外部迁移概述
外部迁移功能简化了将向量数据库和搜索系统迁移至 Zilliz Cloud 的过程。无论您是从 Qdrant 等向量数据库迁移,还是从 Elasticsearch、OpenSearch 等支持向量的搜索引擎迁移,Zilliz Cloud 均提供迁移工具,在确保数据完整性的同时最大限度降低迁移复杂度。
支持的数据源
Zilliz Cloud 支持从主流向量数据库和搜索平台迁移:
Data Source | Type | Key Features |
|---|---|---|
向量数据库 | 开源引擎,支持云部署与自托管 | |
搜索引擎 | 支持稠密向量与全文检索 | |
关系型数据库 | 支持向量扩展(pgvector) | |
托管服务 | 全托管向量数据库服务 | |
搜索平台 | 支持向量检索的 KNN 插件 |
核心能力
迁移工具提供丰富的配置选项,确保数据结构完美适配 Zilliz Cloud:
功能类别 | 能力项 | 描述 |
|---|---|---|
Schema 管理 | 字段重命名 | 迁移过程中重命名字段,匹配命名规范 |
动态转固定字段 | 将灵活元数据转为固定结构字段以提升性能。 如果元数据包含文本数据,将其转换为固定字段后会创建 VARCHAR 字段。这使该文本可启用 Full Text Search。详情参见 Full Text Search。 | |
添加额外字段 | 扩展源数据外的字段,适应业务演进需求 | |
数据类型映射 | 自动检测并映射字段类型,支持手动调整 | |
Collection 配置 | 智能命名处理 | 默认保留源表名;重名时系统报错;含连字符(-)的名称自动转为下划线(_)或提示修正 |
Shard 配置 | 根据查询模式设置数据分布策略 | |
Partition 策略 | 采用自动分区或自定义分组管理数据 | |
Data integrity | 主键处理 | 创建/保留/修改记录的唯一标识符 |
字段属性设置 | 定义字段空值规则与默认值 | |
验证检查 | 查看迁移详情 | |
Full Text Search | 迁移过程中为文本字段开启 Full Text Search。 | 在 高级设置 → Function 中配置,可在迁移期间为 VARCHAR 字段启用 Full Text Search。如果源数据的元数据包含文本,可使用转换为固定字段将文本型元数据转换为 VARCHAR 字段。详情参见 Full Text Search。 |
