JSON Shredding公测版
JSON Shredding 通过将传统的行式存储转换为优化后的列式存储来加速 JSON 查询。在保持 JSON 数据建模灵活性的同时,Zilliz Cloud 在后台执行列式优化,大幅提升数据访问与查询效率。
JSON Shredding 对大多数 JSON 查询场景都有效,性能优势在以下场景中更加明显:
-
大型、复杂的 JSON 文档 —— 文档越大,性能提升越明显
-
读操作密集型工作负载 —— 频繁在 JSON 键上进行过滤、排序或搜索
-
混合查询模式 —— 针对不同 JSON 键的查询均能从混合存储方式中受益
工作原理
JSON Shredding 过程分为三个阶段,对数据进行优化以实现快速检索。
阶段 1:数据写入与键分类
当新 JSON 文档写入时,Zilliz Cloud 会持续采样和分析数据,为每个 JSON 键建立统计信息,包括出现频率与类型稳定性(数据类型是否在文档间保持一致)。
基于这些统计信息,JSON 键会被分类为以下几类:
JSON 键分类
键类型 | 描述 |
|---|---|
Typed key(定型键) | 在大多数文档中存在,且始终具有相同数据类型(如全是整数或全是字符串)。 |
Dynamic key(动态键) | 频繁出现但类型混杂(如有时是字符串,有时是整数)。 |
Shared key(共享键) | 很少出现或嵌套较深,低于可配置的频率阈值。 |
示例分类
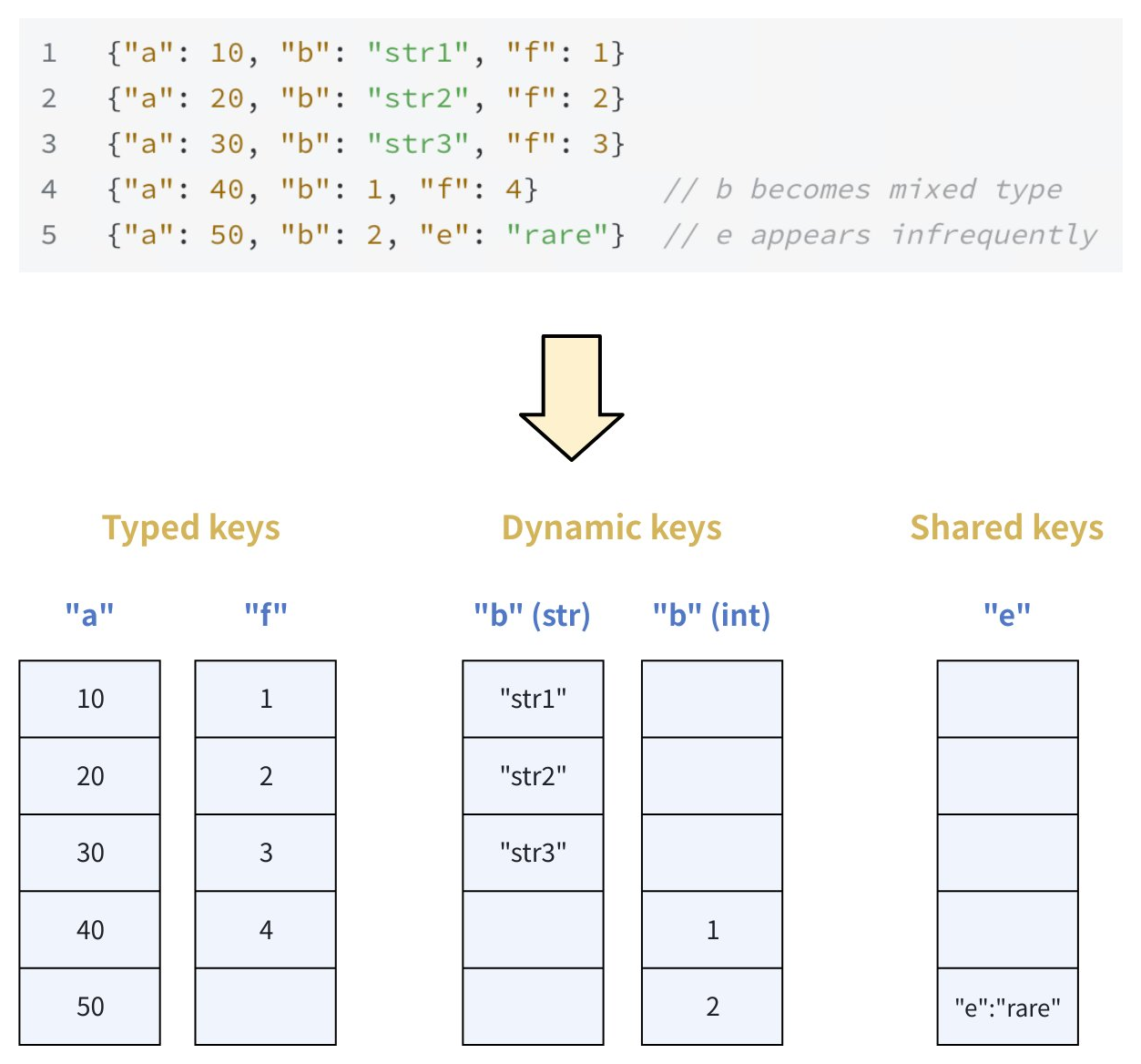
假设有如下示例 JSON:
{"a": 10, "b": "str1", "f": 1}
{"a": 20, "b": "str2", "f": 2}
{"a": 30, "b": "str3", "f": 3}
{"a": 40, "b": 1, "f": 4} // b becomes mixed type
{"a": 50, "b": 2, "e": "rare"} // e appears infrequently
分类结果:
-
Typed key:a, f(始终为整数)
-
Dynamic key:b(字符串/整数混合)
-
Shared key:e(低频键)
阶段 2:存储优化
阶段 1 的分类结果决定了存储布局。Zilliz Cloud 使用优化后的列式存储格式:
-
Shredded column:定型键和动态键的数据写入专属列。查询时 Zilliz Cloud 只需读取目标键的数据,而无需处理整个文档,从而实现快速扫描。
-
Shared column:所有共享键存储在一个紧凑的二进制 JSON 列中,并在其上构建共享键倒排索引,用于加速低频键的查询。
阶段 3:查询执行
在查询阶段,Zilliz Cloud 会利用优化后的存储布局,为每个查询谓词选择最快的执行路径:
-
Fast path:对定型/动态键的查询(如
json['a'] < 100)直接访问专属列 -
Optimized path:对共享键的查询(如
json['e'] = 'rare')使用倒排索引快速定位相关文档
性能基准
测试显示,JSON Shredding 在不同键类型和查询模式下均带来显著性能提升。
测试环境与方法
-
硬件:1 core / 8GB 集群
-
数据集:100 万 JSONBench 文档
-
平均文档大小:478.89 bytes
-
测试时长:100 秒,测量 QPS 和延迟
结果:定型键
查询表达式 | 类型 | QPS(未启用) | QPS(启用后) | 性能提升 |
|---|---|---|---|---|
| 整数 | 8.69 | 287.50 | 33x |
| 字符串 | 8.42 | 126.1 | 14.9x |
结果:共享键
查询表达式 | 类型 | QPS(未启用) | QPS(启用后) | 性能提升 |
|---|---|---|---|---|
| 嵌套整数 | 4.33 | 385 | 88.9x |
| 嵌套字符串 | 7.6 | 352 | 46.3x |
关键结论
-
共享键查询 提升最明显(最高可达 89x)
-
定型键查询 提供稳定的 15–30x 提升
-
所有查询类型 均有性能收益,且无性能回退
FAQ
-
如何在 JSON Shredding 与 JSON Indexing 间选择?
-
JSON Shredding:适合键频繁出现的复杂 JSON 结构,结合列式存储和倒排索引,适合读操作密集、查询多键的场景。不推荐用于很小的 JSON 文档。
-
JSON Indexing:适合针对性优化特定键的查询,存储开销更低,适合结构简单的 JSON。注意:Shredding 不涵盖数组内键的查询,需要通过 JSON 索引加速。
有关更多信息,请参考 JSON 概述。
-