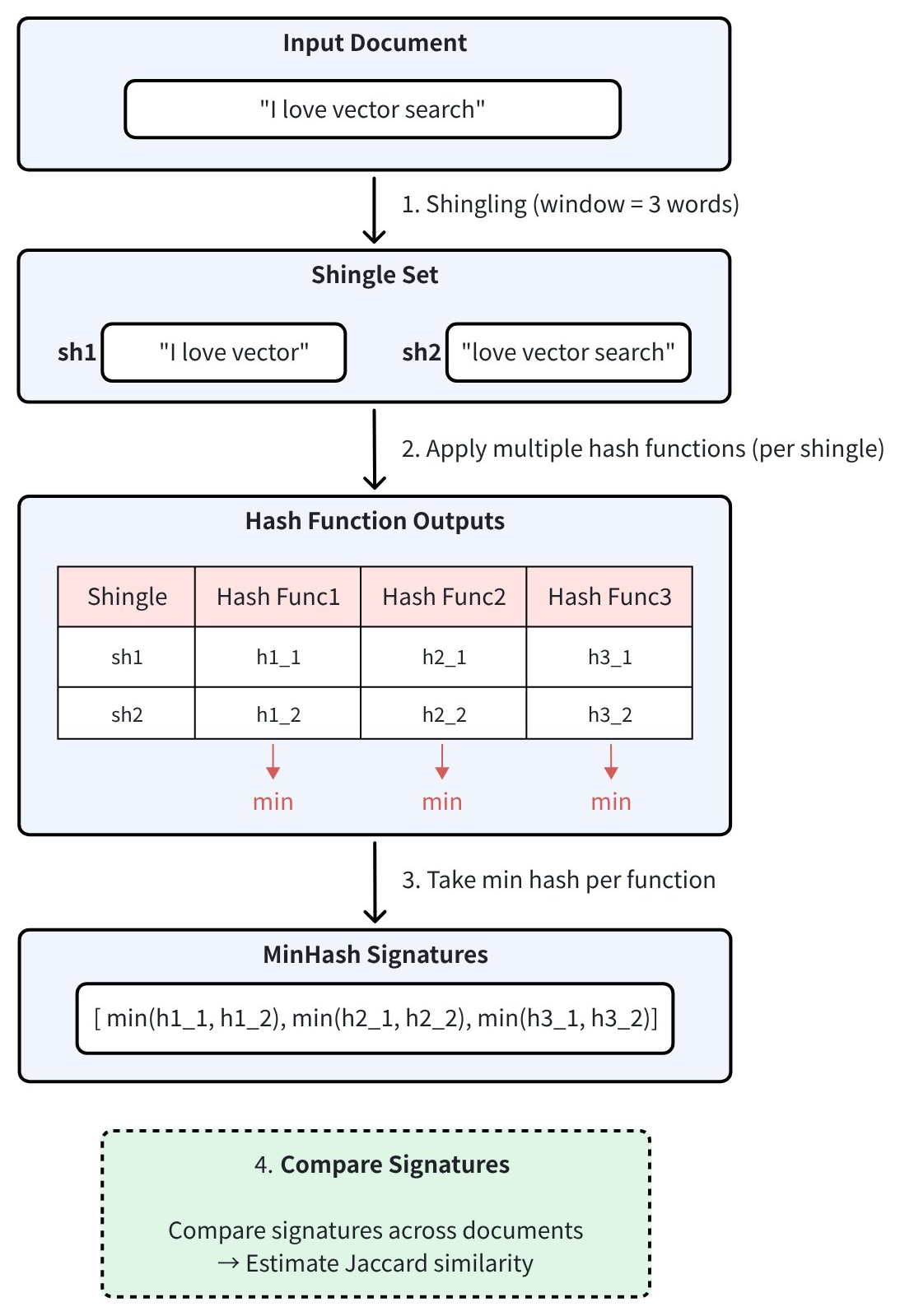
所使用的哈希函数数量决定了 MinHash 签名的维度。维度越高,近似精度越好,但相应的存储和计算成本也会增加。
MinHash 的 LSH
虽然 MinHash 签名显著降低了精确计算文档间 Jaccard 相似度的开销,但在大规模数据下逐一比较所有签名向量仍然效率低下。
为了解决这一问题,可以使用 LSH。LSH 通过让相似项以高概率被哈希到同一个"桶"中,从而实现快速的近似相似度搜索,避免对所有项进行两两比较。
具体流程如下:
-
签名分段:
一个 n 维 MinHash 签名被划分为 b 个 band,每个 band 包含 r 个连续的哈希值,因此签名总长度满足:n = b × r。
例如,一个 128 维的 MinHash 签名(n = 128)被划分为 32 个 band(b = 32),则每个 band 包含 4 个哈希值(r = 4)。
-
band 级哈希:
分段完成后,每个 band 都通过一个标准哈希函数独立处理,被分配到一个桶中。如果两个签名在某个 band 内产生了相同的哈希值——即落入同一个桶——它们就被视为潜在的匹配项。
-
候选筛选:
在至少一个 band 上发生碰撞的签名对会被选为相似性候选。
它为什么有效?
