快速开始
本指南演示如何使用 Zilliz Cloud 集群高效执行语义检索的相关操作。
开始前
Zilliz Cloud 提供 BYOC 解决方案,允许组织在自己的云账户中托管应用程序和数据,从而避免使用 Zilliz Cloud 的基础设施。有关我们 BYOC 解决方案的详细信息,请阅读 BYOC 简介 。
下图展示了使用 Zilliz Cloud BYOC 方案的具体步骤。
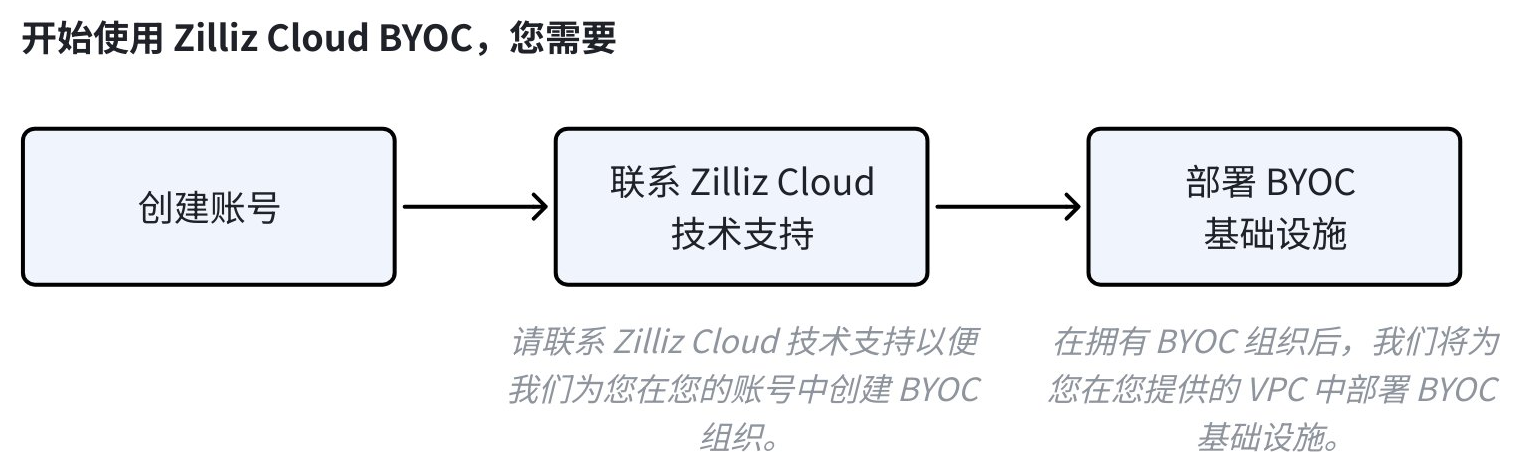
在使用本指南前,请确保
-
详情见注册账号。
-
您已经联系了 Zilliz Cloud 技术支持并向我们提供您的账号信息。
📘说明Zilliz BYOC 部署方案目前处于正式可用阶段。如需了解详情或试用,请联系 Zilliz Cloud 技术支持。
-
您的 BYOC 组织和项目均已就绪。
如下步骤假设您已经创建了 Zilliz Cloud 集群,获取了可以访问该集群的 API Key 或鉴权凭据,并安装了相关 SDK。
建立连接
获取集群凭证或 API 密钥后,您可以通过以下示例代码连接到。
- Python
- Java
- Go
- NodeJS
- cURL
from pymilvus import MilvusClient, DataType
CLUSTER_ENDPOINT = "YOUR_CLUSTER_ENDPOINT"
TOKEN = "YOUR_CLUSTER_TOKEN"
# A valid token could be either
# - An API key, or
# - A colon-joined cluster username and password, as in `user:pass`
# 1. Set up a Milvus client
client = MilvusClient(
uri=CLUSTER_ENDPOINT,
token=TOKEN
)
import io.milvus.v2.client.MilvusClientV2;
import io.milvus.v2.client.ConnectConfig;
String CLUSTER_ENDPOINT = "YOUR_CLUSTER_ENDPOINT";
String TOKEN = "YOUR_CLUSTER_TOKEN";
// A valid token could be either
// - An API key, or
// - A colon-joined cluster username and password, as in `user:pass`
// 1. Connect to Milvus server
ConnectConfig connectConfig = ConnectConfig.builder()
.uri(CLUSTER_ENDPOINT)
.token(TOKEN)
.build();
MilvusClientV2 client = new MilvusClientV2(connectConfig);
import (
"context"
"fmt"
"github.com/milvus-io/milvus/client/v2/entity"
"github.com/milvus-io/milvus/client/v2/index"
"github.com/milvus-io/milvus/client/v2/milvusclient"
"github.com/milvus-io/milvus/pkg/v2/common"
)
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
milvusAddr := "YOUR_CLUSTER_ENDPOINT"
APIKey := "YOUR_API_KEY"
// Or you can use the cluster credentials to authenticate
// Username := "YOUR_CLUSTER_USERNAME"
// Password := "YOUR_CLUSTER_PASSWORD"
client, err := milvusclient.New(ctx, &milvusclient.ClientConfig{
Address: milvusAddr,
APIKey: APIKey
})
if err != nil {
fmt.Println(err.Error())
// handle error
}
defer client.Close(ctx)
const { MilvusClient, DataType, sleep } = require("@zilliz/milvus2-sdk-node")
const address = "YOUR_CLUSTER_ENDPOINT"
const token = "YOUR_CLUSTER_TOKEN"
// A valid token could be either
// - An API key, or
// - A colon-joined cluster username and password, as in `user:pass`
// 1. Connect to the cluster
const client = new MilvusClient({address, token})
export CLUSTER_ENDPOINT="YOUR_CLUSTER_ENDPOINT"
export CLUSTER_TOKEN="YOUR_CLUSTER_TOKEN"
# A valid token could be either
# - An API key, or
# - A colon-joined cluster username and password, as in `user:pass`
创建 collection
