图像数据即将作废
您可以通过 Web 控制台或 RESTful API 创建、运行和管理 Pipelines。Web 控制台操作更简单直观,但 RESTful API 可提供更多灵活性。
本文将介绍如何创建图像 Pipeline、进行以图搜图并删除 Pipeline。
Zilliz Cloud Pipelines 服务正处在逐步下线中,将于 2025 年第二季度末停止服务,被 “Data In, Data Out” 的新功能取代。该功能旨在简化 Milvus 和 Zilliz Cloud 中的向量化流程。自 2025 年 1 月 10 日起,Zilliz Cloud Pipelines 将不再接受新用户注册。现有用户可在每月 100 元人民币免费试用额度内继续使用服务直至下线日期。该服务不提供 SLA 支持。建议您使用模型提供商的Embedding API 或开源模型生成向量。
前提条件与限制
-
请确保您创建部署在阿里云(杭州)的集群。
-
同一项目下,您可最多创建 100 个同一类型的 Pipelines。更多详情,请参考使用限制。
摄取图像数据
摄取图像数据包含两个步骤:创建 Ingestion Pipeline 和运行 Ingestion Pipeline。
创建图像 Ingestion Pipeline
- Cloud Console
- cURL
-
打开项目。
-
点击左侧导航栏中的 Pipelines。 选中概览标签页,并切换到 Pipelines。点击 + Pipeline。
-
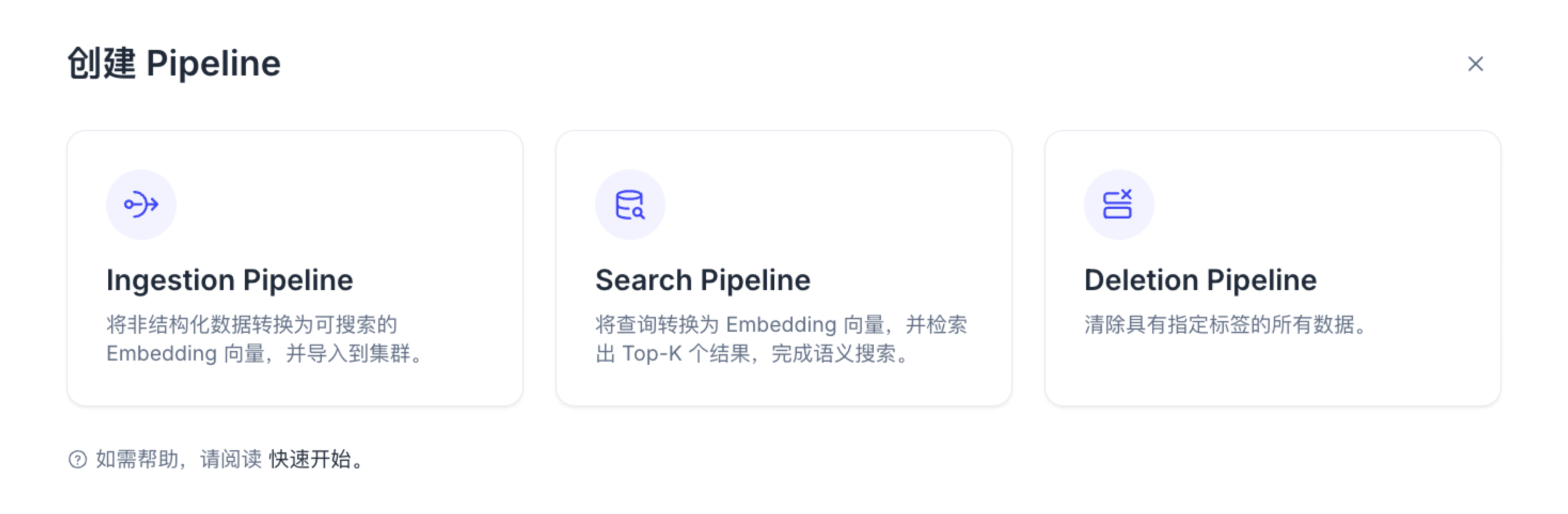
选择需要创建的 Pipeline 类型。点击 Ingestion Pipeline 一栏中的 + Pipeline 按钮。
-
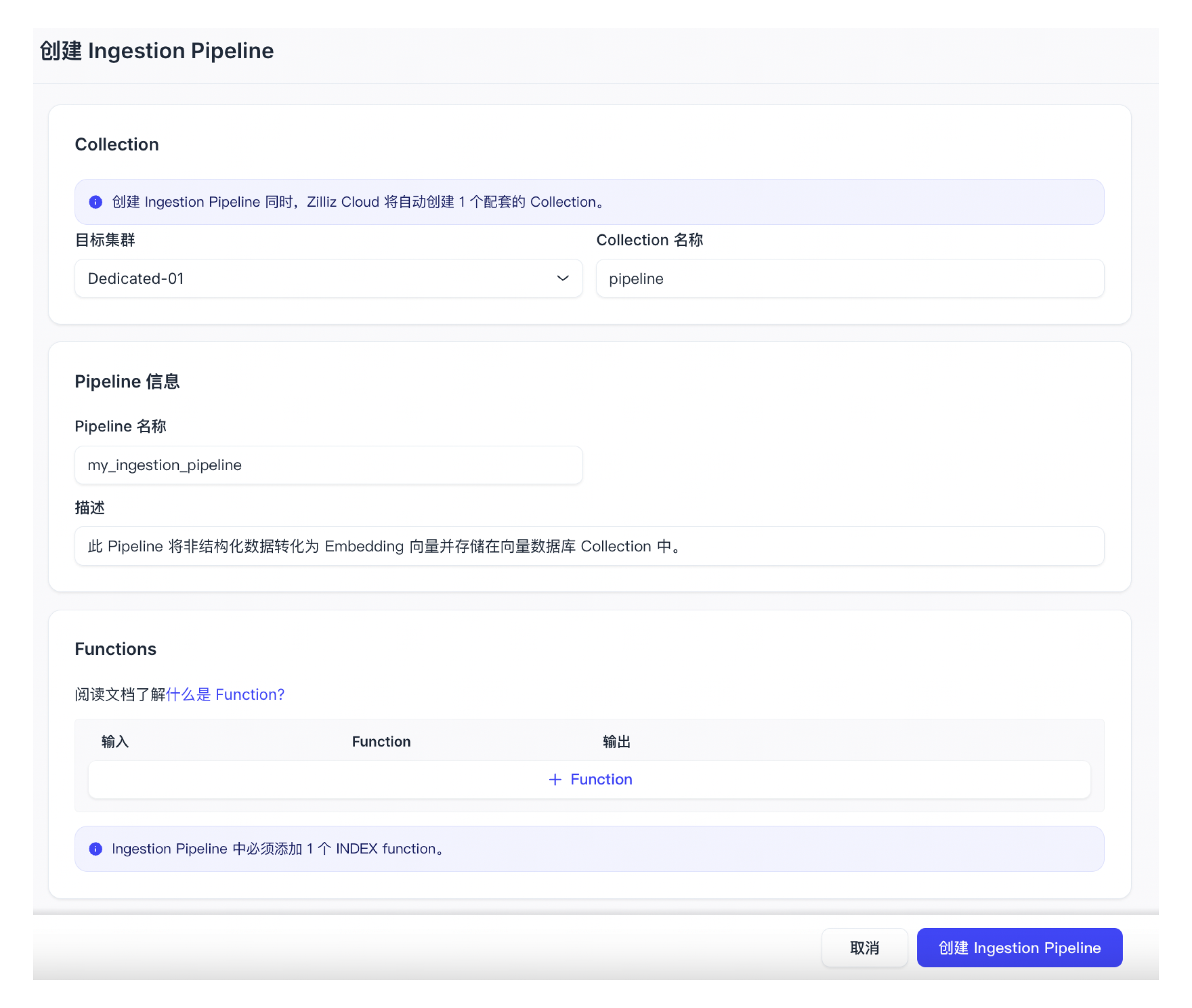
配置 Ingestion Pipeline。
参数
说明
目标集群
自动创建 Collection 所属的集群。目前仅支持部署在阿里云(杭州)的集群。
Collection 名称
自动创建的 Collection 的名称。
Pipeline 名称
新创建的 Ingestion Pipeline 的名称。名称中只可包含小写字母、数字和下划线。
描述 (可选)
对新创建的 Ingestion Pipeline 的描述。
-
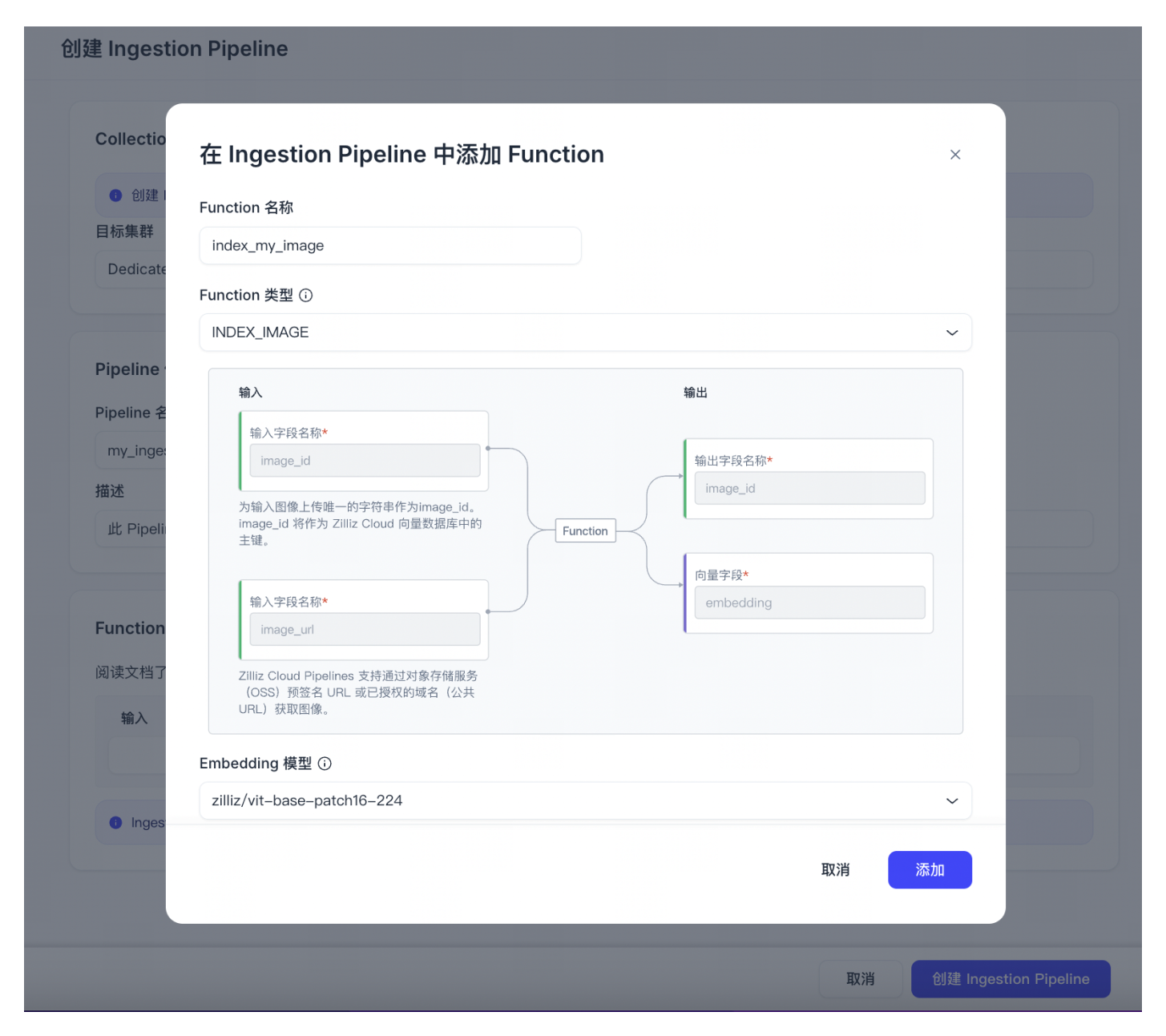
添加 Function。1 个 Ingestion pipeline 中只可添加 1 个 INDEX Function。
