Upsert Entity
使用 upsert 操作可以方便地在 Collection 中插入或更新 Entity。
概述
您可以使用 upsert 操作来插入新 Entity 或更新现有 Entity,具体取决于该请求中提供的主键是否存在于 Collection 中。如果未找到主键,则执行插入操作。否则,将执行更新操作。
Milvus中的插入更新操作可以在覆盖或合并模式下工作。
在覆盖模式下进行 Upsert
以覆盖模式工作的插入更新请求。当收到针对现有 Entity 的 upsert 请求时,Zilliz Cloud 会插入请求负载中携带的数据,同时删除数据中指定的具有原始主键的现有 Entity。
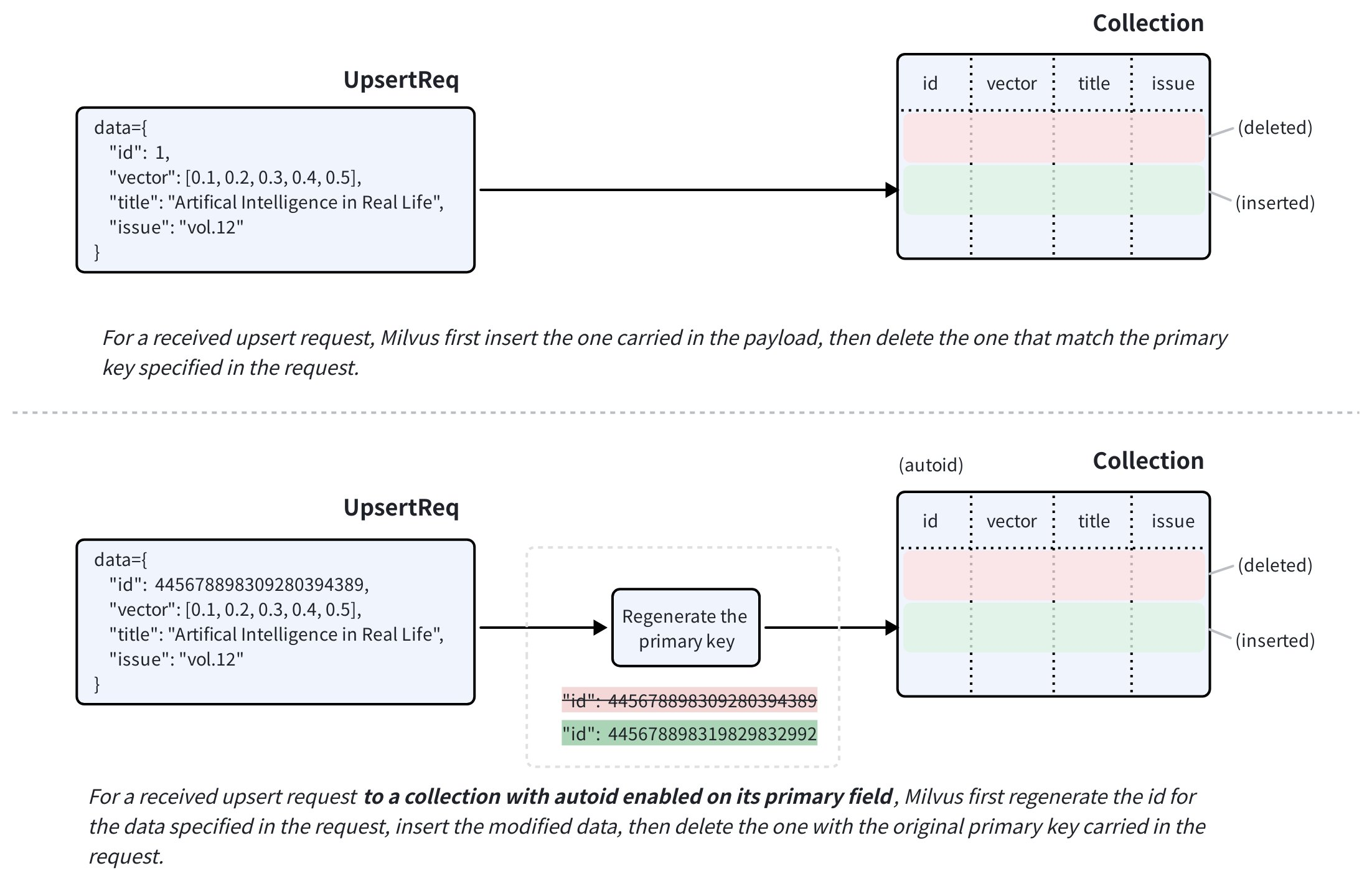
如果目标 Collection 在其主键字段上启用了 AutoID,Zilliz Cloud 将在插入请求负载中携带的数据之前为其生成一个新的主键。
对于启用了允许为空的字段,如果不需要更新,则可以在 upsert 请求中省略它们。
在合并模式下进行 Upsert
您还可以使用 partial_update 标志,使 upsert 请求以合并模式工作。这允许您仅在请求负载中包含需要更新的字段。
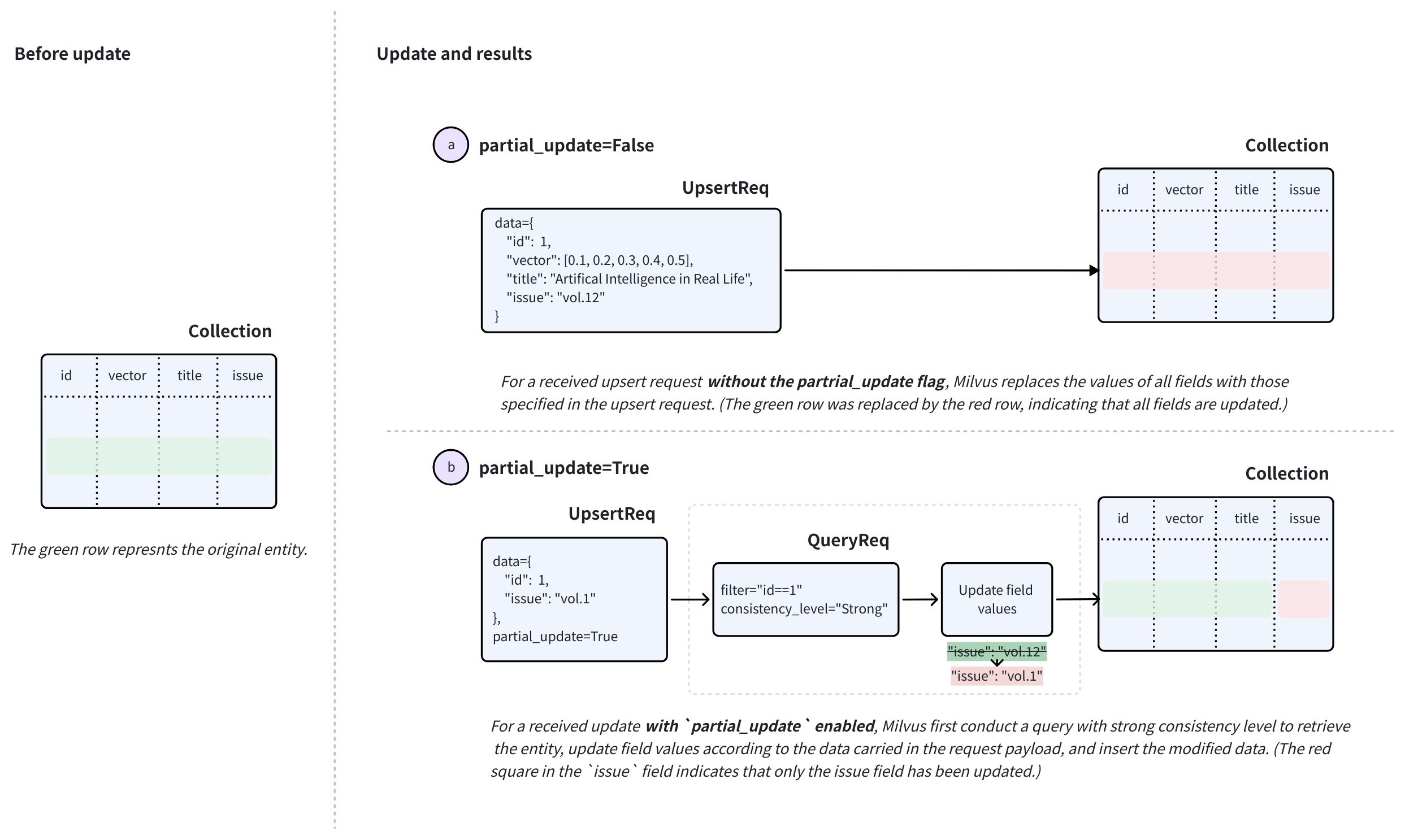
若要执行合并操作,请在 upsert 中将 partial_update 设置为True 并在请求中指定主键和要更新的字段以及它们的值。
收到此类请求后,Zilliz Cloud 会执行强一致性查询以检索 Entity,根据请求中的数据更新字段值,插入修改后的数据,然后删除请求中携带的具有原始主键的现有 Entity。
对于 ARRAY 字段,合并模式还支持两个操作符:ARRAY_APPEND 和 ARRAY_REMOVE。它们允许您直接向现有 ARRAY 字段追加元素,或从现有 ARRAY 字段中移除匹配的元素,而无需先查询 Entity 来获取当前字段值。有关详细信息和代码示例,请参阅使用部分更新操作符对 ARRAY 字段执行 Upsert。
更新字段值
如需更新已有 Entity 的字段值,请使用合并模式下的 upsert 操作。在该模式下,仅请求中包含的字段会被更新,其余字段保持原值不变。
Upsert 的行为:特别说明
在使用合并功能之前,您应该考虑以下几个特别注意事项。以下情况假设您有一个 Collection,其中包含两个标量字段,分别名为标题和问题,以及一个主键id和一个名为向量的向量字段。
-
更新插入字段,允许为空已启用。
假设
issue字段可以为空。当您更新插入这些字段时,请注意:-
如果您在
upsert请求中省略issue字段并禁用partial_update,则issue字段将更新为null,而不是保留其原始值。 -
要保留
issue字段的原始值,您需要启用partial_update并省略issue字段,或者在upsert请求中包含带有其原始值的issue字段。
-
-
在 Dynamic Field 中更新插入键。
假设您已在示例 Collection 中启用 Dynamic Field,并且 Entity Dynamic Field中的键值对类似于
{"author": "John", "year": 2020, "tags": ["fiction"]}。当你使用键(如
author、year或tags)更新插入 Entity,或添加其他键时,请注意:-
如果在禁用
partial_update的情况下进行upsert操作,默认行为是覆盖。这意味着 Dynamic Field 的值将被请求中包含的所有非模式定义字段及其值覆盖。例如,如果请求中包含的数据是
{"author": "Jane", "genre": "fantasy"},则目标 Entity Dynamic Field中的键值对将更新为该数据。 -
如果在启用
partial_update的情况下进行插入或更新操作,默认行为是合并。这意味着Dynamic Field的值将与请求中包含的所有非模式定义字段及其值进行合并。例如,如果请求中包含的数据是
{"author": "John", "year": 2020, "tags": ["fiction"]},则目标 Entity Dynamic Field 中的键值对在插入更新后将变为{"author": "Jane", "year": 2020, "tags": ["fiction"], "genre": "fantasy"}。