在 , 您需要将向量数据存储到 collection 中。同一个 collection 中的向量数据具有相同的维度和相似度测量指标。
在创建 collection 时,您需要详细定义每个字段的属性,如字段名称、数据类型和其他属性。另外,您还可以选择为需要加速检索的字段创建索引。其中,向量字段必须创建索引。
- Python
- Java
- Go
- NodeJS
- cURL
# 3. Create a collection in customized setup mode
# 3.1. Create schema
schema = MilvusClient.create_schema(
auto_id=False,
enable_dynamic_field=True,
)
# 3.2. Add fields to schema
schema.add_field(field_name="my_id", datatype=DataType.INT64, is_primary=True)
schema.add_field(field_name="my_vector", datatype=DataType.FLOAT_VECTOR, dim=5)
# 3.3. Prepare index parameters
index_params = client.prepare_index_params()
# 3.4. Add indexes
index_params.add_index(
field_name="my_id"
)
index_params.add_index(
field_name="my_vector",
index_type="AUTOINDEX",
metric_type="IP"
)
# 3.5. Create a collection
client.create_collection(
collection_name="custom_setup",
schema=schema,
index_params=index_params
)
import io.milvus.v2.service.collection.request.AddFieldReq;
import io.milvus.v2.common.DataType;
import io.milvus.v2.common.IndexParam;
import io.milvus.v2.service.collection.request.CreateCollectionReq;
// 3.1 Create schema
CreateCollectionReq.CollectionSchema schema = client.createSchema();
// 3.2 Add fields to schema
AddFieldReq myId = AddFieldReq.builder()
.fieldName("my_id")
.dataType(DataType.Int64)
.isPrimaryKey(true)
.autoID(false)
.build();
schema.addField(myId);
AddFieldReq myVector = AddFieldReq.builder()
.fieldName("my_vector")
.dataType(DataType.FloatVector)
.dimension(5)
.build();
schema.addField(myVector);
// 3.3 Prepare index parameters
IndexParam indexParamForIdField = IndexParam.builder()
.fieldName("my_id")
.indexType(IndexParam.IndexType.STL_SORT)
.build();
IndexParam indexParamForVectorField = IndexParam.builder()
.fieldName("my_vector")
.indexType(IndexParam.IndexType.AUTOINDEX)
.metricType(IndexParam.MetricType.IP)
.build();
List<IndexParam> indexParams = new ArrayList<>();
indexParams.add(indexParamForIdField);
indexParams.add(indexParamForVectorField);
// 3.4 Create a collection with schema and index parameters
CreateCollectionReq customizedSetupReq = CreateCollectionReq.builder()
.collectionName("custom_setup")
.collectionSchema(schema)
.indexParams(indexParams)
.build();
client.createCollection(customizedSetupReq);
// add fields
schema := entity.NewSchema().WithDynamicFieldEnabled(true).
WithField(entity.NewField().WithName("my_id").WithIsAutoID(false).WithDataType(entity.FieldTypeInt64).WithIsPrimaryKey(true)).
