Model Ranker 概述公测版
传统向量搜索仅依据数学相似度对结果进行排序,即向量在高维空间中的匹配程度。虽然这种方法效率高,但往往会忽略真正的语义相关性。以搜索**"数据库优化的最佳实践"**为例:你可能会收到向量相似度很高、频繁提及这些术语的文档,但实际上并没有提供可操作的优化策略。
Model Ranker 通过集成能够理解查询与文档之间语义关系的先进语言模型,优化 Zilliz Cloud 搜索体验。使其不仅仅依赖向量相似度,还会评估内容含义和上下文,以提供更智能、更相关的结果。
限制
-
Model Ranker 不能用于 Grouping Search。
-
用于模型重排序的字段必须为文本类型(
VARCHAR)。 -
每个 Model Ranker 一次只能使用一个
VARCHAR字段进行评估。
工作原理
Model Ranker 通过明确定义的工作流程将语言模型的理解能力集成到 Zilliz Cloud 搜索过程中:
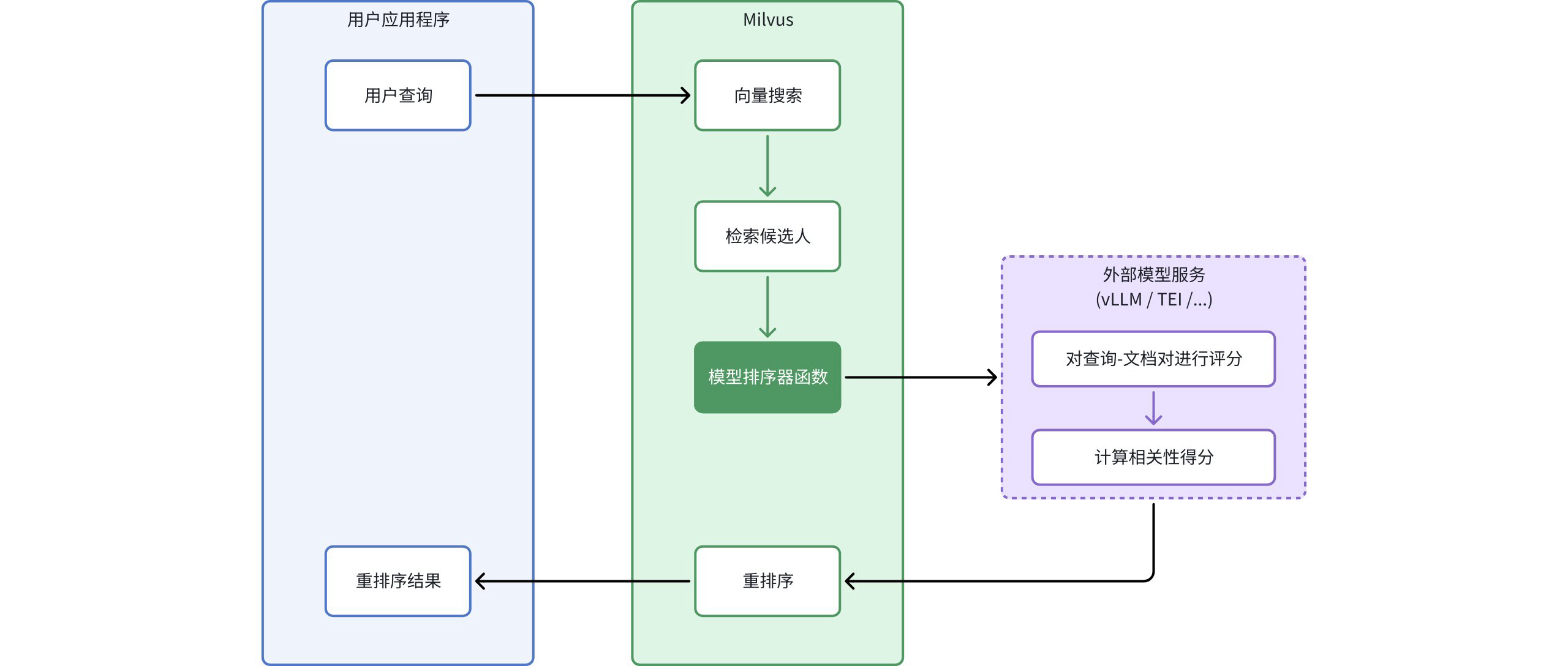
-
初始查询:您的应用程序向 Zilliz Cloud 发送查询
-
向量搜索:Zilliz Cloud 执行标准向量搜索以识别候选文档
-
候选文档检索:系统基于向量相似度识别初始候选文档集
-
模型评估:Model Ranker 函数处理查询-文档对:
-
将原始查询和候选文档发送到外部模型服务
-
语言模型评估查询与每个文档之间的语义相关性
-
每个文档都会根据语义理解获得一个相关性得分
-
-
智能重排序:根据模型生成的相关性得分对文档进行重新排序
-
增强结果:您的应用程序接收到的结果是按语义相关性而非仅按向量相似度排序的
根据您的需求选择一个模型提供商
Zilliz Cloud 支持以下用于重排序的模型服务提供商,每个提供商都有不同的特点:
vLLM | 最适合 | 特性 | 示例用例 |
|---|---|---|---|
TEI | 需要深入语义理解和定制的复杂应用程序 |
| 法律研究平台,部署特定领域模型,以理解法律术语和判例法关系 |
Cohere | 快速实施且资源使用高效 |
| 内容管理系统需要具备高效的重排序能力,并满足标准要求 |
Voyage AI | 优先考虑可靠性和集成便利性的企业应用程序 |
| 需要具备高可用性搜索、一致的 API 性能和多语言产品目录的电子商务平台 |
SiliconFlow | 具有特定性能和上下文要求的RAG应用程序 |
| 研究数据库,文档长度各异,需要微调性能控制和专业语义理解 |
硅基流动 | 以成本效益为优先处理长文档的应用程序 |
| 技术文档搜索系统处理冗长的手册和论文,需要智能分段和重叠控制 |
有关每个模型服务实施的详细信息,请参考专门的章节:
实施
在实施 Model Ranker 之前,请确保您已具备:
-
一个 Zilliz Cloud Collection,其中包含一个
VARCHAR字段,该字段包含待重排序的文本 -
一个可被您的 Zilliz Cloud 集群 访问的正在运行的外部模型服务
-
Zilliz Cloud 与您选择的模型服务之间的适当网络连接
Model Ranker 可与标准向量搜索和混合搜索操作无缝集成。实现过程包括创建一个定义重排序配置的函数对象,并将其传递给搜索操作。
创建 Model Ranker
要实现 Model Ranker,首先要使用适当的配置定义一个 Function(函数)对象。在这个例子中,我们使用 TEI 作为服务提供商:
- Python
- Java
- NodeJS
- Go
- cURL
from pymilvus import MilvusClient, Function, FunctionType
# Connect to your Milvus server
client = MilvusClient(
uri="YOUR_CLUSTER_ENDPOINT" # Replace with your Milvus server URI
)
# Create a model ranker function
model_ranker = Function(
name="semantic_ranker", # Function identifier
input_field_names=["document"], # VARCHAR field to use for reranking
function_type=FunctionType.RERANK, # Must be set to RERANK
params={