-
-
更新插入一个 JSON 字段。
假设示例 Collection 有一个名为
extras的 JSON 字段,并且 Entity 的这个 JSON 字段中的键值对类似于{"author": "John", "year": 2020, "tags": ["fiction"]}。当您使用修改后的JSON数据更新 Entity 的
extras字段时,请注意:-
如果在禁用
partial_update的情况下进行插入或更新操作,默认行为是覆盖。这意味着请求中包含的JSON字段的值将覆盖目标 Entity 的 JSON 字段的原始值。例如,如果请求中包含的数据是
{extras: {"author": "Jane", "genre": "fantasy"}},则目标Entity 的extras字段中的键值对将更新为{"author": "Jane", "genre": "fantasy"}。 -
如果在启用
partial_update的情况下进行upsert操作,默认行为是合并。这意味着请求中包含的JSON 字段的值将与目标 Entity 的 JSON 字段的原始值合并。例如,如果请求中包含的数据是
{extras: {"author": "Jane", "genre": "fantasy"}},则更新后目标 Entity 的extras字段中的键值对将变为{"author": "Jane", "year": 2020, "tags": ["fiction"], "genre": "fantasy"}。
-
-
Upsert
ARRAY字段。默认情况下,
ARRAY字段在合并模式下遵循 REPLACE 语义:请求中携带的值会完整覆盖现有数组。如需进行更细粒度的更新,Milvus 还支持两个操作符:-
ARRAY_APPEND将请求载荷中的元素追加到现有数组中。 -
ARRAY_REMOVE从现有数组中移除与请求载荷中的值匹配的所有元素。
使用任一操作符都会隐式启用部分更新语义;您无需额外将
partial_update设置为True。有关操作符语法、支持的元素类型和其他限制,请参阅使用部分更新操作符对 ARRAY 字段执行 Upsert。 -
限制与约束
根据上述内容,有若干限制和约束需要遵循:
-
upsert请求必须始终包含目标 Entity 的主键。 -
目标 Collection 必须已加载且可用于查询。
-
请求中指定的所有字段必须存在于目标 Collection 的 Schema 中。
-
请求中指定的所有字段的值必须与 Schema 中定义的数据类型相匹配。
-
对于任何使用 Function 从其他字段派生而来的字段,Zilliz Cloud 将在
upsert期间移除派生字段,以便重新计算。
在 Collection 中 Upsert Entity
在本节中,我们将向名为my_collection的 Collection 中 Upsert Entity 。这个 Collection 只有两个字段,分别名为id、vector、title和issue。id字段是主键字段,而title和issue字段是标量字段。
如果 Collection 中存在这三个实体,它们将被包含在更新插入请求中的实体覆盖。
- Python
- Java
- NodeJS
- Go
- cURL
from pymilvus import MilvusClient
client = MilvusClient(
uri="https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530",
token="YOUR_CLUSTER_TOKEN"
)
data=[
{
"id": 0,
"vector": [-0.619954382375778, 0.4479436794798608, -0.17493894838751745, -0.4248030059917294, -0.8648452746018911],
"title": "Artificial Intelligence in Real Life",
"issue": "vol.12"
}, {
"id": 1,
"vector": [0.4762662251462588, -0.6942502138717026, -0.4490002642657902, -0.628696575798281, 0.9660395877041965],
"title": "Hollow Man",
"issue": "vol.19"
}, {
"id": 2,
"vector": [-0.8864122635045097, 0.9260170474445351, 0.801326976181461, 0.6383943392381306, 0.7563037341572827],
"title": "Treasure Hunt in Missouri",
"issue": "vol.12"
}
]
res = client.upsert(
collection_name='my_collection',
data=data
)
print(res)
# Output
# {'upsert_count': 3}
import com.google.gson.Gson;
import com.google.gson.JsonObject;
import io.milvus.v2.client.ConnectConfig;
import io.milvus.v2.client.MilvusClientV2;
import io.milvus.v2.service.vector.request.UpsertReq;
import io.milvus.v2.service.vector.response.UpsertResp;
import java.util.*;
MilvusClientV2 client = new MilvusClientV2(ConnectConfig.builder()
.uri("https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530")
.token("YOUR_CLUSTER_TOKEN")
.build());
Gson gson = new Gson();
List<JsonObject> data = Arrays.asList(
gson.fromJson("{\"id\": 0, \"vector\": [-0.619954382375778, 0.4479436794798608, -0.17493894838751745, -0.4248030059917294, -0.8648452746018911], \"title\": \"Artificial Intelligence in Real Life\", \"issue\": \"\vol.12\"}", JsonObject.class),
gson.fromJson("{\"id\": 1, \"vector\": [0.4762662251462588, -0.6942502138717026, -0.4490002642657902, -0.628696575798281, 0.9660395877041965], \"title\": \"Hollow Man\", \"issue\": \"vol.19\"}", JsonObject.class),
gson.fromJson("{\"id\": 2, \"vector\": [-0.8864122635045097, 0.9260170474445351, 0.801326976181461, 0.6383943392381306, 0.7563037341572827], \"title\": \"Treasure Hunt in Missouri\", \"issue\": \"vol.12\"}", JsonObject.class),
);
UpsertReq upsertReq = UpsertReq.builder()
.collectionName("my_collection")
.data(data)
.build();
UpsertResp upsertResp = client.upsert(upsertReq);
System.out.println(upsertResp);
// Output:
//
// UpsertResp(upsertCnt=3)
const { MilvusClient, DataType } = require("@zilliz/milvus2-sdk-node")
const address = "https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530";