WithField(entity.NewField().WithName("my_vector").WithDataType(entity.FieldTypeFloatVector).WithDim(5))
// set index options
indexOptions := []milvusclient.CreateIndexOption{
milvusclient.NewCreateIndexOption(collectionName, "my_vector", index.NewAutoIndex(entity.COSINE)),
milvusclient.NewCreateIndexOption(collectionName, "my_id", index.NewAutoIndex(entity.COSINE)),
}
// create collection
err = client.CreateCollection(ctx, milvusclient.NewCreateCollectionOption("custom_setup", schema).
WithIndexOptions(indexOptions...))
if err != nil {
fmt.Println(err.Error())
// handle error
}
fmt.Println("collection created")
// 3. Create a collection in customized setup mode
// 3.1 Define fields
const fields = [
{
name: "my_id",
data_type: DataType.Int64,
is_primary_key: true,
auto_id: false
},
{
name: "my_vector",
data_type: DataType.FloatVector,
dim: 5
},
]
// 3.2 Prepare index parameters
const index_params = [{
field_name: "my_vector",
index_type: "AUTOINDEX",
metric_type: "IP"
}]
// 3.3 Create a collection with fields and index parameters
await client.createCollection({
collection_name: "custom_setup",
fields: fields,
index_params: index_params,
})
COLLECTION_NAME="customized_setup"
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/collections/create" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Accept: application/json" \
--header "Content-Type: application/json" \
-d '{
"collectionName": "custom_setup",
"schema": {
"autoId": false,
"enabledDynamicField": false,
"fields": [
{
"fieldName": "my_id",
"dataType": "Int64",
"isPrimary": true
},
{
"fieldName": "my_vector",
"dataType": "FloatVector",
"elementTypeParams": {
"dim": "5"
}
}
]
}
}'
# {"code":200,"data":{}}
通过以上代码,您可以自由定义 collection 的各项属性,包括 schema 和索引参数等。
-
Schema
Schema 决定了 collection 的结构。除了上述代码添加的预定义字段外,您还可以启用或禁用以下功能:
-
Auto ID
是否自动递增 collection 的主键值。
-
Dynamic Field
是否使用保留 JSON 字段 $meta 来存储在 schema 中未定义的字段和字段值。
有关更多信息,请参阅了解 Schema。
-
-
索引参数
索引参数将定义 Zilliz Cloud 如何处理 collection 中的数据。您可以为字段设置特定的索引类型和度量类型。
-
向量字段可以选择 AUTOINDEX 作为索引类型,并采用 COSINE、L2或 IP 作为度量类型(
metric_type)。 -
标量字段,如主键字段,整数型使用 TRIE,字符串类型使用 STL_SORT。
有关更多信息,请参阅 AUTOINDEX。
-
通过上述代码创建的 collection 将自动加载(load)。如需管理非自动加载的 collection,请参阅创建 Collection。
通过 RESTful API 创建的 collection 会自动完成加载(load)。
插入数据
在准备好 collection 后,您可以参考如下示例向其中插入数据。
- Python
- Java
- Go
- NodeJS
- cURL
# 4. Insert data into the collection
# 4.1. Prepare data
data=[
{"id": 0, "vector": [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592], "color": "pink_8682"},
{"id": 1, "vector": [0.19886812562848388, 0.06023560599112088, 0.6976963061752597, 0.2614474506242501, 0.838729485096104], "color": "red_7025"},
{"id": 2, "vector": [0.43742130801983836, -0.5597502546264526, 0.6457887650909682, 0.7894058910881185, 0.20785793220625592], "color": "orange_6781"},
{"id": 3, "vector": [0.3172005263489739, 0.9719044792798428, -0.36981146090600725, -0.4860894583077995, 0.95791889146345], "color": "pink_9298"},
{"id": 4, "vector": [0.4452349528804562, -0.8757026943054742, 0.8220779437047674, 0.46406290649483184, 0.30337481143159106], "color": "red_4794"},
{"id": 5, "vector": [0.985825131989184, -0.8144651566660419, 0.6299267002202009, 0.1206906911183383, -0.1446277761879955], "color": "yellow_4222"},
{"id": 6, "vector": [0.8371977790571115, -0.015764369584852833, -0.31062937026679327, -0.562666951622192, -0.8984947637863987], "color": "red_9392"},
{"id": 7, "vector": [-0.33445148015177995, -0.2567135004164067, 0.8987539745369246, 0.9402995886420709, 0.5378064918413052], "color": "grey_8510"},
{"id": 8, "vector": [0.39524717779832685, 0.4000257286739164, -0.5890507376891594, -0.8650502298996872, -0.6140360785406336], "color": "white_9381"},
{"id": 9, "vector": [0.5718280481994695, 0.24070317428066512, -0.3737913482606834, -0.06726932177492717, -0.6980531615588608], "color": "purple_4976"}
]
# 4.2. Insert data
res = client.insert(
collection_name="custom_setup",
data=data
)
print(res)
# Output
#
# {
# "insert_count": 10,
# "ids": [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# }
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.Arrays;
import com.alibaba.fastjson.JSONObject;
import io.milvus.v2.service.vector.request.InsertReq;
import io.milvus.v2.service.vector.response.InsertResp;
// 4. Insert data into the collection
// 4.1. Prepare data
List<JSONObject> insertData = Arrays.asList(
new JSONObject(Map.of("id", 0L, "vector", Arrays.asList(0.3580376395471989f, -0.6023495712049978f, 0.18414012509913835f, -0.26286205330961354f, 0.9029438446296592f), "color", "pink_8682")),
new JSONObject(Map.of("id", 1L, "vector", Arrays.asList(0.19886812562848388f, 0.06023560599112088f, 0.6976963061752597f, 0.2614474506242501f, 0.838729485096104f), "color", "red_7025")),
new JSONObject(Map.of("id", 2L, "vector", Arrays.asList(0.43742130801983836f, -0.5597502546264526f, 0.6457887650909682f, 0.7894058910881185f, 0.20785793220625592f), "color", "orange_6781")),
new JSONObject(Map.of("id", 3L, "vector", Arrays.asList(0.3172005263489739f, 0.9719044792798428f, -0.36981146090600725f, -0.4860894583077995f, 0.95791889146345f), "color", "pink_9298")),
new JSONObject(Map.of("id", 4L, "vector", Arrays.asList(0.4452349528804562f, -0.8757026943054742f, 0.8220779437047674f, 0.46406290649483184f, 0.30337481143159106f), "color", "red_4794")),
new JSONObject(Map.of("id", 5L, "vector", Arrays.asList(0.985825131989184f, -0.8144651566660419f, 0.6299267002202009f, 0.1206906911183383f, -0.1446277761879955f), "color", "yellow_4222")),
new JSONObject(Map.of("id", 6L, "vector", Arrays.asList(0.8371977790571115f, -0.015764369584852833f, -0.31062937026679327f, -0.562666951622192f, -0.8984947637863987f), "color", "red_9392")),
new JSONObject(Map.of("id", 7L, "vector", Arrays.asList(-0.33445148015177995f, -0.2567135004164067f, 0.8987539745369246f, 0.9402995886420709f, 0.5378064918413052f), "color", "grey_8510")),
new JSONObject(Map.of("id", 8L, "vector", Arrays.asList(0.39524717779832685f, 0.4000257286739164f, -0.5890507376891594f, -0.8650502298996872f, -0.6140360785406336f), "color", "white_9381")),
new JSONObject(Map.of("id", 9L, "vector", Arrays.asList(0.5718280481994695f, 0.24070317428066512f, -0.3737913482606834f, -0.06726932177492717f, -0.6980531615588608f), "color", "purple_4976"))
);
// 4.2. Insert data
InsertReq insertReq = InsertReq.builder()
.collectionName("custom_setup")
.data(insertData)
.build();
InsertResp res = client.insert(insertReq);
System.out.println(JSONObject.toJSON(res));
// Output:
// {"insertCnt": 10}
dynamicColumn := column.NewColumnString("color", []string{
"pink_8682", "red_7025", "orange_6781", "pink_9298", "red_4794", "yellow_4222", "red_9392", "grey_8510", "white_9381", "purple_4976",
})
_, err = client.Insert(ctx, milvusclient.NewColumnBasedInsertOption("custom_setup").
WithInt64Column("id", []int64{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}).
WithFloatVectorColumn("vector", 5, [][]float32{
{0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592},
{0.19886812562848388, 0.06023560599112088, 0.6976963061752597, 0.2614474506242501, 0.838729485096104},
{0.43742130801983836, -0.5597502546264526, 0.6457887650909682, 0.7894058910881185, 0.20785793220625592},
{0.3172005263489739, 0.9719044792798428, -0.36981146090600725, -0.4860894583077995, 0.95791889146345},
{0.4452349528804562, -0.8757026943054742, 0.8220779437047674, 0.46406290649483184, 0.30337481143159106},
{0.985825131989184, -0.8144651566660419, 0.6299267002202009, 0.1206906911183383, -0.1446277761879955},
{0.8371977790571115, -0.015764369584852833, -0.31062937026679327, -0.562666951622192, -0.8984947637863987},
{-0.33445148015177995, -0.2567135004164067, 0.8987539745369246, 0.9402995886420709, 0.5378064918413052},
{0.39524717779832685, 0.4000257286739164, -0.5890507376891594, -0.8650502298996872, -0.6140360785406336},
{0.5718280481994695, 0.24070317428066512, -0.3737913482606834, -0.06726932177492717, -0.6980531615588608},
}).
WithColumns(dynamicColumn),
)
if err != nil {
fmt.Println(err.Error())
// handle err
}
// 4. Insert data into the collection
var data = [
{id: 0, vector: [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592], color: "pink_8682"},
{id: 1, vector: [0.19886812562848388, 0.06023560599112088, 0.6976963061752597, 0.2614474506242501, 0.838729485096104], color: "red_7025"},
{id: 2, vector: [0.43742130801983836, -0.5597502546264526, 0.6457887650909682, 0.7894058910881185, 0.20785793220625592], color: "orange_6781"},
{id: 3, vector: [0.3172005263489739, 0.9719044792798428, -0.36981146090600725, -0.4860894583077995, 0.95791889146345], color: "pink_9298"},
{id: 4, vector: [0.4452349528804562, -0.8757026943054742, 0.8220779437047674, 0.46406290649483184, 0.30337481143159106], color: "red_4794"},
{id: 5, vector: [0.985825131989184, -0.8144651566660419, 0.6299267002202009, 0.1206906911183383, -0.1446277761879955], color: "yellow_4222"},
{id: 6, vector: [0.8371977790571115, -0.015764369584852833, -0.31062937026679327, -0.562666951622192, -0.8984947637863987], color: "red_9392"},
{id: 7, vector: [-0.33445148015177995, -0.2567135004164067, 0.8987539745369246, 0.9402995886420709, 0.5378064918413052], color: "grey_8510"},
{id: 8, vector: [0.39524717779832685, 0.4000257286739164, -0.5890507376891594, -0.8650502298996872, -0.6140360785406336], color: "white_9381"},
{id: 9, vector: [0.5718280481994695, 0.24070317428066512, -0.3737913482606834, -0.06726932177492717, -0.6980531615588608], color: "purple_4976"}
]
res = await client.insert({
collection_name: "custom_setup",
data: data
})
console.log(res.insert_cnt)
// Output
//
// 10
curl -s --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/insert" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Accept: application/json" \
--header "Content-Type: application/json" \
-d '{
"collectionName": "custom_setup",
"data": [
{"vector": [0.3847391566891949, -0.5163308707041789, -0.5295937262122905, -0.3592193314357348, 0.9108593166893231], "color": "grey_4070"},
{"vector": [-0.3909198248479646, -0.8726174312444843, 0.4981267572657442, -0.9392508698102204, -0.5470572556090092], "color": "black_3737"},
{"vector": [-0.9098169905660276, -0.9307025336058208, -0.5308685343695865, -0.3852032359431963, -0.8050806646961366], "color": "yellow_7436"},
{"vector": [-0.05064204615748724, 0.6058571389881378, 0.26812302147792155, 0.4862225881265785, -0.27042586524166445], "color": "grey_9883"},
{"vector": [-0.8610792440629793, 0.5278969698864726, 0.09065723848982965, -0.8685651142668274, 0.5912780986996793], "color": "green_8111"},
{"vector": [0.4814454540587043, -0.23573937400668377, -0.14938260011601723, 0.08275006479687019, 0.6726732239961157], "color": "orange_2725"},
{"vector": [0.9763298348098068, 0.5777919290849443, 0.9579310732153326, 0.8951091168874232, 0.46917481926682525], "color": "black_6073"},
{"vector": [0.326134221411539, 0.6870356809753577, 0.7977120714123429, 0.4305198158670587, -0.14894148480426983], "color": "purple_1285"},
{"vector": [0.8709056428858379, 0.021264532993509055, -0.8042932327188321, -0.007299919034885249, 0.14411861700299666], "color": "green_3127"},
{"vector": [-0.8182282159972083, -0.7882247281939101, -0.1870871133115657, 0.07914806834708976, 0.9825978431531959], "color": "blue_6372"}
]
}'
# {
# "code": 200,
# "data": {
# "insertCount": 10,
# "insertIds": [
# "448985546440864743",
# "448985546440864744",
# "448985546440864745",
# "448985546440864746",
# "448985546440864747",
# "448985546440864748",
# "448985546440864749",
# "448985546440864750",
# "448985546440864751",
# "448985546440864752"
# ]
# }
# }
假设您已通过快速创建的方式完成了 collection 创建。通过以上代码:
-