从数学角度看,如果两个签名的 Jaccard 相似度为 :
-
它们在某一行(哈希位置)上相同的概率为
-
它们在一个 band 的全部 rr 行上都匹配的概率为
-
它们在至少一个 band 上匹配的概率为 $1 - (1 - s^r)^b$
更多详情请参考 Locality-sensitive hashing。
以三个具有 128 维 MinHash 签名的文档为例:
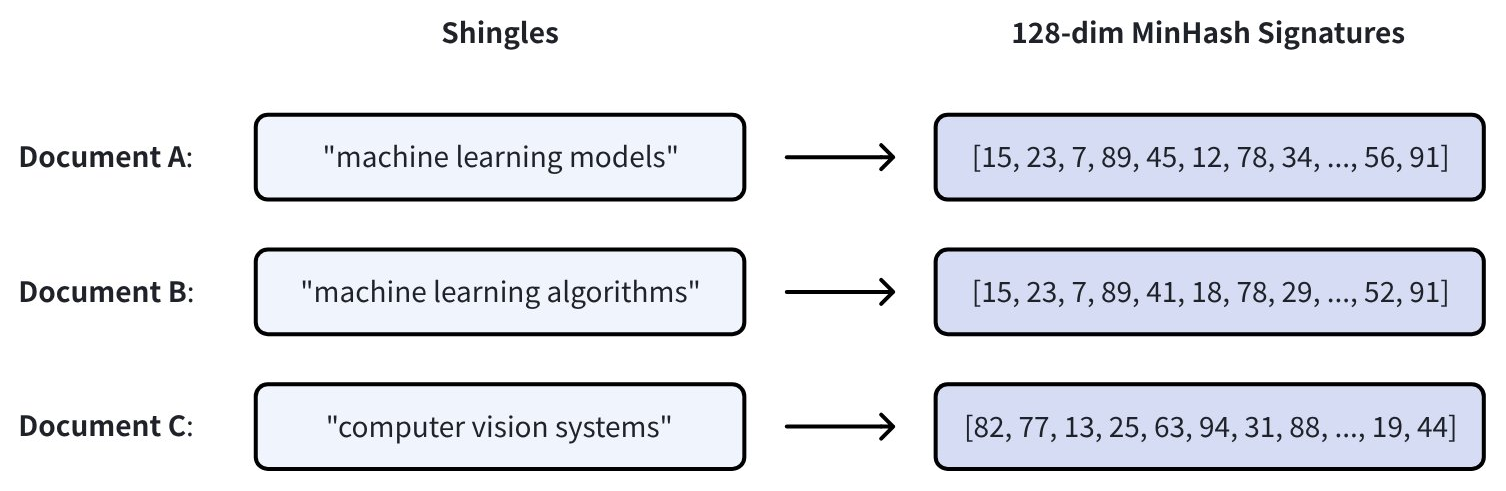
首先,LSH 将 128 维签名划分为 32 个 band,每个 band 包含 4 个连续的值:
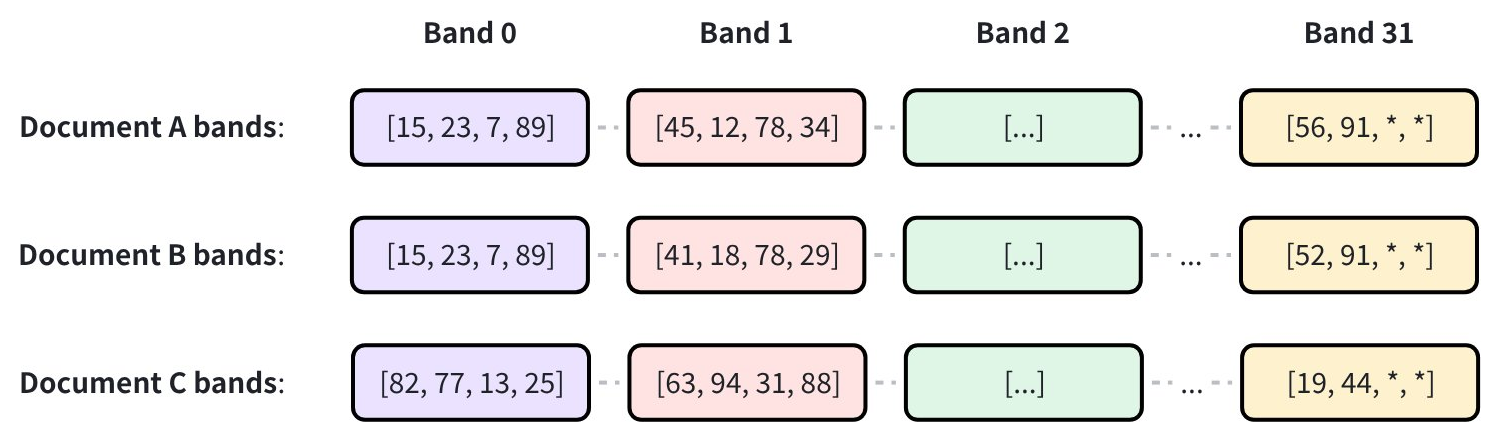
接着,每个 band 通过哈希函数被分配到不同的桶中。共享同一个桶的文档对会被选为相似性候选。在下例中,文档 A 和文档 B 在 Band 0 上的哈希结果发生碰撞,因此被选为相似性候选:
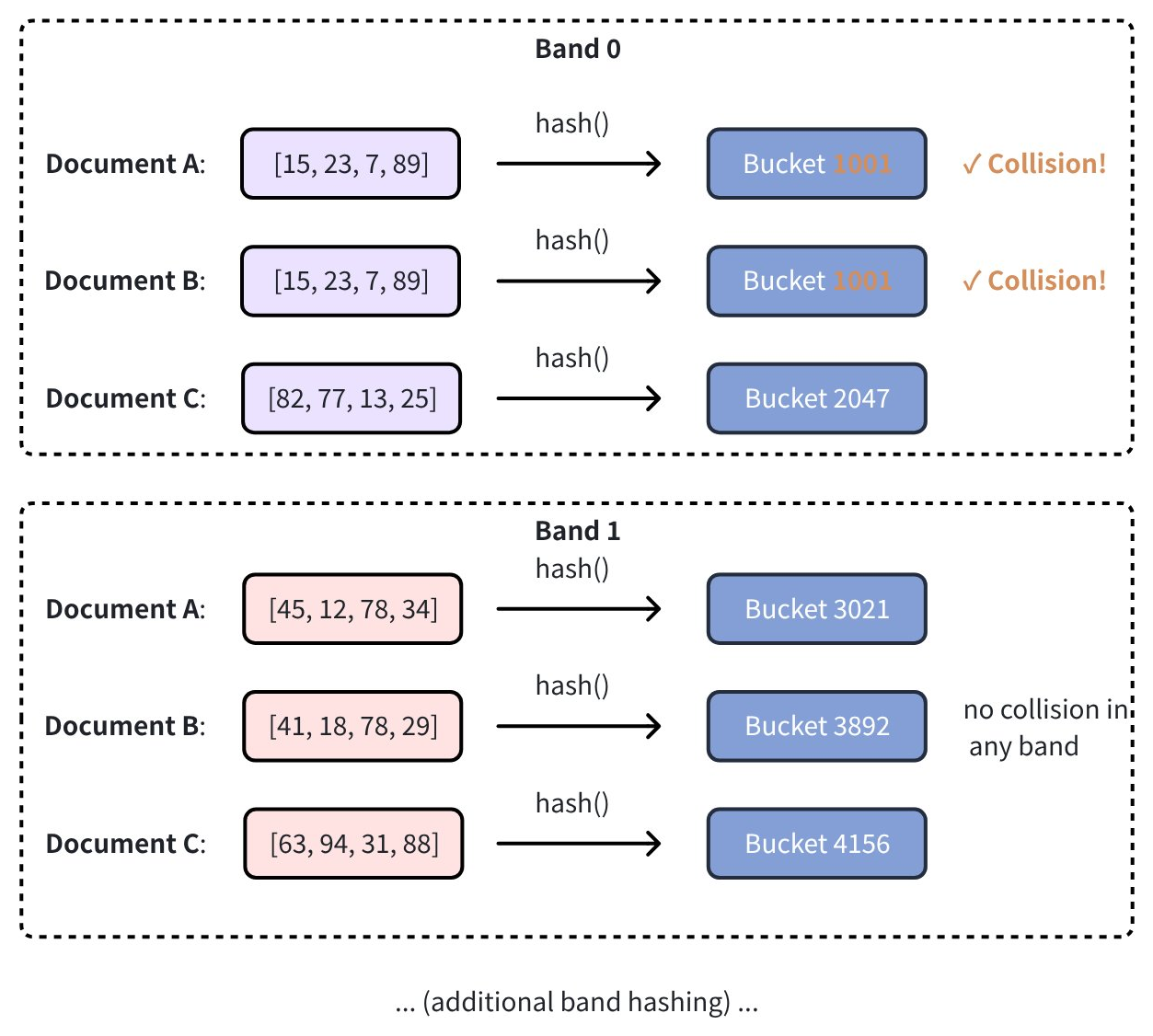
band 的数量由 mh_lsh_band 参数控制。更多信息请参见索引构建参数。
MHJACCARD:比较 MinHash 签名
MinHash 签名通过固定长度的二进制向量来近似集合间的 Jaccard 相似度。但由于这些签名并不保留原始集合,因此无法直接使用 JACCARD、L2 或 COSINE 等标准度量来比较它们。
为此,Zilliz Cloud 引入了一种专门用于比较 MinHash 签名的度量类型 MHJACCARD。
在 Zilliz Cloud 中使用 MinHash 时:
-
向量字段类型必须为
BINARY_VECTOR -
index_type必须为MINHASH_LSH(或BIN_FLAT) -
metric_type必须设置为MHJACCARD
使用其他度量类型要么无效,要么会得到错误的结果。
关于该度量类型的更多信息,请参考 MHJACCARD。
去重工作流程{#}
借助 MinHash LSH 实现的去重流程,使 Zilliz Cloud 能够在将数据写入 Collection 之前,高效识别并过滤掉近似重复的文本或结构化记录。
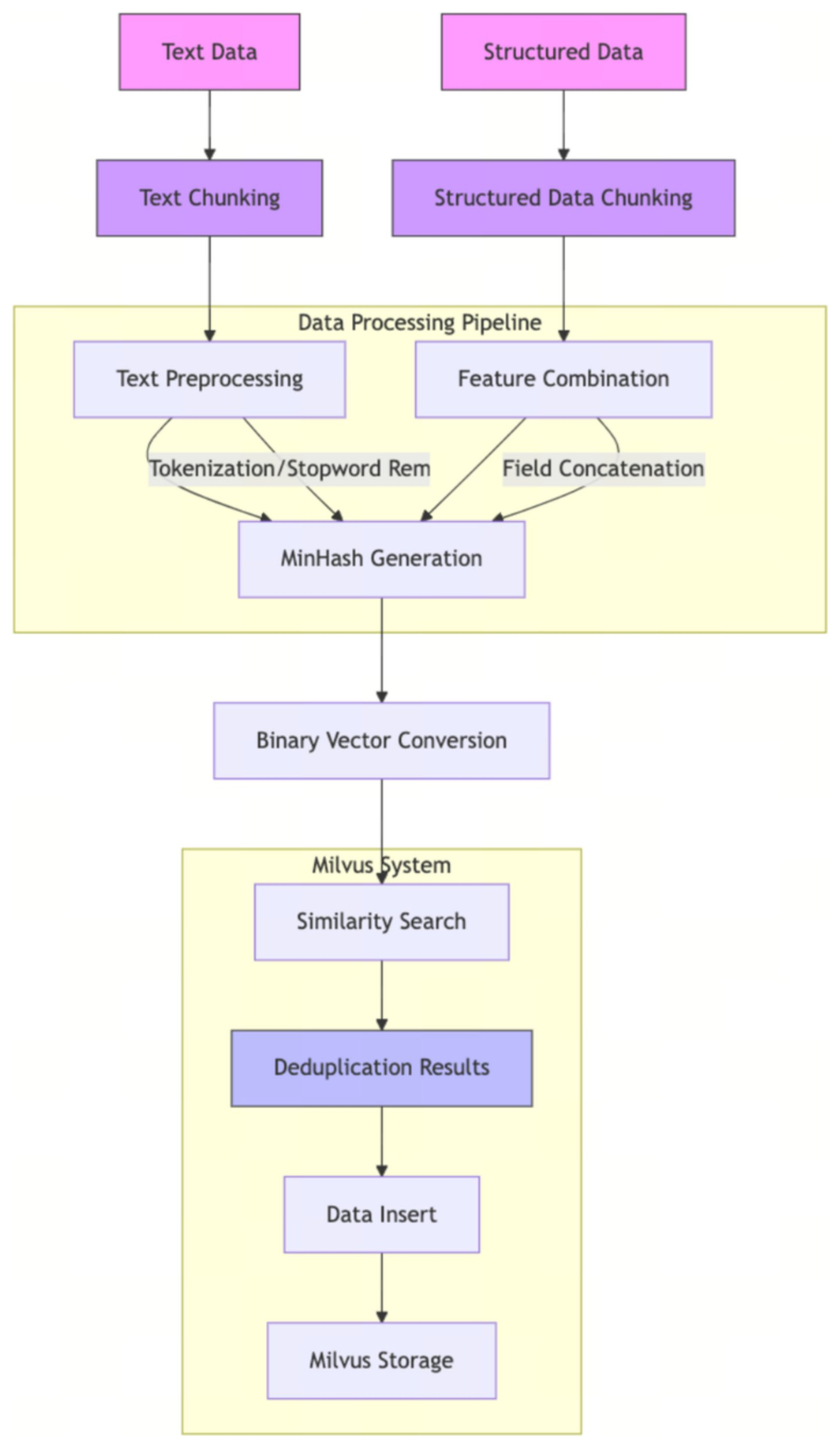
-
切分与预处理:将输入文本数据或结构化数据(例如记录、字段)切分为多个块;对文本进行规范化处理(转小写、去除标点),并根据需要去除停用词。
-
特征构造:构造用于 MinHash 的 token 集合(例如文本的 shingle;结构化数据中字段拼接得到的 token)。
-
MinHash 签名生成:为每个块或记录计算 MinHash 签名。
-
二进制向量转换:将签名转换为与 Zilliz Cloud 兼容的二进制向量。
-
