多语言 Analyzer公测版
当 Zilliz Cloud 执行文本分析时,通常会在一个 Collection 的整个文本字段上应用单一 Analyzer。如果该 Analyzer 针对英语进行了优化,它在处理其他语言(如中文、西班牙语或法语)所需的分词和词干规则时就会遇到困难,从而导致召回率降低。例如,搜索西班牙语单词 “teléfono”(意为“电话”)时,英文 Analyzer 可能会忽略重音符号,也不会应用西班牙语特有的词干提取,导致相关结果被遗漏。
多语言 Analyzer 通过允许你在单个 Collection 的文本字段上配置多个 Analyzer 来解决这一问题。这样,你就可以在文本字段中存储多语言文档,Zilliz Cloud 会根据每篇文档的语言规则进行分析。
使用限制
-
本功能仅适用于基于 BM25 的文本检索和稀疏向量。详情参见 Full Text Search。
-
单个 Collection 中的每个文档只能使用一个 Analyzer,该 Analyzer 由其语言标识字段的值决定。
-
性能可能因 Analyzer 的复杂性和文本数据的大小而异。
概述
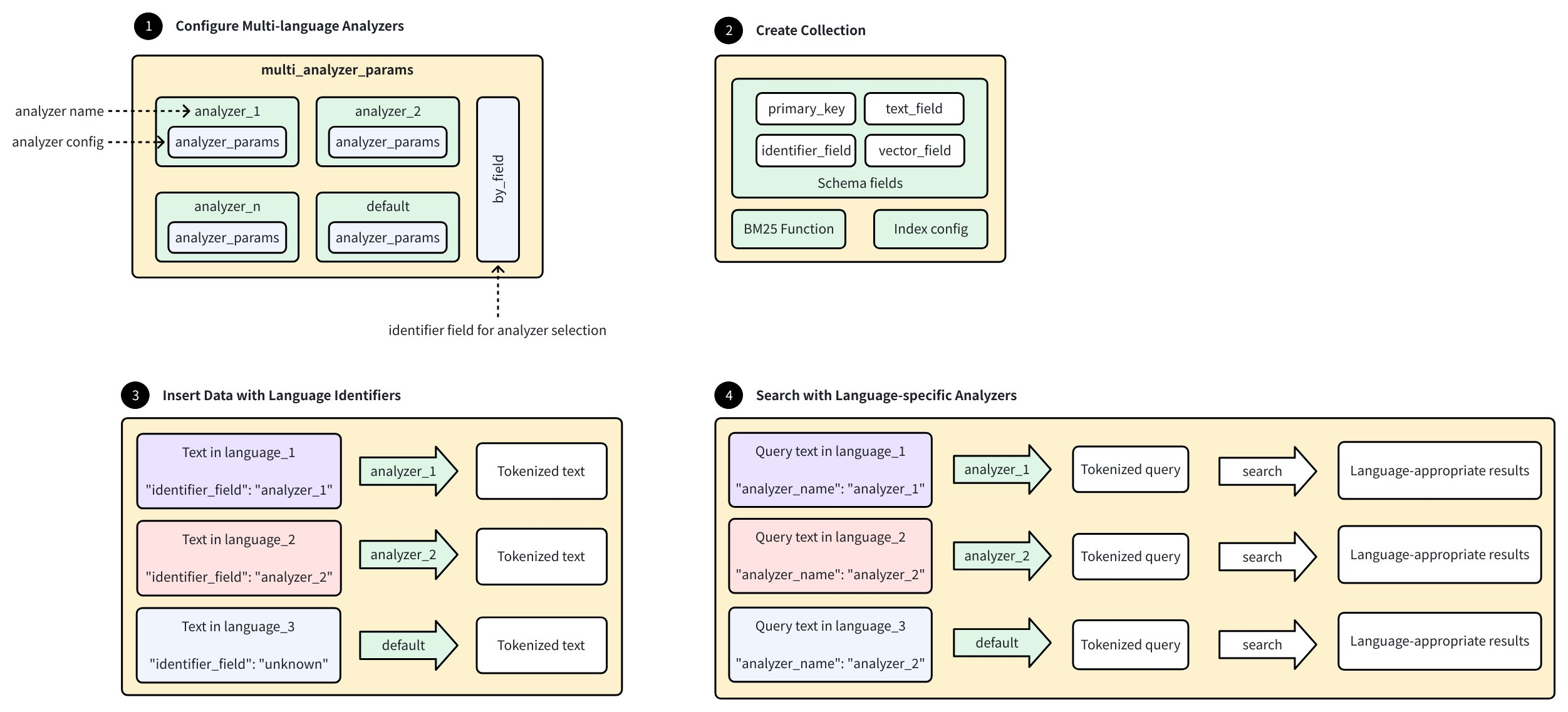
下图展示了在 Zilliz Cloud 中配置和使用多语言 Analyzer 的工作流程:
-
配置多语言 Analyzer
-
使用
<analyzer_name>: <analyzer_config>格式设置多种特定语言的 Analyzer,每个配置遵循 Analyzer 概述 中的标准analyzer_params。 -
定义一个特殊的标识字段,用于决定每个文档所选用的 Analyzer。
-
配置一个默认 Analyzer,用于处理未知语言。
-
-
创建 Collection
-
定义 Schema,包括以下字段:
-
primary_key:唯一文档标识符。
-
text_field:存储原始文本内容。
-
identifier_field:指示每个文档应使用的 Analyzer。
-
vector_field:存储由 BM25 函数生成的稀疏向量。
-
-
配置 BM25 函数和索引参数。
-
-
插入带有语言标识的数据
-
添加包含不同语言文本的文档,每个文档需包含标识符值以指定所用 Analyzer。
-
Zilliz Cloud 会根据标识字段选择合适的 Analyzer,对于未知标识则使用默认 Analyzer。
-
-
使用特定语言 Analyzer 进行搜索
-
在查询时指定 Analyzer 名称,系统会用该 Analyzer 处理查询文本。
-
文本分词会遵循语言特定规则,搜索结果也会基于相似度返回语言匹配的结果。
-
步骤 1:配置 multi_analyzer_params
multi_analyzer_params 是一个 JSON 对象,用于决定 Zilliz Cloud 如何为每条数据选择合适的 Analyzer。
- Python
- Java
- NodeJS
- Go
- cURL
multi_analyzer_params = {
# Define language-specific analyzers
# Each analyzer follows this format: <analyzer_name>: <analyzer_params>
"analyzers": {
"english": {"type": "english"}, # English-optimized analyzer
"chinese": {"type": "chinese"}, # Chinese-optimized analyzer
"default": {"tokenizer": "icu"} # Required fallback analyzer
},
"by_field": "language", # Field determining analyzer selection
"alias": {
"cn": "chinese", # Use "cn" as shorthand for Chinese
"en": "english" # Use "en" as shorthand for English
}
}
Map<String, Object> analyzerParams = new HashMap<>();
analyzerParams.put("analyzers", new HashMap<String, Object>() {{
put("english", new HashMap<String, Object>() {{
put("type", "english");
}});
put("chinese", new HashMap<String, Object>() {{
put("type", "chinese");
}});
put("default", new HashMap<String, Object>() {{
put("tokenizer", "icu");
}});
}});
analyzerParams.put("by_field", "language");
analyzerParams.put("alias", new HashMap<String, Object>() {{
put("cn", "chinese");
put("en", "english");
}});
const multi_analyzer_params = {
// Define language-specific analyzers
// Each analyzer follows this format: <analyzer_name>: <analyzer_params>
"analyzers": {
"english": {"type": "english"}, # English-optimized analyzer
"chinese": {"type": "chinese"}, # Chinese-optimized analyzer
"default": {"tokenizer": "icu"} # Required fallback analyzer
},
"by_field": "language", # Field determining analyzer selection
"alias": {
"cn": "chinese", # Use "cn" as shorthand for Chinese
"en": "english" # Use "en" as shorthand for English
}
}
multiAnalyzerParams := map[string]any{
"analyzers": map[string]any{
"english": map[string]string{"type": "english"},
"chinese": map[string]string{"type": "chinese"},
"default": map[string]string{"tokenizer": "icu"},
},
"by_field": "language",
"alias": map[string]string{
"cn": "chinese",
"en": "english",
},
}
# restful
export multi_analyzer_params='{
"analyzers": {
"english": {
"type": "english"
},
"chinese": {
"type": "chinese"
},
"default": {
"tokenizer": "icu"
}
},
"by_field": "language",
"alias": {
"cn": "chinese",
"en": "english"
}
}'
参数 | 必需? | 描述 | 规则 |
|---|---|---|---|
| 是 | 列出 Zilliz Cloud 可用于处理文本的所有语言特定 Analyzer。 每个 Analyzer 的定义格式为: |
|
| 是 | 存储每个文档语言信息(即 Analyzer 名称)的字段名,Zilliz Cloud 会据此选择对应的 Analyzer。 |
|
| 否 | 为 Analyzer 创建快捷方式或替代名称,使其在代码中更容易引用。每个 Analyzer 可以有一个或多个别名。 | 每个别名必须映射到一个已存在的 Analyzer 键。 |
步骤 2:创建 Collection
创建一个支持多语言的 Collection 需要配置特定的字段和索引:
步骤 1:添加字段
在此步骤中,定义集合模式时需要包含以下四个关键字段:
-
主键字段 (id):集合中每个实体的唯一标识符。设置
auto_id=True时,Zilliz Cloud 会自动生成这些 ID。 -
语言标识字段 (language):此
VARCHAR字段对应multi_analyzer_params中指定的by_field。它存储每个实体的语言标识,用于指示 Zilliz Cloud 应使用哪个 Analyzer。 -
文本内容字段 (text):此
VARCHAR字段存储你要分析和搜索的实际文本数据。必须将enable_analyzer=True,以启用该字段的文本分析功能。multi_analyzer_params配置会直接附加到此字段,从而建立文本数据与特定语言 Analyzer 之间的关联。 -
向量字段 (sparse):此字段用于存储 BM25 函数生成的稀疏向量。这些向量表示文本数据的可分析形式,也是 Zilliz Cloud 实际用于搜索的内容。
- Python
- Java
- NodeJS
- Go
- cURL
# Import required modules
from pymilvus import MilvusClient, DataType, Function, FunctionType