const token = "YOUR_CLUSTER_TOKEN";
const client = new MilvusClient({address, token});
data = [
{id: 0, vector: [-0.619954382375778, 0.4479436794798608, -0.17493894838751745, -0.4248030059917294, -0.8648452746018911], title: "Artificial Intelligence in Real Life", issue: "vol.12"},
{id: 1, vector: [0.4762662251462588, -0.6942502138717026, -0.4490002642657902, -0.628696575798281, 0.9660395877041965], title: "Hollow Man", issue: "vol.19"},
{id: 2, vector: [-0.8864122635045097, 0.9260170474445351, 0.801326976181461, 0.6383943392381306, 0.7563037341572827], title: "Treasure Hunt in Missouri", issue: "vol.12"},
]
res = await client.upsert({
collection_name: "my_collection",
data: data,
})
console.log(res.upsert_cnt)
// Output
//
// 3
//
import (
"context"
"fmt"
"github.com/milvus-io/milvus/client/v2/column"
"github.com/milvus-io/milvus/client/v2/milvusclient"
)
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
milvusAddr := "https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530"
client, err := milvusclient.New(ctx, &milvusclient.ClientConfig{
Address: milvusAddr,
})
if err != nil {
fmt.Println(err.Error())
// handle error
}
defer client.Close(ctx)
titleColumn := column.NewColumnString("title", []string{
"Artificial Intelligence in Real Life", "Hollow Man", "Treasure Hunt in Missouri",
})
issueColumn := column.NewColumnString("issue", []string{
"vol.12", "vol.19", "vol.12"
})
_, err = client.Upsert(ctx, milvusclient.NewColumnBasedInsertOption("my_collection").
WithInt64Column("id", []int64{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}).
WithFloatVectorColumn("vector", 5, [][]float32{
{0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592},
{0.19886812562848388, 0.06023560599112088, 0.6976963061752597, 0.2614474506242501, 0.838729485096104},
{0.43742130801983836, -0.5597502546264526, 0.6457887650909682, 0.7894058910881185, 0.20785793220625592},
}).