先搜后插:使用 MinHash LSH 索引在目标 Collection 中搜索与待插入项近似重复的数据。
-
写入与存储:仅将不重复的数据写入 Collection,使其在后续去重检查中可被搜索。
前提条件{#}
在 Zilliz Cloud 中使用 MinHash LSH 之前,您必须先生成 MinHash 签名。这些紧凑的二进制签名用于近似集合间的 Jaccard 相似度,是在 Zilliz Cloud 中执行基于 MHJACCARD 的搜索所必需的输入。
为 MINHASH_LSH 索引准备 MinHash 签名有两种方式:
-
使用外部工具自行生成签名,并写入 BINARY_VECTOR 字段;或
-
使用内置的 MinHash 函数自动从文本生成兼容的二进制向量。关于 MinHash 函数的端到端工作流程和配置选项,请参考 MinHash Function。
选择 MinHash 签名的生成方式
您可以根据自身工作负载来选择合适的生成方式:
-
使用 Python 的
datasketch,简单易用(推荐用于原型开发) -
使用 Spark、Ray 等分布式工具处理大规模数据集
-
在需要进行性能调优时,使用 NumPy、C++ 等实现自定义逻辑
本指南为了简洁起见,使用 datasketch 来演示,其输出格式与 Zilliz Cloud 的输入格式兼容。
安装所需依赖{#}
安装本例所需的依赖包:
pip install pymilvus datasketch numpy
生成 MinHash 签名
我们将生成 256 维的 MinHash 签名,每个哈希值由 64 位整数表示。这与 MINHASH_LSH 期望的向量格式一致。
from datasketch import MinHash
import numpy as np
MINHASH_DIM = 256
HASH_BIT_WIDTH = 64
def generate_minhash_signature(text, num_perm=MINHASH_DIM) -> bytes:
m = MinHash(num_perm=num_perm)
for token in text.lower().split():
m.update(token.encode("utf8"))
return m.hashvalues.astype('>u8').tobytes() # Returns 2048 bytes
每个签名的大小为 256 × 64 bit = 2048 字节。该字节串可以直接写入 BINARY_VECTOR 字段。关于 Zilliz Cloud 中使用的二进制向量的更多信息,请参考 Binary 向量。
(可选)准备原始 token 集合(用于精排搜索)
默认情况下,Zilliz Cloud 仅基于 MinHash 签名和 LSH 索引来查找近似邻居。这种方式速度很快,但可能产生误判或漏掉某些近似匹配。