# Initialize client
client = MilvusClient(
uri="https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530",
)
# Initialize a new schema
schema = client.create_schema()
# Step 2.1: Add a primary key field for unique document identification
schema.add_field(
field_name="id", # Field name
datatype=DataType.INT64, # Integer data type
is_primary=True, # Designate as primary key
auto_id=True # Auto-generate IDs (recommended)
)
# Step 2.2: Add language identifier field
# This MUST match the "by_field" value in language_analyzer_config
schema.add_field(
field_name="language", # Field name
datatype=DataType.VARCHAR, # String data type
max_length=255 # Maximum length (adjust as needed)
)
# Step 2.3: Add text content field with multi-language analysis capability
schema.add_field(
field_name="text", # Field name
datatype=DataType.VARCHAR, # String data type
max_length=8192, # Maximum length (adjust based on expected text size)
enable_analyzer=True, # Enable text analysis
multi_analyzer_params=multi_analyzer_params # Connect with our language analyzers
)
# Step 2.4: Add sparse vector field to store the BM25 output
schema.add_field(
field_name="sparse", # Field name
datatype=DataType.SPARSE_FLOAT_VECTOR # Sparse vector data type
)
import com.google.gson.JsonObject;
import io.milvus.common.clientenum.FunctionType;
import io.milvus.v2.client.ConnectConfig;
import io.milvus.v2.client.MilvusClientV2;
import io.milvus.v2.common.DataType;
import io.milvus.v2.common.IndexParam;
import io.milvus.v2.service.collection.request.AddFieldReq;
import io.milvus.v2.service.collection.request.CreateCollectionReq;
import io.milvus.v2.service.collection.request.DropCollectionReq;
import io.milvus.v2.service.utility.request.FlushReq;
import io.milvus.v2.service.vector.request.InsertReq;
import io.milvus.v2.service.vector.request.SearchReq;
import io.milvus.v2.service.vector.request.data.EmbeddedText;
import io.milvus.v2.service.vector.response.SearchResp;
MilvusClientV2 client = new MilvusClientV2(ConnectConfig.builder()
.uri("https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530")
.build());
CreateCollectionReq.CollectionSchema collectionSchema = CreateCollectionReq.CollectionSchema.builder()
.build();
collectionSchema.addField(AddFieldReq.builder()
.fieldName("id")
.dataType(DataType.Int64)
.isPrimaryKey(true)
.autoID(true)
.build());
collectionSchema.addField(AddFieldReq.builder()
.fieldName("language")
.dataType(DataType.VarChar)
.maxLength(255)
.build());
collectionSchema.addField(AddFieldReq.builder()
.fieldName("text")
.dataType(DataType.VarChar)
.maxLength(8192)
.enableAnalyzer(true)
.multiAnalyzerParams(analyzerParams)
.build());
collectionSchema.addField(AddFieldReq.builder()
.fieldName("sparse")
.dataType(DataType.SparseFloatVector)
.build());
import { MilvusClient, DataType, FunctionType } from "@zilliz/milvus2-sdk-node";
// Initialize client
const client = new MilvusClient({
address: "https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530",
});
// Initialize schema array
const schema = [
{
name: "id",
data_type: DataType.Int64,
is_primary_key: true,
auto_id: true,
},
{
name: "language",
data_type: DataType.VarChar,
max_length: 255,
},
{
name: "text",
data_type: DataType.VarChar,
max_length: 8192,
enable_analyzer: true,
analyzer_params: multi_analyzer_params,
},
{
name: "sparse",
data_type: DataType.SparseFloatVector,
},
];
import (
"context"
"fmt"
"github.com/milvus-io/milvus/client/v2/column"
"github.com/milvus-io/milvus/client/v2/entity"
"github.com/milvus-io/milvus/client/v2/index"
"github.com/milvus-io/milvus/client/v2/milvusclient"
)
client, err := milvusclient.New(ctx, &milvusclient.ClientConfig{
Address: "https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530",
APIKey: "YOUR_CLUSTER_TOKEN",
})
if err != nil {
fmt.Println(err.Error())
// handle error
}
schema := entity.NewSchema()
schema.WithField(entity.NewField().
WithName("id").
WithDataType(entity.FieldTypeInt64).
WithIsPrimaryKey(true).
WithIsAutoID(true),
).WithField(entity.NewField().
WithName("language").
WithDataType(entity.FieldTypeVarChar).
WithMaxLength(255),
).WithField(entity.NewField().
WithName("text").
WithDataType(entity.FieldTypeVarChar).
WithMaxLength(8192).
WithEnableAnalyzer(true).
WithMultiAnalyzerParams(multiAnalyzerParams),
).WithField(entity.NewField().
WithName("sparse").
WithDataType(entity.FieldTypeSparseVector),
)
# restful
export TOKEN="YOUR_CLUSTER_TOKEN"
export CLUSTER_ENDPOINT="https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530"
export idField='{
"fieldName": "id",
"dataType": "Int64",
"isPrimary": true,
"autoID": true
}'
export languageField='{
"fieldName": "language",
"dataType": "VarChar",
"elementTypeParams": {
"max_length": 255
}
}'
export textField='{
"fieldName": "text",
"dataType": "VarChar",
"elementTypeParams": {
"max_length": 8192,
"enable_analyzer": true,
"multiAnalyzerParam": '"$multi_analyzer_params"'
},
}'
export sparseField='{
"fieldName": "sparse",
"dataType": "SparseFloatVector"
}'
步骤 2:定义 BM25 function
定义 BM25 function 为文本生成稀疏向量:
- Python
- Java
- NodeJS
- Go
- cURL
# Create the BM25 function
bm25_function = Function(
name="text_to_vector", # Descriptive function name
function_type=FunctionType.BM25, # Use BM25 algorithm
input_field_names=["text"], # Process text from this field
output_field_names=["sparse"] # Store vectors in this field
)
# Add the function to our schema
schema.add_function(bm25_function)
CreateCollectionReq.Function function = CreateCollectionReq.Function.builder()
.functionType(FunctionType.BM25)
.name("text_to_vector")
.inputFieldNames(Collections.singletonList("text"))
.outputFieldNames(Collections.singletonList("sparse"))
.build();
collectionSchema.addFunction(function);
const functions = [
{
name: "text_bm25_emb",
description: "bm25 function",
type: FunctionType.BM25,
input_field_names: ["text"],
output_field_names: ["sparse"],
params: {},
},
];
function := entity.NewFunction()
schema.WithFunction(function.WithName("text_to_vector").
WithType(entity.FunctionTypeBM25).
WithInputFields("text").
WithOutputFields("sparse"))
# restful
export function='{
"name": "text_to_vector",
"type": "BM25",
"inputFieldNames": ["text"],
"outputFieldNames": ["sparse"]
}'
export schema="{
\"autoID\": true,
\"fields\": [
$idField,
$languageField,
$textField,
$sparseField
],
\"functions\": [
$function
]
}"
有关更多信息,请参考 Full Text Search。
步骤 3:配置索引参数
为稀疏向量配置索引参数:
- Python
- Java
- NodeJS
- Go
- cURL
# Configure index parameters
index_params = client.prepare_index_params()
# Add index for sparse vector field
index_params.add_index(
field_name="sparse", # Field to index (our vector field)
index_type="AUTOINDEX", # Let Milvus choose optimal index type
metric_type="BM25" # Must be BM25 for this feature
)
List<IndexParam> indexes = new ArrayList<>();
indexes.add(IndexParam.builder()
.fieldName("sparse")
.indexType(IndexParam.IndexType.AUTOINDEX)
.metricType(IndexParam.MetricType.BM25)
.build());
const index_params = [{
field_name: "sparse",
index_type: "AUTOINDEX",
metric_type: "BM25"
}];
idx := index.NewAutoIndex(index.MetricType(entity.BM25))
indexOption := milvusclient.NewCreateIndexOption("multilingual_documents", "sparse", idx)
# restful
export IndexParams='[
{
"fieldName": "sparse",
"indexType": "AUTOINDEX",
"metricType": "BM25",
"params": {}
}
]'
步骤 4:创建 Collection
此最终创建步骤会将之前的所有配置汇总起来:
-
collection_name="multilang_demo":为 Collection 命名,方便后续引用。 -
schema=schema:应用你定义的字段结构和 function。 -
index_params=index_params:实现高效搜索所需的索引策略。
- Python
- Java
- NodeJS
- Go
- cURL
# Create collection
COLLECTION_NAME = "multilingual_documents"
# Check if collection already exists
if client.has_collection(COLLECTION_NAME):
client.drop_collection(COLLECTION_NAME) # Remove it for this example
print(f"Dropped existing collection: {COLLECTION_NAME}")
# Create the collection
client.create_collection(
collection_name=COLLECTION_NAME, # Collection name
schema=schema, # Our multilingual schema
index_params=index_params # Our search index configuration
)
client.dropCollection(DropCollectionReq.builder()
.collectionName("multilingual_documents")
.build());
CreateCollectionReq requestCreate = CreateCollectionReq.builder()
.collectionName("multilingual_documents")
.collectionSchema(collectionSchema)
.indexParams(indexes)
.build();
client.createCollection(requestCreate);
const COLLECTION_NAME = "multilingual_documents";
// Create the collection
await client.createCollection({
collection_name: COLLECTION_NAME,
schema: schema,
index_params: index_params,
functions: functions
});
err = client.CreateCollection(ctx,
milvusclient.NewCreateCollectionOption("multilingual_documents", schema).
WithIndexOptions(indexOption))
if err != nil {
fmt.Println(err.Error())
// handle error
}
# restful
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/collections/create" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--data "{
\"collectionName\": \"multilingual_documents\",
\"schema\": $schema,
\"indexParams\": $IndexParams
}"
此时,Zilliz Cloud 已创建一个支持多语言 Analyzer 的空集合,准备接收数据。
步骤 3:插入示例数据
在向多语言 Collection 中添加文档时,每个文档必须同时包含文本内容和语言标识符:
- Python
- Java
- NodeJS
- Go
- cURL
# Prepare multilingual documents
documents = [
# English documents
{
"text": "Artificial intelligence is transforming technology",
"language": "english", # Using full language name
},
{
"text": "Machine learning models require large datasets",
"language": "en", # Using our defined alias
},
# Chinese documents
{
"text": "人工智能正在改变技术领域",
"language": "chinese", # Using full language name
},
{
"text": "机器学习模型需要大型数据集",
"language": "cn", # Using our defined alias
},
]
# Insert the documents
result = client.insert(COLLECTION_NAME, documents)
# Print results
inserted = result["insert_count"]
print(f"Successfully inserted {inserted} documents")
print("Documents by language: 2 English, 2 Chinese")
# Expected output:
# Successfully inserted 4 documents
# Documents by language: 2 English, 2 Chinese
List<String> texts = Arrays.asList(
"Artificial intelligence is transforming technology",
"Machine learning models require large datasets",
"人工智能正在改变技术领域",
"机器学习模型需要大型数据集"
);
List<String> languages = Arrays.asList(
"english", "en", "chinese", "cn"
);
List<JsonObject> rows = new ArrayList<>();
for (int i = 0; i < texts.size(); i++) {
JsonObject row = new JsonObject();
row.addProperty("text", texts.get(i));
row.addProperty("language", languages.get(i));
rows.add(row);
}
client.insert(InsertReq.builder()
.collectionName("multilingual_documents")
.data(rows)
.build());
// Prepare multilingual documents
const documents = [
// English documents
{
text: "Artificial intelligence is transforming technology",
language: "english",
},
{
text: "Machine learning models require large datasets",
language: "en",
},
// Chinese documents
{
text: "人工智能正在改变技术领域",
language: "chinese",
},
{
text: "机器学习模型需要大型数据集",
language: "cn",
},
];
// Insert the documents
const result = await client.insert({
collection_name: COLLECTION_NAME,
data: documents,
});
// Print results
const inserted = result.insert_count;
console.log(\`Successfully inserted ${inserted} documents\`);
console.log("Documents by language: 2 English, 2 Chinese");
// Expected output:
// Successfully inserted 4 documents
// Documents by language: 2 English, 2 Chinese
column1 := column.NewColumnVarChar("text",
[]string{
"Artificial intelligence is transforming technology",
"Machine learning models require large datasets",
"人工智能正在改变技术领域",
"机器学习模型需要大型数据集",
})
column2 := column.NewColumnVarChar("language",
[]string{"english", "en", "chinese", "cn"})
_, err = client.Insert(ctx, milvusclient.NewColumnBasedInsertOption("multilingual_documents").
WithColumns(column1, column2),
)
if err != nil {
fmt.Println(err.Error())
// handle err
}
# restful
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/insert" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--data '{
"collectionName": "multilingual_documents",
"data": [
{
"text": "Artificial intelligence is transforming technology",
"language": "english"
},
{
"text": "Machine learning models require large datasets",
"language": "en"
},
{
"text": "人工智能正在改变技术领域",
"language": "chinese"
},
{
"text": "机器学习模型需要大型数据集",
"language": "cn"
}
]
}'
在插入过程中,Zilliz Cloud 会执行以下操作:
-
读取每个文档的语言字段
-
将对应的 Analyzer 应用于文本字段
-
通过 BM25 函数生成稀疏向量表示
-
存储原始文本和生成的稀疏向量
你无需直接提供稀疏向量;BM25 函数会基于你的文本和指定的 Analyzer 自动生成。
步骤 4:执行搜索操作
使用英文 Analyzer
在使用多语言 Analyzer 进行搜索时,search_params 包含关键配置:
-
metric_type="BM25":必须与索引配置一致。 -
analyzer_name="english":指定应用于查询文本的 Analyzer。该设置与存储文档时使用的 Analyzer 相互独立。 -
params={"drop_ratio_search": "0"}:控制 BM25 的特定行为,此处表示保留查询中的所有词项。更多信息请参考 稀疏向量。
- Python
- Java
- NodeJS
- Go
- cURL
search_params = {
"metric_type": "BM25", # Must match index configuration
"analyzer_name": "english", # Analyzer that matches the query language
"drop_ratio_search": "0", # Keep all terms in search (tweak as needed)
}
# Execute the search
english_results = client.search(
collection_name=COLLECTION_NAME, # Collection to search
data=["artificial intelligence"], # Query text
anns_field="sparse", # Field to search against
search_params=search_params, # Search configuration
limit=3, # Max results to return
output_fields=["text", "language"], # Fields to include in the output
consistency_level="Bounded", # Data‑consistency guarantee
)
# Display English search results
print("\n=== English Search Results ===")
for i, hit in enumerate(english_results[0]):
print(f"{i+1}. [{hit.score:.4f}] {hit.entity.get('text')} "
f"(Language: {hit.entity.get('language')})")
# Expected output (English Search Results):
# 1. [2.7881] Artificial intelligence is transforming technology (Language: english)
Map<String,Object> searchParams = new HashMap<>();
searchParams.put("metric_type", "BM25");
searchParams.put("analyzer_name", "english");
searchParams.put("drop_ratio_search", 0);
SearchResp searchResp = client.search(SearchReq.builder()
.collectionName("multilingual_documents")
.data(Collections.singletonList(new EmbeddedText("artificial intelligence")))
.annsField("sparse")
.topK(3)
.searchParams(searchParams)
.outputFields(Arrays.asList("text", "language"))
.build());
System.out.println("\n=== English Search Results ===");
List<List<SearchResp.SearchResult>> searchResults = searchResp.getSearchResults();
for (List<SearchResp.SearchResult> results : searchResults) {
for (SearchResp.SearchResult result : results) {
System.out.printf("Score: %f, %s\n", result.getScore(), result.getEntity().toString());
}
}
// Execute the search
const english_results = await client.search({
collection_name: COLLECTION_NAME,
data: ["artificial intelligence"],
anns_field: "sparse",
params: {
metric_type: "BM25",
analyzer_name: "english",
drop_ratio_search: "0",
},
limit: 3,
output_fields: ["text", "language"],
consistency_level: "Bounded",
});
// Display English search results
console.log("\n=== English Search Results ===");
english_results.results.forEach((hit, i) => {
console.log(
\`${i + 1}. [${hit.score.toFixed(4)}] ${hit.entity.text} \` +
\`(Language: ${hit.entity.language})\`
);
});
annSearchParams := index.NewCustomAnnParam()
annSearchParams.WithExtraParam("metric_type", "BM25")
annSearchParams.WithExtraParam("analyzer_name", "english")
annSearchParams.WithExtraParam("drop_ratio_search", 0)
resultSets, err := client.Search(ctx, milvusclient.NewSearchOption(
"multilingual_documents", // collectionName
3, // limit
[]entity.Vector{entity.Text("artificial intelligence")},
).WithANNSField("sparse").
WithAnnParam(annSearchParams).
WithOutputFields("text", "language"))
if err != nil {
fmt.Println(err.Error())
// handle error
}
for _, resultSet := range resultSets {
for i := 0; i < len(resultSet.Scores); i++ {
text, _ := resultSet.GetColumn("text").GetAsString(i)
lang, _ := resultSet.GetColumn("language").GetAsString(i)
fmt.Println("Score: ", resultSet.Scores[i], "Text: ", text, "Language:", lang)
}
}
# restful
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/search" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--data '{
"collectionName": "multilingual_documents",
"data": ["artificial intelligence"],
"annsField": "sparse",
"limit": 3,
"searchParams": {
"metric_type": "BM25",
"analyzer_name": "english",
"drop_ratio_search": "0"
},
"outputFields": ["text", "language"],
"consistencyLevel": "Strong"
}'
使用中文 Analyzer
此示例演示了如何切换为中文 Analyzer(使用其别名 "cn")来处理不同的查询文本。其他参数保持不变,但查询文本会按照中文特有的分词规则进行处理。
- Python
- Java
- NodeJS
- Go
- cURL
search_params["analyzer_name"] = "cn"
chinese_results = client.search(
collection_name=COLLECTION_NAME, # Collection to search
data=["人工智能"], # Query text
anns_field="sparse", # Field to search against
search_params=search_params, # Search configuration
limit=3, # Max results to return
output_fields=["text", "language"], # Fields to include in the output
consistency_level="Bounded", # Data‑consistency guarantee
)
# Display Chinese search results
print("\n=== Chinese Search Results ===")
for i, hit in enumerate(chinese_results[0]):
print(f"{i+1}. [{hit.score:.4f}] {hit.entity.get('text')} "
f"(Language: {hit.entity.get('language')})")
# Expected output (Chinese Search Results):
# 1. [3.3814] 人工智能正在改变技术领域 (Language: chinese)
searchParams.put("analyzer_name", "cn");
searchResp = client.search(SearchReq.builder()
.collectionName("multilingual_documents")
.data(Collections.singletonList(new EmbeddedText("人工智能")))
.annsField("sparse")
.topK(3)
.searchParams(searchParams)
.outputFields(Arrays.asList("text", "language"))
.build());
System.out.println("\n=== Chinese Search Results ===");
searchResults = searchResp.getSearchResults();
for (List<SearchResp.SearchResult> results : searchResults) {
for (SearchResp.SearchResult result : results) {
System.out.printf("Score: %f, %s\n", result.getScore(), result.getEntity().toString());
}
}
// Execute the search
const cn_results = await client.search({
collection_name: COLLECTION_NAME,
data: ["人工智能"],
anns_field: "sparse",
params: {
metric_type: "BM25",
analyzer_name: "cn",
drop_ratio_search: "0",
},
limit: 3,
output_fields: ["text", "language"],
consistency_level: "Bounded",
});
// Display Chinese search results
console.log("\n=== Chinese Search Results ===");
cn_results.results.forEach((hit, i) => {
console.log(
\`${i + 1}. [${hit.score.toFixed(4)}] ${hit.entity.text} \` +
\`(Language: ${hit.entity.language})\`
);
});
annSearchParams.WithExtraParam("analyzer_name", "cn")
resultSets, err = client.Search(ctx, milvusclient.NewSearchOption(
"multilingual_documents", // collectionName
3, // limit
[]entity.Vector{entity.Text("人工智能")},
).WithANNSField("sparse").
WithAnnParam(annSearchParams).
WithOutputFields("text", "language"))
if err != nil {
fmt.Println(err.Error())
// handle error
}
for _, resultSet := range resultSets {
for i := 0; i < len(resultSet.Scores); i++ {
text, _ := resultSet.GetColumn("text").GetAsString(i)
lang, _ := resultSet.GetColumn("language").GetAsString(i)
fmt.Println("Score: ", resultSet.Scores[i], "Text: ", text, "Language:", lang)
}
}
# restful
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/search" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--data '{
"collectionName": "multilingual_documents",
"data": ["人工智能"],
"annsField": "sparse",
"limit": 3,
"searchParams": {
"analyzer_name": "cn"
},
"outputFields": ["text", "language"],
"consistencyLevel": "Strong"
}'