插入的数据为字典列表,每个字典代表一条数据记录,即 entity。
-
每个字典包含一个名为 color 的非 schema 定义字段。
-
每个字典包含与预定义和动态字段相对应的键值。
通过 RESTful API 创建的 collection 启用了 AutoID,因此插入数据时应跳过主键字段。
插入数据为异步操作。在插入数据后立即进行检索,检索结果可能为空。建议您在插入数据后等待一段时间。
相似性搜索(search)
您可以基于一条或多条向量 embedding 执行相似性搜索(search)。您还可以在搜索请求中携带过滤条件来增强搜索结果。
- Python
- Java
- Go
- NodeJS
- cURL
# 8. Search with a filter expression using schema-defined fields
# 1 Prepare query vectors
query_vectors = [
[0.041732933, 0.013779674, -0.027564144, -0.013061441, 0.009748648]
]
# 2. Start search
res = client.search(
collection_name="custom_setup",
data=query_vectors,
filter="4 < id < 8",
limit=3
)
print(res)
# Output
#
# [
# [
# {
# "id": 5,
# "distance": 0.08821295201778412,
# "entity": {}
# },
# {
# "id": 6,
# "distance": 0.07432225346565247,
# "entity": {}
# },
# {
# "id": 7,
# "distance": 0.07279646396636963,
# "entity": {}
# }
# ]
# ]
// 8. Search with a filter expression using schema-defined fields
List<List<Float>> filteredVectorSearchData = new ArrayList<>();
filteredVectorSearchData.add(Arrays.asList(0.041732933f, 0.013779674f, -0.027564144f, -0.013061441f, 0.009748648f));
searchReq = SearchReq.builder()
.collectionName("custom_setup")
.data(filteredVectorSearchData)
.filter("4 < id < 8")
.outputFields(Arrays.asList("id"))
.topK(3)
.build();
SearchResp filteredVectorSearchRes = client.search(searchReq);
System.out.println(JSONObject.toJSON(filteredVectorSearchRes));
// Output:
// {"searchResults": [[
// {
// "distance": 0.08821295,
// "id": 5,
// "entity": {"id": 5}
// },
// {
// "distance": 0.074322253,
// "id": 6,
// "entity": {"id": 6}
// },
// {
// "distance": 0.072796463,
// "id": 7,
// "entity": {"id": 7}
// }
// ]]}
queryVector := []float32{0.041732933, 0.013779674, -0.027564144, -0.013061441, 0.009748648}
resultSets, err := client.Search(ctx, milvusclient.NewSearchOption(
"custom_setup", // collectionName
3, // limit
[]entity.Vector{entity.FloatVector(queryVector)},
).WithConsistencyLevel(entity.ClStrong).
WithANNSField("vector").
WithFilter("4 < id < 8").
if err != nil {
fmt.Println(err.Error())
// handle error
}
for _, resultSet := range resultSets {
fmt.Println("IDs: ", resultSet.IDs.FieldData().GetScalars())
fmt.Println("Scores: ", resultSet.Scores)
}
// IDs: 5
// Scores: 0.08821295201778412
// IDs: 6
// Scores: 0.07432225346565247
// IDs: 7
// Scores: 0.07279646396636963
// 8. Search with a filter expression using schema-defined fields
res = await client.search({
collection_name: "custom_setup",
vectors: query_vector,
limit: 3,
filter: "4 < id < 8",
output_fields: ["id"]
})
console.log(res.results)
// Output
//
// [
// { score: 0.08821295201778412, id: '5' },
// { score: 0.07432225346565247, id: '6' },
// { score: 0.07279646396636963, id: '7' },
// ]
# 8. Conduct a single vector search
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/search" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Accept: application/json" \
--header "Content-Type: application/json" \
-d '{
"collectionName": "custom_setup",
"data": [
[0.3847391566891949, -0.5163308707041789, -0.5295937262122905, -0.3592193314357348, 0.9108593166893231]
],
"annsField": "vector",
"filter": "4 < id < 8",
"limit": 3
}'
# {
# "code": 200,
# "data": [
# {
# "distance": 0.08821295201778412,
# "id": 448985546440864743
# },
# {
# "distance": 0.07432225346565247,
# "id": 448985546440865160
# },
# {
# "distance": 0.07279646396636963,
# "id": 448985546440864927
# }
# ]
# }
输出结果为列表形式,内含三个字典类型的子列表。每个字典代表一个 entity,包括其 ID、相似距离和指定的输出字段。
您还可以在过滤表达式(filter)中加入动态字段(dynamic field)。以下代码示例中,color 是未在 schema 中定义的字段,可以通过 $meta 魔术字段的来访问,如 $meta["color"],或像其他 schema 中已定义字段那样直接使用,如 color。
- Python
- Java
- Go
- NodeJS
- cURL
# 9. Search with a filter expression using custom fields
# 9.1.Prepare query vectors
query_vectors = [
[0.041732933, 0.013779674, -0.027564144, -0.013061441, 0.009748648]
]
# 9.2.Start search
res = client.search(
collection_name="custom_setup",
data=query_vectors,
filter='$meta["color"] like "red%"',
limit=3,
output_fields=["color"]
)
print(res)
# Output
#
# [
# [
# {
# "id": 5,
# "distance": 0.08821295201778412,
# "entity": {
# "color": "yellow_4222"
# }
# },
# {
# "id": 6,
# "distance": 0.07432225346565247,
# "entity": {
# "color": "red_9392"
# }
# },
# {
# "id": 7,
# "distance": 0.07279646396636963,
# "entity": {
# "color": "grey_8510"
# }
# }
# ]
# ]
// 9. Search with a filter expression using custom fields
List<List<Float>> customFilteredVectorSearchData = new ArrayList<>();
customFilteredVectorSearchData.add(Arrays.asList(0.041732933f, 0.013779674f, -0.027564144f, -0.013061441f, 0.009748648f));
searchReq = SearchReq.builder()
.collectionName("custom_setup")
.data(customFilteredVectorSearchData)
.filter("$meta[\"color\"] like \"red%\"")
.topK(3)
.outputFields(Arrays.asList("color"))
.build();
SearchResp customFilteredVectorSearchRes = client.search(searchReq);
System.out.println(JSONObject.toJSON(customFilteredVectorSearchRes));
// Output:
// {"searchResults": [[
// {
// "distance": 0.08821295,
// "id": 5,
// "entity": {"color": "yellow_4222"}
// },
// {
// "distance": 0.074322253,
// "id": 6,
// "entity": {"color": "red_9392"}
// },
// {
// "distance": 0.072796463,
// "id": 7,
// "entity": {"color": "grey_8510"}
// }
// ]]}
queryVector := []float32{0.041732933, 0.013779674, -0.027564144, -0.013061441, 0.009748648}
resultSets, err := client.Search(ctx, milvusclient.NewSearchOption(
"my_collection", // collectionName
5, // limit
[]entity.Vector{entity.FloatVector(queryVector)},
).WithConsistencyLevel(entity.ClStrong).
WithANNSField("vector").
WithFilter("$meta[\"color\"] like \"red%\"").
WithOutputFields("color"))
if err != nil {
fmt.Println(err.Error())
// handle error
}
for _, resultSet := range resultSets {
fmt.Println("IDs: ", resultSet.IDs.FieldData().GetScalars())
fmt.Println("Scores: ", resultSet.Scores)
fmt.Println("color: ", resultSet.GetColumn("color").FieldData().GetScalars())
}
// IDs: 5
// Scores: 0.08821295201778412
// color: yellow_4222
// IDs: 6
// Scores: 0.07432225346565247
// color: red_9392
// IDs: 7
// Scores: 0.07279646396636963
// color: grey_8510
// 9. Search with a filter expression using non-schema-defined fields
res = await client.search({
collection_name: "custom_setup",
vectors: query_vector,
limit: 3,
filter: '$meta["color"] like "red%"',
output_fields: ["color"]
})
console.log(res.results)
// Output
//
// [
// { score: 0.08821295201778412, id: '5', color: 'yellow_4222' },
// { score: 0.07432225346565247, id: '6', color: 'red_9392' },
// { score: 0.07279646396636963, id: '7', color: 'grey_8510' },
// ]
//
# 9. Conduct a single vector search with filters and output fields
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/search" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Accept: application/json" \
--header "Content-Type: application/json" \
-d '{
"collectionName": "custom_setup",
"data": [
[0.3847391566891949, -0.5163308707041789, -0.5295937262122905, -0.3592193314357348, 0.9108593166893231]
],
"annsField": "vector",
"filter": "color like \"red%\"",
"outputFields": ["color"],
"limit": 3
}'
# {
# "code": 200,
# "data": [
# {
# "color": "yellow_4222",
# "distance": 0.08821295201778412
# },
# {
# "color": "red_9392",
# "distance": 0.07432225346565247
# },
# {
# "color": "grey_8510",
# "distance": 0.07279646396636963
# }
# ]
# }
删除 entity
您可以通过 ID 或过滤表达式删除 entity。
-
Delete entities by IDs.