WithColumns(titleColumn, issueColumn),
)
if err != nil {
fmt.Println(err.Error())
// handle err
}
export CLUSTER_ENDPOINT="https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530"
export TOKEN="YOUR_CLUSTER_TOKEN"
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/upsert" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
-d '{
"data": [
{"id": 0, "vector": [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592], "title": "Artificial Intelligence in Real Life", "issue": "vol.12"},
{"id": 1, "vector": [0.19886812562848388, 0.06023560599112088, 0.6976963061752597, 0.2614474506242501, 0.838729485096104], "title": "Hollow Man", "issue": "vol.19"},
{"id": 2, "vector": [0.43742130801983836, -0.5597502546264526, 0.6457887650909682, 0.7894058910881185, 0.20785793220625592], "title": "Treasure Hunt in Missouri", "issue": "vol.12"},
],
"collectionName": "my_collection"
}'
# {
# "code": 0,
# "data": {
# "upsertCount": 3,
# "upsertIds": [
# 0,
# 1,
# 2,
# ]
# }
# }
在 Partition 中 Upsert Entity
您还可以将 Entity Upsert 到指定 Partition 中。以下代码片段假定您的 Collection 中有一个名为 PartitionA 的 Partition。
如果 Partition 中存在这三个 Entity,它们将被请求中包含的 Entity 覆盖。
- Python
- Java
- NodeJS
- Go
- cURL
data=[
{
"id": 10,
"vector": [0.06998888224297328, 0.8582816610326578, -0.9657938677934292, 0.6527905683627726, -0.8668460657158576],
"title": "Layour Design Reference",
"issue": "vol.34"
},
{
"id": 11,
"vector": [0.6060703043917468, -0.3765080534566074, -0.7710758854987239, 0.36993888322346136, 0.5507513364206531],
"title": "Doraemon and His Friends",
"issue": "vol.2"
},
{
"id": 12,
"vector": [-0.9041813104515337, -0.9610546012461163, 0.20033003106083358, 0.11842506351635174, 0.8327356724591011],
"title": "Pikkachu and Pokemon",
"issue": "vol.12"
},
]
res = client.upsert(
collection_name="my_collection",
data=data,
partition_name="partitionA"
)
print(res)
# Output
# {'upsert_count': 3}
import io.milvus.v2.service.vector.request.UpsertReq;
import io.milvus.v2.service.vector.response.UpsertResp;
Gson gson = new Gson();
List<JsonObject> data = Arrays.asList(
gson.fromJson("{\"id\": 10, \"vector\": [0.06998888224297328, 0.8582816610326578, -0.9657938677934292, 0.6527905683627726, -0.8668460657158576], \"title\": \"Layour Design Reference\", \"issue\": \"vol.34\"}", JsonObject.class),
gson.fromJson("{\"id\": 11, \"vector\": [0.6060703043917468, -0.3765080534566074, -0.7710758854987239, 0.36993888322346136, 0.5507513364206531], \"title\": \"Doraemon and His Friends\", \"issue\": \"vol.2\"}", JsonObject.class),
gson.fromJson("{\"id\": 12, \"vector\": [-0.9041813104515337, -0.9610546012461163, 0.20033003106083358, 0.11842506351635174, 0.8327356724591011], \"title\": \"Pikkachu and Pokemon\", \"issue\": \"vol.12\"}", JsonObject.class),
);
UpsertReq upsertReq = UpsertReq.builder()
.collectionName("my_collection")
.partitionName("partitionA")
.data(data)
.build();
UpsertResp upsertResp = client.upsert(upsertReq);
System.out.println(upsertResp);
// Output:
//
// UpsertResp(upsertCnt=3)
const { MilvusClient, DataType } = require("@zilliz/milvus2-sdk-node")
// 6. Upsert data in partitions
data = [
{id: 10, vector: [0.06998888224297328, 0.8582816610326578, -0.9657938677934292, 0.6527905683627726, -0.8668460657158576], title: "Layour Design Reference", issue: "vol.34"},
{id: 11, vector: [0.6060703043917468, -0.3765080534566074, -0.7710758854987239, 0.36993888322346136, 0.5507513364206531], title: "Doraemon and His Friends", issue: "vol.2"},
{id: 12, vector: [-0.9041813104515337, -0.9610546012461163, 0.20033003106083358, 0.11842506351635174, 0.8327356724591011], title: "Pikkachu and Pokemon", issue: "vol.12"},
]
res = await client.upsert({
collection_name: "my_collection",
data: data,
partition_name: "partitionA"
})
console.log(res.upsert_cnt)
// Output
//
// 3
//
titleColumn = column.NewColumnString("title", []string{
"Layour Design Reference", "Doraemon and His Friends", "Pikkachu and Pokemon",
})
issueColumn = column.NewColumnString("issue", []string{
"vol.34", "vol.2", "vol.12",
})
_, err = client.Upsert(ctx, milvusclient.NewColumnBasedInsertOption("my_collection").
WithPartition("partitionA").
WithInt64Column("id", []int64{10, 11, 12, 13, 14, 15, 16, 17, 18, 19}).
WithFloatVectorColumn("vector", 5, [][]float32{
{0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592},
{0.19886812562848388, 0.06023560599112088, 0.6976963061752597, 0.2614474506242501, 0.838729485096104},
{0.43742130801983836, -0.5597502546264526, 0.6457887650909682, 0.7894058910881185, 0.20785793220625592},
}).
WithColumns(titleColumn, issueColumn),
)
if err != nil {
fmt.Println(err.Error())
// handle err
}
export CLUSTER_ENDPOINT="https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530"
export TOKEN="YOUR_CLUSTER_TOKEN"
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/upsert" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
-d '{
"data": [
{"id": 10, "vector": [0.06998888224297328, 0.8582816610326578, -0.9657938677934292, 0.6527905683627726, -0.8668460657158576], "title": "Layour Design Reference", "issue": "vol.34"},
{"id": 11, "vector": [0.6060703043917468, -0.3765080534566074, -0.7710758854987239, 0.36993888322346136, 0.5507513364206531], "title": "Doraemon and His Friends", "issue": "vol.2"},
{"id": 12, "vector": [-0.9041813104515337, -0.9610546012461163, 0.20033003106083358, 0.11842506351635174, 0.8327356724591011], "title": "Pikkachu and Pokemon", "issue": "vol.12"},
],
"collectionName": "my_collection",
"partitionName": "partitionA"
}'
# {
# "code": 0,
# "data": {
# "upsertCount": 3,
# "upsertIds": [
# 10,
# 11,
# 12,
# ]
# }
# }
在合并模式下 Upsert Entity
以下代码示例展示了如何通过部分更新来 Upsert Entity。只需提供需要更新的字段及其新值,同时设置显式的部分更新标志。
在以下示例中,upsert 请求中指定的 Entity 的 issue 字段将更新为请求中包含的值。
- Python
- Java
- Go
- NodeJS
- cURL
data=[
{
"id": 1,
"issue": "vol.14"
},
{
"id": 2,
"issue": "vol.7"
}
]
res = client.upsert(
collection_name="my_collection",
data=data,
partial_update=True
)
print(res)
# Output
# {'upsert_count': 2}
JsonObject row1 = new JsonObject();
row1.addProperty("id", 1);
row1.addProperty("issue", "vol.14");
JsonObject row2 = new JsonObject();
row2.addProperty("id", 2);
row2.addProperty("issue", "vol.7");
UpsertReq upsertReq = UpsertReq.builder()
.collectionName("my_collection")
.data(Arrays.asList(row1, row2))
.partialUpdate(true)
.build();
UpsertResp upsertResp = client.upsert(upsertReq);
System.out.println(upsertResp);
// Output:
//
// UpsertResp(upsertCnt=2)
pkColumn := column.NewColumnInt64("id", []int64{1, 2})
issueColumn = column.NewColumnString("issue", []string{
"vol.17", "vol.7",
})
_, err = client.Upsert(ctx, milvusclient.NewColumnBasedInsertOption("my_collection").
WithColumns(pkColumn, issueColumn).
WithPartialUpdate(true),
)
if err != nil {
fmt.Println(err.Error())
// handle err
}
const data=[
{
"id": 1,
"issue": "vol.14"
},
{
"id": 2,
"issue": "vol.7"
}
];
const res = await client.upsert({
collection_name: "my_collection",
data,
partial_update: true
});
console.log(res)
// Output
//
// 2
//
export CLUSTER_ENDPOINT="https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530"
export TOKEN="YOUR_CLUSTER_TOKEN"
export COLLECTION_NAME="my_collection"
export UPSERT_DATA='[
{
"id": 1,
"issue": "vol.14"
},
{
"id": 2,
"issue": "vol.7"
}
]'
curl -X POST "https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530/v2/vectordb/entities/upsert" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer ${TOKEN}" \
-H "Request-Timeout: 10" \
-d "{
\"collectionName\": \"${COLLECTION_NAME}\",
\"data\": ${UPSERT_DATA},
\"partialUpdate\": true
}"
# {
# "code": 0,
# "data": {
# "upsertCount": 2,
# "upsertIds": [
# 3,
# 12,
# ]
# }
# }
使用部分更新操作符对 ARRAY 字段执行 Upsert
在引入部分更新操作符(ARRAY_APPEND 和 ARRAY_REMOVE)之前,如果您需要更新 ARRAY 字段中的部分元素,通常需要在客户端执行读取-修改-写入流程:先查询现有数组,在应用代码中修改数组,然后通过 Upsert 写入完整的新数组。部分更新操作符允许您只发送需要追加或移除的元素,从而减少客户端逻辑,并避免在 Upsert 前额外查询一次现有数组。
假设主键为 1 的 Entity 已有 tags = ["new", "trial"]。在没有部分更新操作符时,添加数组元素 "premium" 需要 Upsert 完整的新数组:
- Python
- Java
- NodeJS
- Go
- cURL
client.upsert(
collection_name="users",
# highlight-start
data=[{"pk": 1, "tags": ["new", "trial", "premium"]}],
partial_update=True,
# highlight-end
)
List<JsonObject> replacementData = Collections.singletonList(
gson.fromJson("{\"pk\": 1, \"tags\": [\"new\", \"trial\", \"premium\"]}", JsonObject.class)
);
client.upsert(UpsertReq.builder()
.collectionName("users")