"reranker": "model", # Specify model reranker. Must be "model"
"provider": "tei", # Choose provider: "tei", "vllm", etc.
"queries": ["machine learning for time series"], # Query text
"endpoint": "http://model-service:8080", # Model service endpoint
# "maxBatch": 32 # Optional: batch size for processing
}
)
// java
// nodejs
// go
# restful
参数 | 必选? | 描述 | 值 / 示例 |
|---|---|---|---|
| 是 | 执行搜索时使用的函数标识符。 |
|
| 是 | 用于重新排序的文本字段名称。 必须是 |
|
| 是 | 指定当前创建的函数类型。 所有 Model Ranker 都必须设置为 |
|
| 是 | 一个包含基于模型的重排序函数配置的字典。可用的参数(键)因服务提供商而异。 |
|
| 是 | 必须设置为 |
|
| 是 | 用于重排序的模型服务提供商。 |
|
| 是 | 重排序模型用于计算相关性得分的查询字符串列表。 查询字符串的数量必须与搜索操作中的查询数量完全匹配(即使使用查询向量而非文本),否则将报错。 |
|
| 是 | 模型服务的 URL。 | |
| 否 | 单个批次中要处理的最大文档数。较大的值可提高吞吐量,但需要更多内存。 |
|
在标准向量搜索中使用
定义 Model Ranker 后,您可以在搜索请求中将其传递给 ranker 参数来应用它:
- Python
- Java
- NodeJS
- Go
- cURL
# Use the model ranker in standard vector search
results = client.search(
collection_name,
data=["machine learning for time series"], # Number of queries must match that specified in model_ranker.params["queries"]
anns_field="vector_field",
limit=10,
output_fields=["document"], # Include the text field in outputs
# highlight-next-line
ranker=model_ranker, # Apply the model ranker here
consistency_level="Bounded"
)
// java
// nodejs
// go
# restful
在混合搜索中使用
Model Ranker 也可应用于结合多个向量字段的混合搜索操作:
- Python
- Java
- NodeJS
- Go
- cURL
from pymilvus import AnnSearchRequest
# Define search requests for different vector fields
dense_request = AnnSearchRequest(
data=["machine learning for time series"],
anns_field="dense_vector",
param={},
limit=20
)
sparse_request = AnnSearchRequest(
data=["machine learning for time series"],
anns_field="sparse_vector",
param={},
limit=20
)
# Apply model ranker to hybrid search
hybrid_results = client.hybrid_search(
collection_name,
[dense_request, sparse_request],
# highlight-next-line
ranker=model_ranker, # Same model ranker works with hybrid search
limit=10,
output_fields=["document"]
)
// java
// nodejs
// go
# restful