迁移流程
采用三阶段迁移框架保障数据完整性与过程可视化:
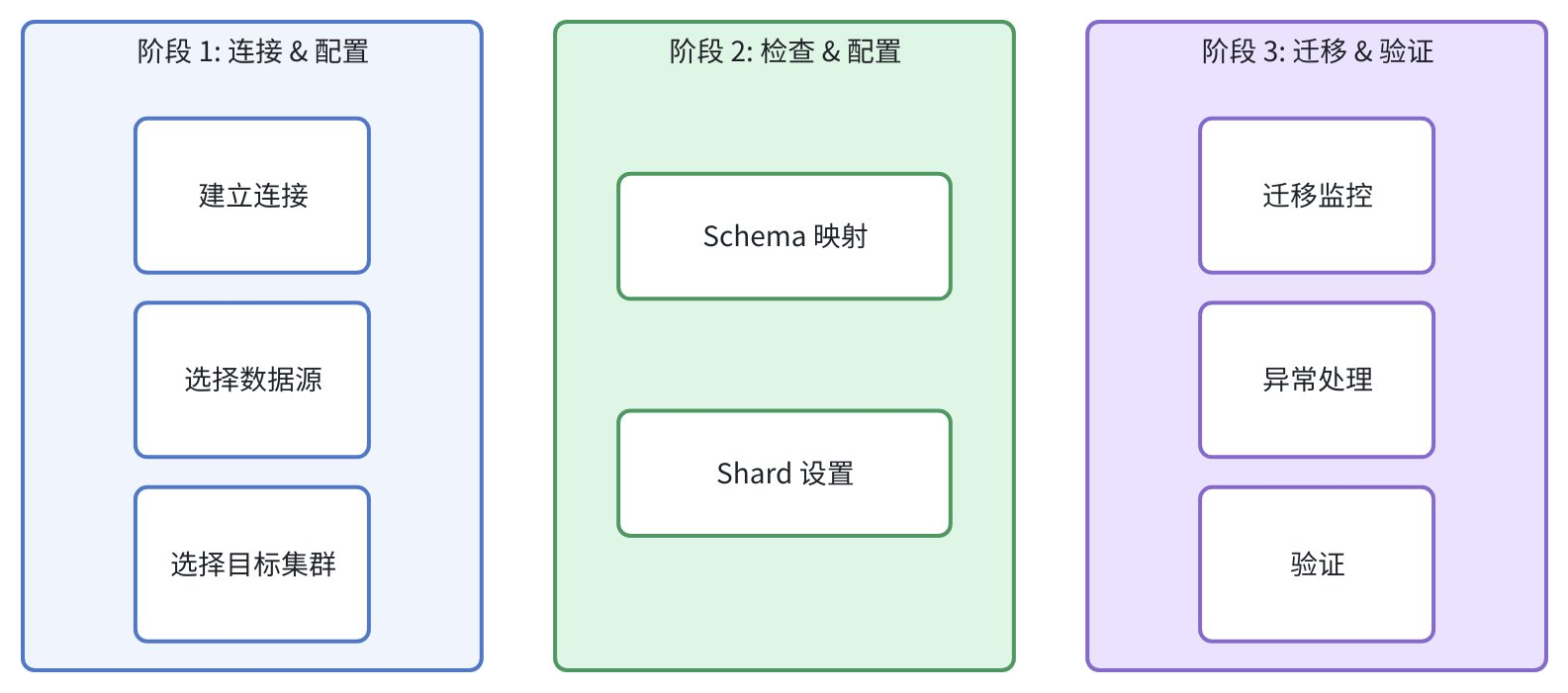
阶段 1:连接与配置
-
建立连接:提供源系统认证凭证(API密钥/连接字符串)
-
选择数据:指定需迁移的索引/ Collection /表
-
配置目标:选定 Zilliz Cloud 集群与目标 Database
阶段 2:映射检查
Schema 映射
-
自动检测:识别向量字段、标量字段及元数据
-
字段定制:按需调整字段名与类型
-
类型转换:审核源目标数据类型映射
-
高级设置:配置 Partition/Partition Key/Nullable 字段
Shard 设置
根据数据量优化性能配置:
-
小数据集(≤1亿行):单分片通常足够
-
大数据集(>10亿行):联系支持团队获取优化方案
阶段 3:迁移与验证
完成配置后执行迁移并监控:
-
实时监控:通过"任务"页跟踪迁移状态
-
进度指标:查看已迁移行数/错误数/预计完成时间
-
错误处理:发生问题时查阅详细日志
-
验证机制:自动行数校验确保数据完整
限制说明
迁移前需注意以下通用限制:
限制项 | 影响 | 解决方案 |
|---|---|---|
无自动索引/Load | Collection 迁移后不可立即查询 | 迁移后手动创建索引并 Load Collection(操作指南见创建 Vector Index 和 Load 和 Release)。 |
空数据源 | 无法选择空索引/表 | 确保源数据包含有效数据后再迁移 |
向量字段要求 | Collection 必须包含向量数据 | 迁移前验证源数据是否含向量字段 |
不支持的数据类型 | 特殊类型可能无法迁移 | 查阅各数据源专属指南了解数据类型映射 |
开始迁移
准备将数据迁移至 Zilliz Cloud 了吗?
访问数据迁移
设置 Full Text Search
如果源数据包含文本,你可以在迁移期间配置 Full Text Search,以提升文本检索效果。详情参见 Full Text Search。
平台专属迁移指南{#}
各平台详细操作流程、前置条件及数据映射说明: