Filtered Search
近似最近邻(ANN) Search 可以根据指定的非结构化数据(向量)找到与之相似的一批非结构化数据(向量),但是无法做到精确匹配。对于简单的精确匹配需求,可以使用过滤条件表达式基于部分标量字段进行文本过滤。本节将介绍如何在 ANN Search 中使用过滤条件表达式及相关注意事项。
概述
在 Zilliz Cloud 中,Filtered Search 分为两种类型,即标准 Filtered Search 和 迭代 Filtered Search。这两种类型的区别在于何时进行标量过滤。
标准 Filtered Search
如果 Collection 中既存放了非结构化数据的向量表示,也存放了这些非结构化数据的各类属性,您就可以使用这些属性字段构建过滤条件表达式,并将构建好的表达式包含在 ANN Search 请求中。Zilliz Cloud 在收到 Search 请求后,如果发现请求中携带了过滤条件表达式,就会按照过滤条件表达式中的条件找到所有与之匹配的 Entity,然后再根据请求中携带的查询向量在与过滤条件匹配的 Entity 中查找 topK 个与查询向量相似的 Entity。
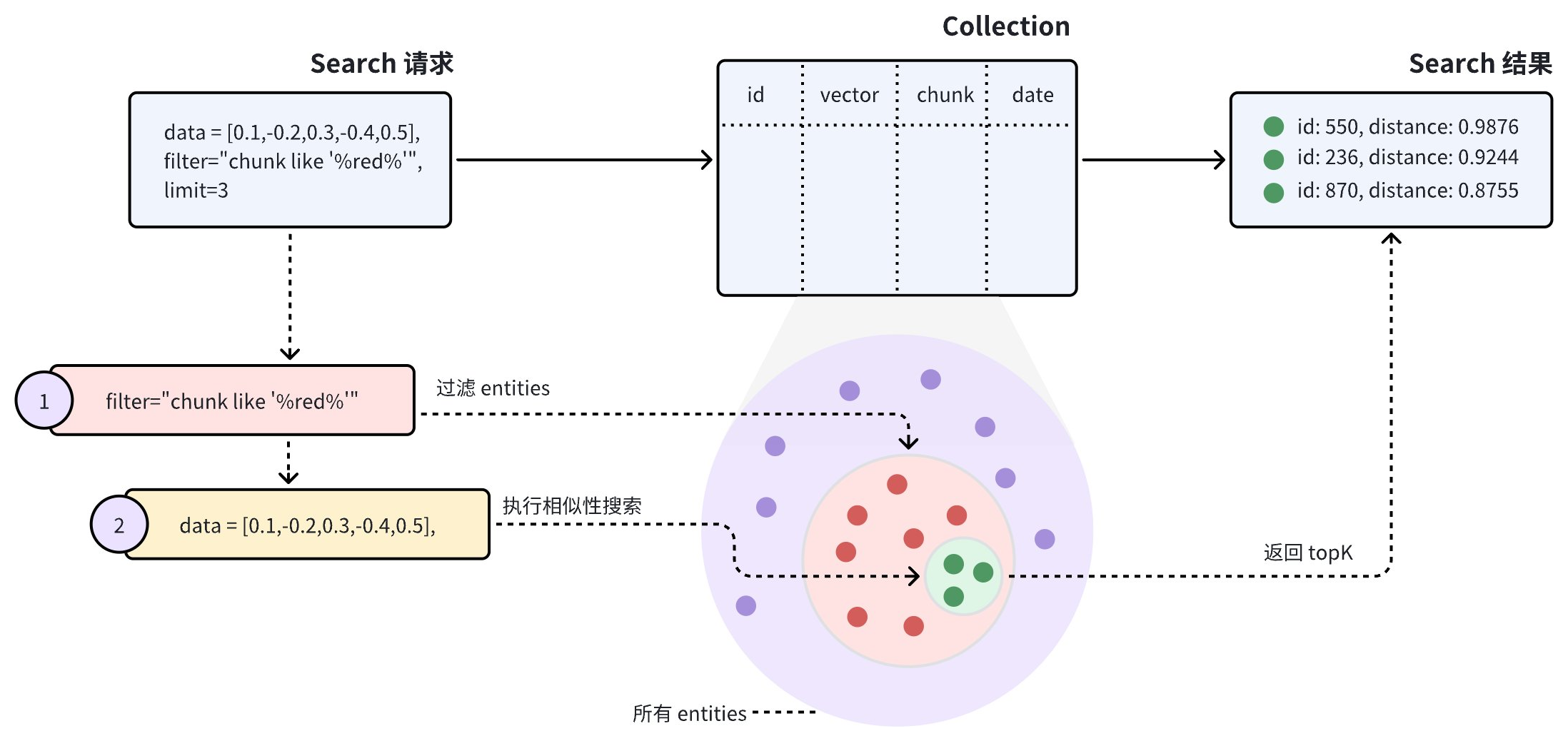
如上图所示,Search 请求中携带了一个过滤条件表达式 chunk like "%red%",表示需要在进行 ANN Search 前先找出 chunk 字段中包含 red 这个单词的所有 Entity。Zilliz Cloud 在收到这个 Search 请求时,会执行如下步骤:
-
过滤出符合过滤条件表达式的所有 Entity。
-
根据查询向量在匹配过滤条件表达式的所有 Entity 中进行 ANN Search。
-
返回 topK 个 Entity。
迭代 Filtered Search
标准 Filtered Search 的标量过滤过程有效地将搜索限定在一个较小的范围。然而,过于复杂的过滤表达式可能会导致非常高的搜索延迟。在这种情况下,迭代 Filtered Search 可以作为一种替代方案,有助于减少标量过滤的工作量。
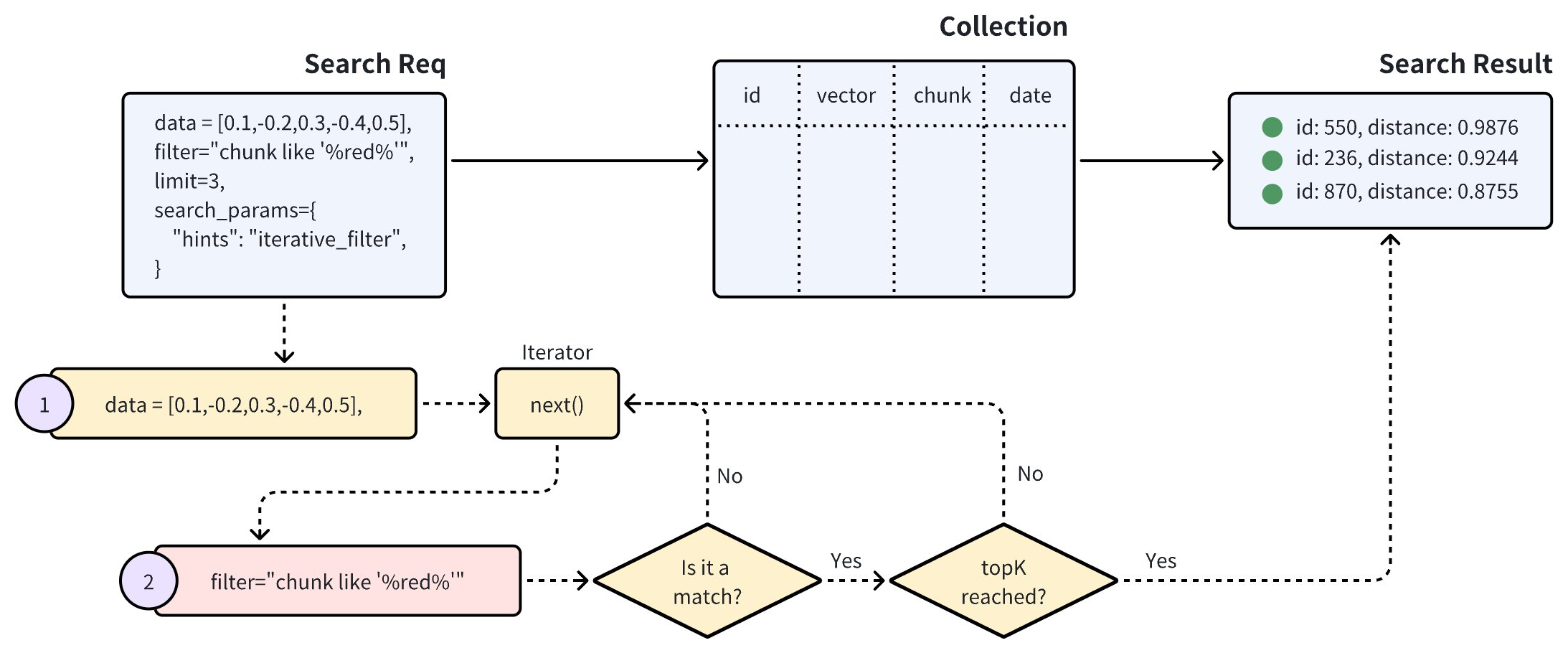
如上图所示,一个迭代 Filtered Search 请求会将搜索过程分成多次迭代进行。在每次迭代中,会先进行向量搜索,然后再进行标量过滤,并去除掉本次迭代中不满足标量过滤条件的结果。当 topK 满足后,返回最终结果。
这种方式显著地减少了标量过滤需要处理的 Entity 数量,使得其尤其适用于处理过滤条件较为复杂的场景。
需要注意的是,迭代器每次只处理一个 Entity,并以串行的方式进行迭代。使用迭代 Filtered Search 可能会拉长请求处理时间或在需要处理的 Entity 较大时出现潜在的性能问题。
操作示例
本节将结合具体的示例介绍如何进行 Filtered Search。在如下示例中,假设 Collection 已经存放了如下 10 条Entity。每个 Entity 都有 id, vector, color 和 likes 这几个字段。
[
{"id": 0, "vector": [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592], "color": "pink_8682", "likes": 165},
{"id": 1, "vector": [0.19886812562848388, 0.06023560599112088, 0.6976963061752597, 0.2614474506242501, 0.838729485096104], "color": "red_7025", "likes": 25},
{"id": 2, "vector": [0.43742130801983836, -0.5597502546264526, 0.6457887650909682, 0.7894058910881185, 0.20785793220625592], "color": "orange_6781", "likes": 764},
{"id": 3, "vector": [0.3172005263489739, 0.9719044792798428, -0.36981146090600725, -0.4860894583077995, 0.95791889146345], "color": "pink_9298", "likes": 234},
{"id": 4, "vector": [0.4452349528804562, -0.8757026943054742, 0.8220779437047674, 0.46406290649483184, 0.30337481143159106], "color": "red_4794", "likes": 122},
{"id": 5, "vector": [0.985825131989184, -0.8144651566660419, 0.6299267002202009, 0.1206906911183383, -0.1446277761879955], "color": "yellow_4222", "likes": 12},
{"id": 6, "vector": [0.8371977790571115, -0.015764369584852833, -0.31062937026679327, -0.562666951622192, -0.8984947637863987], "color": "red_9392", "likes": 58},
{"id": 7, "vector": [-0.33445148015177995, -0.2567135004164067, 0.8987539745369246, 0.9402995886420709, 0.5378064918413052], "color": "grey_8510", "likes": 775},
{"id": 8, "vector": [0.39524717779832685, 0.4000257286739164, -0.5890507376891594, -0.8650502298996872, -0.6140360785406336], "color": "white_9381", "likes": 876},
{"id": 9, "vector": [0.5718280481994695, 0.24070317428066512, -0.3737913482606834, -0.06726932177492717, -0.6980531615588608], "color": "purple_4976", "likes": 765}
]
如果查询向量已经在目标 Collection 中存在,可以考虑使用 ids 参数,从而让 Milvus 在搜索前从 Collection 中自动获取查询向量。更多内容,可以阅读 Primary Key Search。
使用标准 Filtered Search
当使用如下示例代码在上述 Entity 中进行搜索时,我们需要在 Search 请求中添加过滤条件。为了方便检查搜索结果是否满足过滤条件,我们还在 Search 请求中指定了 Output Fields。
- Python
- Java
- Go
- NodeJS
- cURL
from pymilvus import MilvusClient
client = MilvusClient(
uri="https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530",
token="YOUR_CLUSTER_TOKEN"
)
query_vector = [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592]
res = client.search(
collection_name="my_collection",
data=[query_vector],
limit=5,
# highlight-start
filter='color like "red%" and likes > 50',
output_fields=["color", "likes"]
# highlight-end
)
for hits in res:
print("TopK results:")
for hit in hits:
print(hit)
import io.milvus.v2.client.ConnectConfig;
import io.milvus.v2.client.MilvusClientV2;
import io.milvus.v2.service.vector.request.SearchReq
import io.milvus.v2.service.vector.request.data.FloatVec;
import io.milvus.v2.service.vector.response.SearchResp
MilvusClientV2 client = new MilvusClientV2(ConnectConfig.builder()
.uri("https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530")
.token("YOUR_CLUSTER_TOKEN")
.build());
FloatVec queryVector = new FloatVec(new float[]{0.3580376395471989f, -0.6023495712049978f, 0.18414012509913835f, -0.26286205330961354f, 0.9029438446296592f});
SearchReq searchReq = SearchReq.builder()
.collectionName("my_collection")
.data(Collections.singletonList(queryVector))
.topK(5)
.filter("color like \"red%\" and likes > 50")
.outputFields(Arrays.asList("color", "likes"))
.build();
SearchResp searchResp = client.search(searchReq);
List<List<SearchResp.SearchResult>> searchResults = searchResp.getSearchResults();
for (List<SearchResp.SearchResult> results : searchResults) {
System.out.println("TopK results:");
for (SearchResp.SearchResult result : results) {
System.out.println(result);
}
}
// Output
// TopK results:
// SearchResp.SearchResult(entity={color=red_4794, likes=122}, score=0.5975797, id=4)
