合并数据即将作废
您可以将现有Zilliz Cloud Collection 中的数据与本地文件或外部对象存储中的数据合并,来创建一个结合了两个数据源数据的 Collection。这被称为数据合并操作,您可以将其作为一种变通方法,向现有集合中添加带有数据的字段。
- 本特性目前属于内测特性。如果您对该特性感兴趣,想尝试使用。请联系 Zilliz Cloud 技术支持。
概述
数据合并操作与关系型数据库中的 LEFT JOIN 操作类似,将指定 Collection 中的数据和指定数据源中匹配的数据合并,然后将合并后的数据存放到一个新的 Collection 中。
数据源应该是一个或多个存放于 Zilliz Cloud Volume 或对象存储桶中的 PARQUET 文件。
如下图所示,源 Collection 中有三个字段。其中,id 为主键。PARQUET 文件中有 id 和 date 两个字段:id 字段作为合并键,其中存放的值将与源 Collection 中的同名键中的值进行匹配;date 字段则是需要添加到目标 Collection 中的字段。
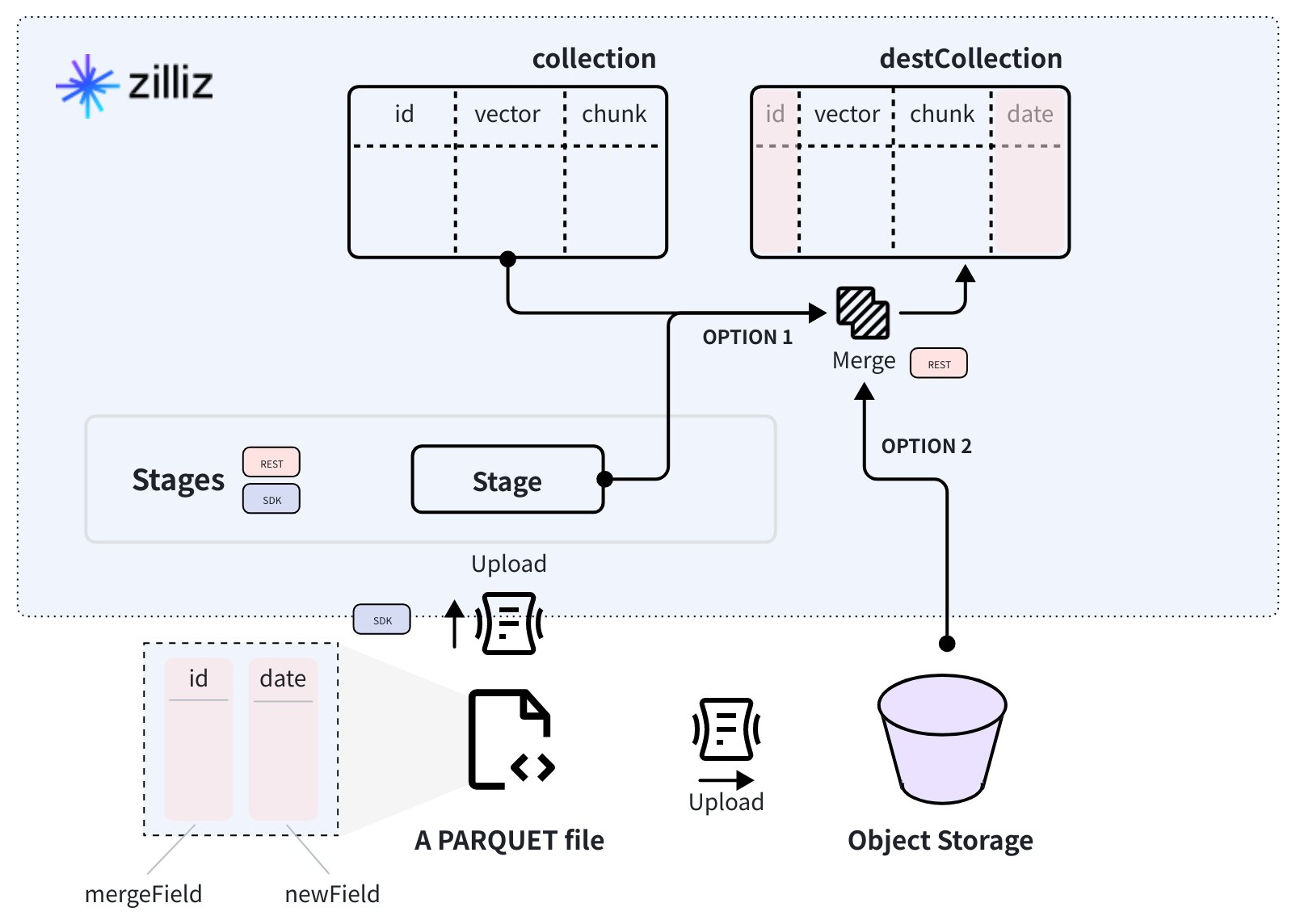
当您将该 PARQUET 文件上传到 Zilliz Cloud Volume 或对象存储桶之后,您就可以使用合并数据 API 接口来创建目标 Collection 用于存放合并后的数据。
数据源是可选参数。您也可以将合并数据 API 用于向指定 Collection 中添加字段的场景。
本文将演示如何使用合并数据 API 在指定 Collection 中添加字段并填充数据以及仅在指定 Collection 添加字段。
添加字段并填充数据
如果需要在添加字段的同时填充数据,您需要指定源 Collection,数据源以及在目标 Collection 中需要添加的字段。数据源应为若干存放于 Zilliz Cloud Volume 或 AWS S3 bucket 的 PARQUET 文件。
使用 Volume
如需执行数据合并操作,您需要先创建一个 Volume,并将您的数据文件上传到 Volume 中。当准备就绪,您就可以通过执行数据合并操作来创建一个包括两种数据来源的新的 Collection。
如何代码片段演示了如何通过 Volume 执行数据合并。关于如何创建 Volume 及向 Volume 中上传数据,请参考管理 Volume (SDK)。
export BASE_URL="https://api.cloud.zilliz.com.cn"
export TOKEN="YOUR_API_KEY"
curl --request POST \
--url "${BASE_URL}/v2/etl/merge" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
-d '{
"clusterId": "in00-xxxxxxxxxxxxxxx",
"dbName": "my_database",
"collectionName": "my_collection",
"destDbName": "my_database",
"destCollectionName": "my_merged_collection",
"dataSource": {
"type": "volume",
"volumeName": "my_volume",
"dataPath": "path/to/your/parquet.parquet"
},
"mergeField": "id",
"newFields": [
{
"fieldName": "date",
"dataType": "VARCHAR",
"params": {
"maxLength": 10
}
}
]
}'
在执行上述命令前,您需要先了解如下字段的含义:
-
dbName和collectionName这两个参数指定了数据合并操作的源 Collection。
-
destDbName和destCollectionName这两个参数指定了数据合并操作后被创建的目标 Collection。需要注意的是,目标 Collection 须与源 Collection 位于相同集群。