如果您希望获得精确的 Jaccard 相似度,Zilliz Cloud 支持使用原始 token 集合进行精排搜索。启用方式:
-
将 token 集合存储在一个单独的
VARCHAR字段中 -
在构建索引参数时设置
"with_raw_data": True -
在执行相似度搜索时启用
"mh_search_with_jaccard": True
token 集合提取示例:
def extract_token_set(text: str) -> str:
tokens = set(text.lower().split())
return " ".join(tokens)
使用 MinHash LSH
当 MinHash 向量和原始 token 集合准备就绪后,您可以使用 Zilliz Cloud 的 MINHASH_LSH 来存储、索引并搜索这些数据。
连接到集群{#}
from pymilvus import MilvusClient
client = MilvusClient(uri="https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530") # Update if your URI is different
定义 Collection Schema
定义包含以下字段的 schema:
-
主键
-
用于存储 MinHash 签名的
BINARY_VECTOR字段 -
用于存储原始 token 集合的
VARCHAR字段(启用精排搜索时需要) -
(可选)用于存储原始文本的
document字段
from pymilvus import DataType
VECTOR_DIM = MINHASH_DIM * HASH_BIT_WIDTH # 256 × 64 = 8192 bits
schema = client.create_schema(auto_id=False, enable_dynamic_field=False)
schema.add_field("doc_id", DataType.INT64, is_primary=True)
schema.add_field("minhash_signature", DataType.BINARY_VECTOR, dim=VECTOR_DIM)
schema.add_field("token_set", DataType.VARCHAR, max_length=1000) # required for refinement
schema.add_field("document", DataType.VARCHAR, max_length=1000)
构建索引参数并创建 Collection
构建启用了 Jaccard 精排的 MINHASH_LSH 索引:
index_params = client.prepare_index_params()
index_params.add_index(
field_name="minhash_signature",
index_type="MINHASH_LSH",
metric_type="MHJACCARD",
params={
"mh_element_bit_width": HASH_BIT_WIDTH, # Must match signature bit width
"mh_lsh_band": 16, # Band count (128/16 = 8 hashes per band)
"with_raw_data": True # Required for Jaccard refinement
}
)
client.create_collection("minhash_demo", schema=schema, index_params=index_params)
关于索引构建参数的更多信息,请参考索引构建参数。
写入数据{#}
为每个文档准备:
-
一个二进制 MinHash 签名
-
一个序列化的 token 集合字符串
-
(可选)原始文本
documents = [
"machine learning algorithms process data automatically",
"deep learning uses neural networks to model patterns"
]
insert_data = []
for i, doc in enumerate(documents):
sig = generate_minhash_signature(doc)
token_str = extract_token_set(doc)
insert_data.append({
"doc_id": i,
"minhash_signature": sig,
"token_set": token_str,
"document": doc
})
client.insert("minhash_demo", insert_data)
client.flush("minhash_demo")
执行相似度搜索{#}
Zilliz Cloud 在 MinHash LSH 上支持两种相似度搜索模式:
-
近似搜索——仅使用 MinHash 签名和 LSH,速度快但结果为概率近似。
-
精排搜索——基于原始 token 集合重新计算 Jaccard 相似度,精度更高。
5.1 准备查询
要执行相似度搜索,先为查询文档生成 MinHash 签名。该签名的维度和编码格式必须与写入数据时一致。
query_text = "neural networks model patterns in data"