// SearchResp.SearchResult(entity={color=red_9392, likes=58}, score=-0.24996188, id=6)
import (
"context"
"fmt"
"github.com/milvus-io/milvus/client/v2/entity"
"github.com/milvus-io/milvus/client/v2/milvusclient"
)
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
milvusAddr := "https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530"
token := "YOUR_CLUSTER_TOKEN"
client, err := client.New(ctx, &client.ClientConfig{
Address: milvusAddr,
APIKey: token,
})
if err != nil {
fmt.Println(err.Error())
// handle error
}
defer client.Close(ctx)
queryVector := []float32{0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592}
resultSets, err := client.Search(ctx, milvusclient.NewSearchOption(
"my_collection", // collectionName
5, // limit
[]entity.Vector{entity.FloatVector(queryVector)},
).WithConsistencyLevel(entity.ClStrong).
WithANNSField("vector").
WithFilter("color like 'red%' and likes > 50").
WithOutputFields("color", "likes"))
if err != nil {
fmt.Println(err.Error())
// handle error
}
for _, resultSet := range resultSets {
fmt.Println("IDs: ", resultSet.IDs.FieldData().GetScalars())
fmt.Println("Scores: ", resultSet.Scores)
fmt.Println("color: ", resultSet.GetColumn("color").FieldData().GetScalars())
fmt.Println("likes: ", resultSet.GetColumn("likes").FieldData().GetScalars())
}
import { MilvusClient, DataType } from "@zilliz/milvus2-sdk-node";
const address = "https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530";
const token = "YOUR_CLUSTER_TOKEN";
const client = new MilvusClient({address, token});
const query_vector = [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592]
const res = await client.search({
collection_name: "my_collection",
data: [query_vector],
limit: 5,
// highlight-start
filters: 'color like "red%" and likes > 50',
output_fields: ["color", "likes"]
// highlight-end
})
export CLUSTER_ENDPOINT="https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530"
export TOKEN="YOUR_CLUSTER_TOKEN"
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/search" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
-d '{
"collectionName": "my_collection",
"data": [
[0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592]
],
"annsField": "vector",
"filter": "color like \"red%\" and likes > 50",
"limit": 5,
"outputFields": ["color", "likes"]
}'
# {"code":0,"cost":0,"data":[]}
在上述代码示例中使用的过滤条件表达式 color like "red%" and likes > 50 中包含了使用 and 操作符连接的两个过滤条件:一个是 color 字段的值以 red 开头,另一个是 likes 字段的值大于 50。在示例数据中,符合此条件的数据只有两条,因此在满足 topK 小于等于 3 的情况下,这两条数据会全部返回。