- Python
- Java
- Go
- NodeJS
- cURL
# 13. Delete entities by IDs
res = client.delete(
collection_name="custom_setup",
ids=[0,1,2,3,4]
)
print(res)
# Output
#
# {
# "delete_count": 5
# }import io.milvus.v2.service.vector.request.DeleteReq;
import io.milvus.v2.service.vector.response.DeleteResp;
// 13. Delete entities by IDs
DeleteReq deleteReq = DeleteReq.builder()
.collectionName("custom_setup")
.ids(Arrays.asList(0L, 1L, 2L, 3L, 4L))
.build();
DeleteResp deleteRes = client.delete(deleteReq);
System.out.println(JSONObject.toJSON(deleteRes));
// Output:
// {"deleteCnt": 5}_, err = client.Delete(ctx, milvusclient.NewDeleteOption("quick_setup").
WithInt64IDs("id", []int64{0, 1, 2, 3, 4}))
if err != nil {
fmt.Println(err.Error())
// handle err
}// 13. Delete entities by IDs
res = await client.deleteEntities({
collection_name: "custom_setup",
expr: "id in [5, 6, 7, 8, 9]",
output_fields: ["vector"]
})
console.log(res.delete_cnt)
// Output
//
// 5
//# 12. Delete entities by IDs
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/delete" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Accept: application/json" \
--header "Content-Type: application/json" \
-d '{
"collectionName": "medium_articles",
"filter": "id == 4321034832910"
}'
# {"code":200,"data":{}} -
通过过滤表达式删除 entity
- Python
- Java
- Go
- NodeJS
- cURL
# 14. Delete entities by a filter expression
res = client.delete(
collection_name="custom_setup",
filter="id in [5,6,7,8,9]"
)
print(res)
# Output
#
# {
# "delete_count": 5
# }// 14. Delete entities by filter
DeleteReq filterDeleteReq = DeleteReq.builder()
.collectionName("custom_setup")
.filter("id in [5, 6, 7, 8, 9]")
.build();
DeleteResp filterDeleteRes = client.delete(filterDeleteReq);
System.out.println(JSONObject.toJSON(filterDeleteRes));
// Output:
// {"deleteCnt": 5}_, err = client.Delete(ctx, milvusclient.NewDeleteOption("custom_setup").
WithExpr("id in [5, 6, 7, 8, 9]"))
if err != nil {
fmt.Println(err.Error())
// handle err
}// 14. Delete entities by filter
res = await client.delete({
collection_name: "custom_setup",
ids: [0, 1, 2, 3, 4]
})
console.log(res.delete_cnt)
// Output
//
// 5
//# 12. Delete entities by IDs
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/delete" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Accept: application/json" \
--header "Content-Type: application/json" \
-d '{
"collectionName": "medium_articles",
"filter": "id in [5, 6, 7, 8, 9]"
}'
# {"code":200,"data":{}}📘说明目前,RESTful API 的 delete 接口暂不支持过滤表达式。
删除 collection
本指南完成后,您可以如下操作来删除 collection:
- Python
- Java
- Go
- NodeJS
- cURL
# 15. Drop collection
client.drop_collection(
collection_name="custom_setup"
)
client.drop_collection(
collection_name="customized_setup"
)
import io.milvus.v2.service.collection.request.DropCollectionReq;
// 15. Drop collections
DropCollectionReq dropQuickSetupParam = DropCollectionReq.builder()
.collectionName("custom_setup")
.build();
client.dropCollection(dropQuickSetupParam);
DropCollectionReq dropCustomizedSetupParam = DropCollectionReq.builder()
.collectionName("custom_setup")
.build();
client.dropCollection(dropCustomizedSetupParam);
err = client.DropCollection(ctx, milvusclient.NewDropCollectionOption("custom_setup"))
if err != nil {
fmt.Println(err.Error())
// handle error
}
// 15. Drop the collection
res = await client.dropCollection({
collection_name: "custom_setup"
})
console.log(res.error_code)
// Output
//
// Success
//
res = await client.dropCollection({
collection_name: "customized_setup"
})
console.log(res.error_code)
// Output
//
// Success
//
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/collections/drop" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Accept: application/json" \
--header "Content-Type: application/json" \
--data-raw '{
"collectionName": "custom_setup"
}'
# {"code":200,"data":{}}
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/collections/drop" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Accept: application/json" \
--header "Content-Type: application/json" \
--data-raw '{
"collectionName": "customized_setup"
}'
# {"code":200,"data":{}}
总结
-
在创建 collection 前,您需要为 collection 定义 schema,和各字段的相关配置。
-
插入数据可能需要些时间,因此建议在插入数据后等待几秒钟再进行相似性搜索。
-
过滤表达式同时适用于搜索(search)和查询(query)请求,但在查询(query)请求时必须使用。