-
dataSource此参数为可选设置,包含了数据源的相关设置,包括数据源类型和指向包含列式数据的 Parquet 文件的路径。该数据源将会与上述指定的源 Collection 中的数据合并后插入到目标 Collection 中。
在使用 Volume 中存放的文件作为数据源时,您需要将
type设置为volume后再设置volumeName和dataPath两个子参数。📘说明-
dataPath参数的值可以是指定 Volume 中某个 Parquet 文件的绝对路径,或者某个包含了多个 Parquet 文件的文件夹的绝对路径。当指定的路径为文件夹时,请确保该文件夹中所有的 Parquet 文件都有相同的数据结构。例如:
path/to/your/file.parquet(文件)或path/to/your/folder/(文件夹)。 -
如果你只是想要在目标 Collection 中添加字段,但不希望填充数据,可以忽略此参数。
-
-
mergeField数据合并操作和关系型数据库中的 LEFT JOIN 操作相似。此参数在数据合并操作中将做为连接源 Collection 和包含列式数据的 Parquet 文件的共享字段使用。
-
newFields此参数包含了 Parquet 文件中需要添加到目标 Collection 中的字段列表。支持的字段类型包括 VARCHAR、INT8、INT16、INT32、INT64、FLOAT、DOUBLE 和 BOOL。
上述命令创建了一个数据合并任务,并返回任务 ID。
{
"code": 0,
"data": {
"jobId": "job-xxxxxxxxxxxxxxxxxxxxx"
}
}
使用对象存储
如需执行数据合并操作,您需要先创建一个对象存储桶并将数据文件上传到该桶中。当准备就绪,您就可以通过执行数据合并操作来创建一个包括两种数据来源的新的 Collection。
如下代码片断演示了如何使用一个对象存储桶来执行数据合并操作。您可以参考您的对象存储服务提供商的文档来学习如何创建对象存储桶及向桶中上传数据。
export BASE_URL="https://api.cloud.zilliz.com.cn"
export TOKEN="YOUR_API_KEY"
curl --request POST \
--url "${BASE_URL}/v2/etl/merge" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
-d '{
"clusterId": "in00-xxxxxxxxxxxxxxx",
"dbName": "my_database",
"collectionName": "my_collection",
"destDbName": "my_database",
"destCollectionName": "my_merged_collection",
"dataSource": {
"type": "oss",
"dataPath": "oss://my-bucket/my_data.parquet",
"credential": {
"accessKey": "xxxxxxxxxxxxxxxxxxx",
"secretKey": "xxxxxxxxxxxx"
}
},
"mergeField": "id",
"newFields": [
{
"fieldName": "date",
"dataType": "VARCHAR",
"params": {
"maxLength": 10
}
}
]
}'
在执行上述命令前,您需要先了解如下字段的含义:
-
dbName和collectionName这两个参数指定了数据合并操作的源 Collection。
-
destDbName和destCollectionName这两个参数指定了数据合并操作后被创建的目标 Collection。需要注意的是,目标 Collection 须与源 Collection 位于相同集群。
-
dataSource此参数为可选设置,包含了数据源的相关设置,包括数据源类型和指向包含列式数据的 Parquet 文件的路径。该数据源将会与上述指定的源 Collection 中的数据合并后插入到目标 Collection 中。