[
{
"id": 4,
"distance": 0.3345786594834839,
"entity": {
"vector": [0.4452349528804562, -0.8757026943054742, 0.8220779437047674, 0.46406290649483184, 0.30337481143159106],
"color": "red_4794",
"likes": 122
}
},
{
"id": 6,
"distance": 0.6638239834383389,
"entity": {
"vector": [0.8371977790571115, -0.015764369584852833, -0.31062937026679327, -0.562666951622192, -0.8984947637863987],
"color": "red_9392",
"likes": 58
}
},
]
关于在过滤条件表达式中可以使用的操作符,可以参考过滤表达式概览。
使用迭代 Filtered Search
要使用迭代 Filtered Search 进行过滤搜索,您可以执行以下操作:
- Python
- Java
- Go
- NodeJS
- cURL
from pymilvus import MilvusClient
client = MilvusClient(
uri="https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530",
token="YOUR_CLUSTER_TOKEN"
)
query_vector = [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592]
res = client.search(
collection_name="my_collection",
data=[query_vector],
limit=5,
# highlight-start
filter='color like "red%" and likes > 50',
output_fields=["color", "likes"],
search_params={
"hints": "iterative_filter"
}
# highlight-end
)
for hits in res:
print("TopK results:")
for hit in hits:
print(hit)
import io.milvus.v2.client.ConnectConfig;
import io.milvus.v2.client.MilvusClientV2;
import io.milvus.v2.service.vector.request.SearchReq;
import io.milvus.v2.service.vector.request.data.FloatVec;
import io.milvus.v2.service.vector.response.SearchResp;
MilvusClientV2 client = new MilvusClientV2(ConnectConfig.builder()
.uri("https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530")
.token("YOUR_CLUSTER_TOKEN")
.build());
FloatVec queryVector = new FloatVec(new float[]{0.3580376395471989f, -0.6023495712049978f, 0.18414012509913835f, -0.26286205330961354f, 0.9029438446296592f});
SearchReq searchReq = SearchReq.builder()
.collectionName("my_collection")
.data(Collections.singletonList(queryVector))
.topK(5)
.filter("color like \"red%\" and likes > 50")
.outputFields(Arrays.asList("color", "likes"))
.searchParams(new HashMap<>("hints", "iterative_filter"))
.build();
SearchResp searchResp = client.search(searchReq);
List<List<SearchResp.SearchResult>> searchResults = searchResp.getSearchResults();
for (List<SearchResp.SearchResult> results : searchResults) {
System.out.println("TopK results:");
for (SearchResp.SearchResult result : results) {
System.out.println(result);
}
}
// Output
// TopK results:
// SearchResp.SearchResult(entity={color=red_4794, likes=122}, score=0.5975797, id=4)