query_sig = generate_minhash_signature(query_text)
5.2 近似搜索(仅使用 LSH)
这种方式快速且可扩展,但可能漏掉某些近似匹配或产生误判:
# highlight-start
search_params={
"metric_type": "MHJACCARD",
"params": {}
}
# highlight-end
approx_results = client.search(
collection_name="minhash_demo",
data=[query_sig],
anns_field="minhash_signature",
# highlight-next-line
search_params=search_params,
limit=3,
output_fields=["doc_id", "document"],
consistency_level="Strong"
)
for i, hit in enumerate(approx_results[0]):
sim = 1 - hit['distance']
print(f"{i+1}. Similarity: {sim:.3f} | {hit['entity']['document']}")
5.3 精排搜索(推荐用于追求精度的场景)
这种方式基于存储在 Zilliz Cloud 中的原始 token 集合进行精确的 Jaccard 比较。速度略慢,但适用于对结果质量要求较高的任务:
# highlight-start
search_params = {
"metric_type": "MHJACCARD",
"params": {
"mh_search_with_jaccard": True, # Enable real Jaccard computation
"refine_k": 5 # Refine top 5 candidates
}
}
# highlight-end
refined_results = client.search(
collection_name="minhash_demo",
data=[query_sig],
anns_field="minhash_signature",
# highlight-next-line
search_params=search_params,
limit=3,
output_fields=["doc_id", "document"],
consistency_level="Strong"
)
for i, hit in enumerate(refined_results[0]):
sim = 1 - hit['distance']
print(f"{i+1}. Similarity: {sim:.3f} | {hit['entity']['document']}")