在使用 Volume 中存放的文件作为数据源时,您需要将
type设置为oss后再设置dataPath和credential两个子参数。📘说明-
dataPath参数的值可以是指定对象存储桶中某个 Parquet 文件的绝对路径,或者某个包含了多个 Parquet 文件的文件夹的绝对路径。当指定的路径为文件夹时,请确保该文件夹中所有的 Parquet 文件都有相同的数据结构。例如:
oss:///my-bucket/my_data.parquet(文件)或oss:///my-bucket/(文件夹)。 -
如果你只是想要在目标 Collection 中添加字段,但不希望填充数据,可以忽略此参数。
-
-
mergeField数据合并操作和关系型数据库中的 LEFT JOIN 操作相似。此参数在数据合并操作中将做为连接源 Collection 和包含列式数据的 Parquet 文件的共享字段使用。
-
newFields此参数包含了 Parquet 文件中需要添加到目标 Collection 中的字段列表。支持的字段类型包括 VARCHAR、INT8、INT16、INT32、INT64、FLOAT、DOUBLE 和 BOOL。
上述命令创建了一个数据合并任务,并返回任务 ID。
{
"code": 0,
"data": {
"jobId": "job-xxxxxxxxxxxxxxxxxxxxx"
}
}
仅添加字段
您也可以将合并数据 API 用于向指定 Collection 中添加字段的场景。在此场景下,您无需指定数据源。
export BASE_URL="https://api.cloud.zilliz.com.cn"
export TOKEN="YOUR_API_KEY"
curl --request POST \
--url "${BASE_URL}/v2/etl/merge" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
-d '{
"clusterId": "in00-xxxxxxxxxxxxxxx",
"dbName": "my_database",
"collectionName": "my_collection",
"destDbName": "my_database",
"destCollectionName": "my_merged_collection",
"mergeField": "id",
"newFields": [
{
"fieldName": "date",
"dataType": "VARCHAR",
"params": {
"maxLength": 10
}
}
]
}'
上述命令创建了一个数据合并任务,并返回任务 ID。
{
"code": 0,
"data": {
"jobId": "job-xxxxxxxxxxxxxxxxxxxxx"
}
}
验证结果
当您获取了数据合并任务的 ID 后,您可以使用查看任务详情 API 接口或按照管理项目任务中的步骤查看任务的状态。在数据合并任务结束后,您可以检查目标 Collection 的 Schema 及其中存放的 Entity 数量来确认操作结果是否符合预期。
故障排除
-
当 Parquet 文件中的存在 Merge Key 与源 Collection 不匹配的记录时,如何处理?
与传统关系型数据库系统的左合并(Left Join)操作类似,数据合并操作会根据指定的 Merge Key 从源 Collection 及指定的 Parquet 文件中获取相应的数据,并使用这些数据创建一个包含合并数据的 Collection。
只有 Parquet 文件中 Merge Key 与源 Collection 中的 Merge Key 匹配的行才会被合并。如果行的 Merge Key 与源 Collection 中的任何 Entity 都不匹配,则会跳过这些行。如果 Parquet 文件中的所有行都不匹配源 Collection 中的任何 Entity,那么 Zilliz Cloud 会创建
newFields中指定的字段,并使用 null 填充。