// SearchResp.SearchResult(entity={color=red_9392, likes=58}, score=-0.24996188, id=6)
import (
"context"
"fmt"
"github.com/milvus-io/milvus/client/v2/entity"
"github.com/milvus-io/milvus/client/v2/milvusclient"
)
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
milvusAddr := "https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530"
token := "YOUR_CLUSTER_TOKEN"
client, err := client.New(ctx, &client.ClientConfig{
Address: milvusAddr,
APIKey: token,
})
if err != nil {
fmt.Println(err.Error())
// handle error
}
defer client.Close(ctx)
queryVector := []float32{0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592}
resultSets, err := client.Search(ctx, milvusclient.NewSearchOption(
"my_collection", // collectionName
5, // limit
[]entity.Vector{entity.FloatVector(queryVector)},
).WithConsistencyLevel(entity.ClStrong).
WithANNSField("vector").
WithFilter("color like 'red%' and likes > 50").
WithOutputFields("color", "likes").
WithSearchParam("hints", "iterative_filter"))
if err != nil {
fmt.Println(err.Error())
// handle error
}
for _, resultSet := range resultSets {
fmt.Println("IDs: ", resultSet.IDs.FieldData().GetScalars())
fmt.Println("Scores: ", resultSet.Scores)
fmt.Println("color: ", resultSet.GetColumn("color").FieldData().GetScalars())
fmt.Println("likes: ", resultSet.GetColumn("likes").FieldData().GetScalars())
}
import { MilvusClient, DataType } from "@zilliz/milvus2-sdk-node";
const address = "https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530";
const token = "YOUR_CLUSTER_TOKEN";
const client = new MilvusClient({address, token});
const query_vector = [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592]
const res = await client.search({
collection_name: "filtered_search_collection",
data: [query_vector],
limit: 5,
// highlight-start
filters: 'color like "red%" and likes > 50',
hints: "iterative_filter",
output_fields: ["color", "likes"]
// highlight-end
})
export CLUSTER_ENDPOINT="https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530"
export TOKEN="YOUR_CLUSTER_TOKEN"
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/search" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
-d '{
"collectionName": "my_collection",
"data": [
[0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592]
],
"annsField": "vector",
"filter": "color like \"red%\" and likes > 50",
"searchParams": {"hints": "iterative_filter"},
"limit": 5,
"outputFields": ["color", "likes"]
}'
# {"code":0,"cost":0,"data":[]}