索引参数{#}
本节介绍构建索引以及在该索引上执行搜索时所使用的参数。
索引构建参数{#}
下表列出了在构建索引时可以在 params 中配置的参数。
参数 | 说明 | 取值范围 | 调优建议 |
|---|---|---|---|
| MinHash 签名中每个哈希值的位宽。必须是 8 的倍数。 | 8、16、32、64 | 使用 32 在性能和精度之间取得平衡。对于大规模数据集,使用 64 可获得更高的精度。如需节省内存且可接受一定精度损失,可使用 16。 |
| LSH 中划分 MinHash 签名所使用的 band 数量。用于控制召回率与性能之间的权衡。 | [1, signature_length] | 对于 128 维签名:建议从 32 个 band(每个 band 4 个值)开始;增加到 64 可提高召回率,减少到 16 可获得更好的性能。该值必须能整除签名长度。 |
| 是否将 LSH 哈希码存储于匿名内存中(true),或使用内存映射(false)。 | true、false | 对于大规模数据集(>1M 集合),使用 false 以降低内存占用。对于需要极致搜索速度的小规模数据集,使用 true。 |
| 是否将原始 MinHash 签名与 LSH 哈希码一同存储以支持精排。 | true、false | 当对精度要求较高且能接受额外存储开销时,使用 true。当希望以轻微精度损失换取更低存储开销时,使用 false。 |
| 用于 LSH 桶优化的布隆过滤器的误判率。 | [0.001, 0.1] | 使用 0.01 在内存占用与精度之间取得平衡。较低的值(0.001)可减少误判,但会增加内存开销;较高的值(0.05)可节省内存,但可能降低精度。 |
索引相关搜索参数{#}
下表列出了在基于该索引执行搜索时可在 search_params.params 中配置的参数。
参数 | 说明 | 取值范围 | 调优建议 |
|---|---|---|---|
| 是否对候选结果执行精确的 Jaccard 相似度计算以进行精排。 | true、false | 对于精度要求高的应用(如去重),使用 true。当可以接受一定精度损失以换取更快的近似搜索时,使用 false。 |
| 在执行 Jaccard 精排前要检索的候选数量。仅在 mh_search_with_jaccard 为 true 时生效。 | [top_k, top_k * 10] | 建议设为目标 top_k 的 2-5 倍,以兼顾召回率和性能。该值越大召回越好,但计算成本也越高。 |
| 是否在多个查询并发执行时启用批量优化。 | true、false | 同时执行多个查询时使用 true 以获得更高的吞吐。单查询场景下使用 false 以降低内存开销。 |