// highlight-start
.partialUpdate(true)
.data(replacementData)
// highlight-end
.build());
// nodejs
// go
# restful
如果使用部分更新操作符 ARRAY_APPEND,只需发送要追加的元素:
- Python
- Java
- NodeJS
- Go
- cURL
client.upsert(
collection_name="users",
# highlight-start
data=[{"pk": 1, "tags": ["premium"]}],
field_ops={"tags": FieldOp.array_append()},
# highlight-end
)
List<JsonObject> appendData = Collections.singletonList(
gson.fromJson("{\"pk\": 1, \"tags\": [\"premium\"]}", JsonObject.class)
);
UpsertReq.FieldPartialUpdateOp appendTags = UpsertReq.FieldPartialUpdateOp.builder()
.fieldName("tags")
.opType(UpsertReq.FieldPartialUpdateOp.OpType.ARRAY_APPEND)
.build();
client.upsert(UpsertReq.builder()
.collectionName("users")
// highlight-start
.partialUpdate(true)
.data(appendData)
.fieldOps(Collections.singletonList(appendTags))
// highlight-end
.build());
// nodejs
// go
# restful
通过 field_ops 为字段指定任一操作符时,会隐式启用部分更新语义。您无需同时传入 partial_update=True。
使用限制
-
请求载荷中的值必须与目标
ARRAY字段的element_type匹配。例如,如果目标字段为ARRAY<VARCHAR>,请求载荷必须包含字符串值。 -
在当前版本中,
ARRAY_APPEND和ARRAY_REMOVE支持element_type为BOOL、INT8、INT16、INT32、INT64、FLOAT、DOUBLE或VARCHAR的ARRAY字段。 -
执行
ARRAY_APPEND后,最终数组长度不得超过该字段的max_capacity。 -
对同一 Entity 的并发 Upsert 请求不会跨请求保持原子性。如果两个请求同时更新同一个
ARRAY字段,后写入的请求可能会覆盖先写入的结果。如果您需要保留所有并发变更,请在应用层进行协调。
示例
以下示例使用一个简单的 users Collection,其中包含主键字段 pk、类型为 ARRAY<VARCHAR> 的 tags 字段,以及 embedding 向量字段。示例先插入两个带有初始 tags 值的 Entity,然后使用 ARRAY_APPEND 和 ARRAY_REMOVE 展示每个操作符如何修改已存储的数组。
- Python
- Java
- NodeJS
- Go
- cURL
from pymilvus import DataType, FieldOp, MilvusClient
client = MilvusClient(
uri="https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530",
token="YOUR_CLUSTER_TOKEN"
)
# 1. Create a collection with an ARRAY<VARCHAR> field
schema = client.create_schema(enable_dynamic_field=False)
schema.add_field("pk", DataType.INT64, is_primary=True)
schema.add_field("embedding", DataType.FLOAT_VECTOR, dim=5)
schema.add_field(
"tags",
DataType.ARRAY,
element_type=DataType.VARCHAR,
max_capacity=8,
max_length=32,
)
index_params = client.prepare_index_params()
index_params.add_index(
field_name="embedding",
index_type="AUTOINDEX",
metric_type="L2",
)
client.create_collection(
collection_name="users",
schema=schema,
index_params=index_params
)
# 2. Seed two entities
client.insert(
collection_name="users",
data=[
{"pk": 1, "embedding": [0.1, 0.2, 0.3, 0.4, 0.5], "tags": ["new"]},
{"pk": 2, "embedding": [0.6, 0.7, 0.8, 0.9, 1.0], "tags": ["new", "trial"]},
],
)
# 3. Append tags without reading the existing ARRAY values
client.upsert(
collection_name="users",
# highlight-start
data=[
{"pk": 1, "tags": ["premium", "vip"]},
{"pk": 2, "tags": ["premium"]},
],
field_ops={"tags": FieldOp.array_append()},
# highlight-end
)
res = client.query(
collection_name="users",
filter="pk in [1, 2]",
output_fields=["pk", "tags"],
)
print(res)
# Example output:
# data: [
# "{'pk': 1, 'tags': ['new', 'premium', 'vip']}",
# "{'pk': 2, 'tags': ['new', 'trial', 'premium']}"
# ]
# 4. Remove matching tags without replacing the full ARRAY field
client.upsert(
collection_name="users",
# highlight-start
data=[
{"pk": 1, "tags": ["new"]},
{"pk": 2, "tags": ["trial"]},
],
field_ops={"tags": FieldOp.array_remove()},
# highlight-end
)
res = client.query(
collection_name="users",
filter="pk in [1, 2]",
output_fields=["pk", "tags"],
)
print(res)
# Example output:
# data: [
# "{'pk': 1, 'tags': ['premium', 'vip']}",
# "{'pk': 2, 'tags': ['new', 'premium']}"
# ]
import com.google.gson.Gson;
import com.google.gson.JsonObject;
import io.milvus.v2.client.ConnectConfig;
import io.milvus.v2.client.MilvusClientV2;
import io.milvus.v2.common.ConsistencyLevel;
import io.milvus.v2.common.DataType;
import io.milvus.v2.common.IndexParam;
import io.milvus.v2.service.collection.request.AddFieldReq;
import io.milvus.v2.service.collection.request.CreateCollectionReq;
import io.milvus.v2.service.vector.request.InsertReq;
import io.milvus.v2.service.vector.request.QueryReq;
import io.milvus.v2.service.vector.request.UpsertReq;
import io.milvus.v2.service.vector.response.QueryResp;
import java.util.Arrays;
import java.util.Collections;
import java.util.List;
MilvusClientV2 client = new MilvusClientV2(ConnectConfig.builder()
.uri("https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530")
.token("YOUR_CLUSTER_TOKEN")
.build());
Gson gson = new Gson();
// 1. Create a collection with an ARRAY<VARCHAR> field
CreateCollectionReq.CollectionSchema schema = CreateCollectionReq.CollectionSchema.builder()
.enableDynamicField(false)
.build();
schema.addField(AddFieldReq.builder()
.fieldName("pk")
.dataType(DataType.Int64)
.isPrimaryKey(true)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("embedding")
.dataType(DataType.FloatVector)
.dimension(5)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("tags")
.dataType(DataType.Array)
.elementType(DataType.VarChar)
.maxCapacity(8)
.maxLength(32)
.build());
List<IndexParam> indexParams = Collections.singletonList(IndexParam.builder()
.fieldName("embedding")
.indexType(IndexParam.IndexType.AUTOINDEX)
.metricType(IndexParam.MetricType.L2)
.build());
client.createCollection(CreateCollectionReq.builder()
.collectionName("users")
.collectionSchema(schema)
.indexParams(indexParams)
.consistencyLevel(ConsistencyLevel.STRONG)
.build());
// 2. Seed two entities
List<JsonObject> data = Arrays.asList(
gson.fromJson("{\"pk\": 1, \"embedding\": [0.1, 0.2, 0.3, 0.4, 0.5], \"tags\": [\"new\"]}", JsonObject.class),
gson.fromJson("{\"pk\": 2, \"embedding\": [0.6, 0.7, 0.8, 0.9, 1.0], \"tags\": [\"new\", \"trial\"]}", JsonObject.class)
);
client.insert(InsertReq.builder()
.collectionName("users")
.data(data)
.build());
// 3. Append tags without reading the existing ARRAY values
List<JsonObject> appendData = Arrays.asList(
gson.fromJson("{\"pk\": 1, \"tags\": [\"premium\", \"vip\"]}", JsonObject.class),
gson.fromJson("{\"pk\": 2, \"tags\": [\"premium\"]}", JsonObject.class)
);
UpsertReq.FieldPartialUpdateOp appendTags = UpsertReq.FieldPartialUpdateOp.builder()
.fieldName("tags")
.opType(UpsertReq.FieldPartialUpdateOp.OpType.ARRAY_APPEND)
.build();
client.upsert(UpsertReq.builder()
.collectionName("users")
// highlight-start
.partialUpdate(true)
.data(appendData)
.fieldOps(Collections.singletonList(appendTags))
// highlight-end
.build());
QueryResp res = client.query(QueryReq.builder()
.collectionName("users")
.filter("pk in [1, 2]")
.outputFields(Arrays.asList("pk", "tags"))
.consistencyLevel(ConsistencyLevel.STRONG)
.build());
System.out.println(res);
// Example output:
// [
// {"pk": 1, "tags": ["new", "premium", "vip"]},
// {"pk": 2, "tags": ["new", "trial", "premium"]}
// ]
// 4. Remove matching tags without replacing the full ARRAY field
List<JsonObject> removeData = Arrays.asList(
gson.fromJson("{\"pk\": 1, \"tags\": [\"new\"]}", JsonObject.class),
gson.fromJson("{\"pk\": 2, \"tags\": [\"trial\"]}", JsonObject.class)
);
UpsertReq.FieldPartialUpdateOp removeTags = UpsertReq.FieldPartialUpdateOp.builder()
.fieldName("tags")
.opType(UpsertReq.FieldPartialUpdateOp.OpType.ARRAY_REMOVE)
.build();
client.upsert(UpsertReq.builder()
.collectionName("users")
// highlight-start
.partialUpdate(true)
.data(removeData)
.fieldOps(Collections.singletonList(removeTags))
// highlight-end
.build());
res = client.query(QueryReq.builder()
.collectionName("users")
.filter("pk in [1, 2]")
.outputFields(Arrays.asList("pk", "tags"))
.consistencyLevel(ConsistencyLevel.STRONG)
.build());
System.out.println(res);
// Example output:
// [
// {"pk": 1, "tags": ["premium", "vip"]},
// {"pk": 2, "tags": ["new", "premium"]}
// ]
// nodejs
// go
# restful