-
输入 Function 名称。
-
选择 INDEX_IMAGE Function。该 Function 可以将 URL 中的图像转换为 Embedding 向量。
-
选择用于生成向量的 Embedding 模型。目前 Zilliz Cloud Pipelines 共提供两种 Embedding 模型:zilliz/vit-base-patch16-224 和 zilliz/clip-vit-base-patch32。
Embedding 模型
说明
zilliz/vit-base-patch16-224
Google 开源的 Vision Transformer (ViT) encoder 模型(类似于 BERT),在大量图像数据上进行预训练,可用于将图像的内容语义转化为向量空间中的 Embedding 向量。该模型托管于 Zilliz Cloud 之上,可大幅降低延时。
zilliz/clip-vit-base-patch32
OpenAI 发布的多模态模型。视觉模型和文本模型共同将图像和文本转换为同一向量空间中的 Embedding 向量,实现数据和文案信息两种模态信息的语义搜索。该模型托管于 Zilliz Cloud 之上,可大幅降低延时。
-
点击添加。
-
-
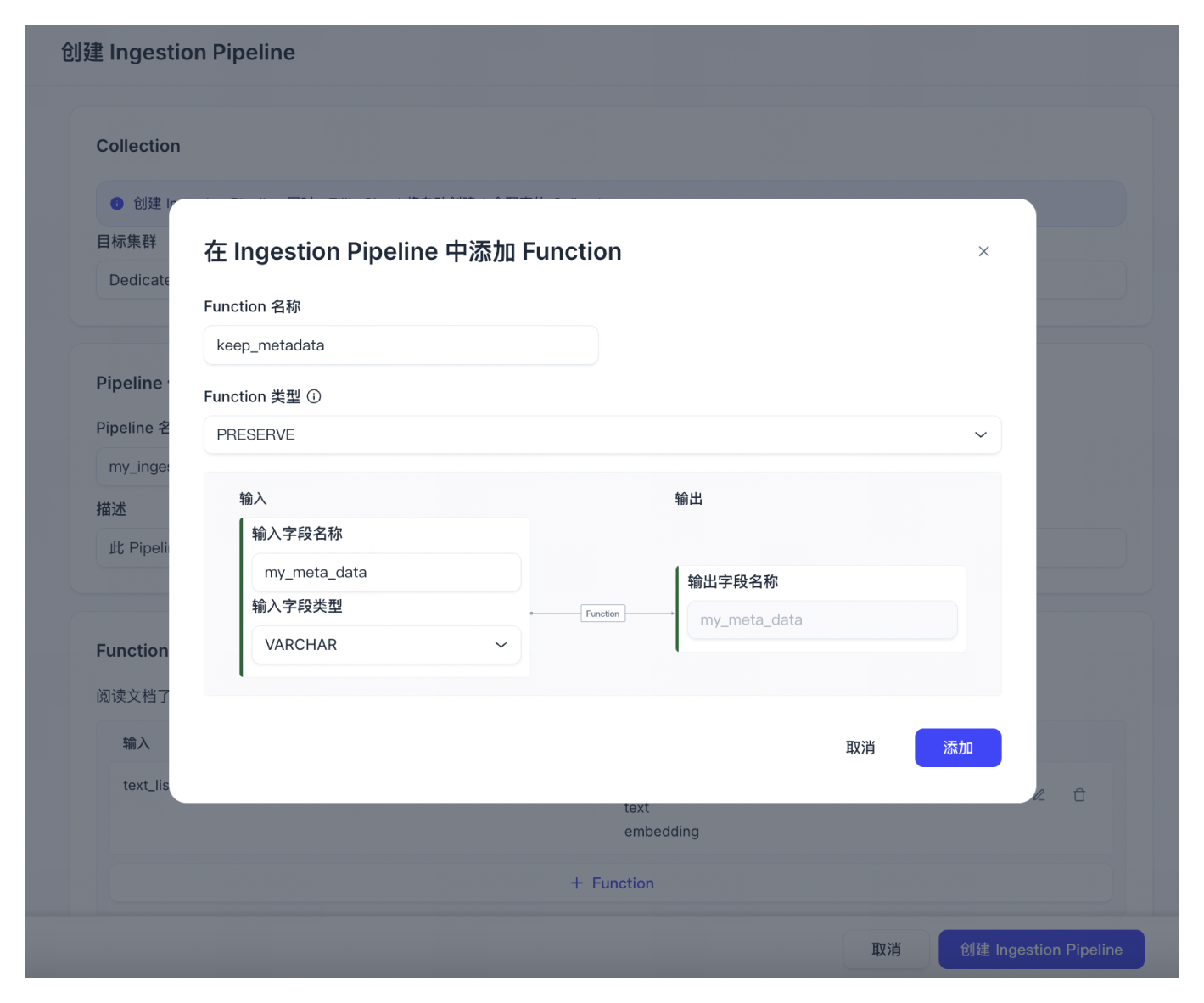
(可选) 添加 PRESERVE Function。PRESERVE Function 在 Collection 中添加标量字段,用于保留文档元数据。
📘说明每个 Ingestion Pipeline 中最多可添加 50 个 PRESERVE Function。
-
点击 + Function。
-
输入 Function 名称。
-
配置输入字段名称和数据类型。支持的数据字段类型包括 Bool、Int8、Int16、Int32、Int64、Float、Double 和 VarChar。
📘说明目前,输出字段名称必须与输入字段名称保持一致。在运行 Ingestion Pipeline 时,您将使用到输入字段名称。而输出字段名称用于自动生成的 Collection Schema 中作为保留的标量字段名称。
字段类型为 VarChar 时,字符串最大长度为 4,000 个字符,且只可包含数字、字母。
在标量字段中存储日期时,我们推荐使用 Int16 的数据类型。存储时间时,我们推荐使用 Int32 的数据类型。
-
点击添加。
-
-
点击创建 Ingestion Pipeline。
-
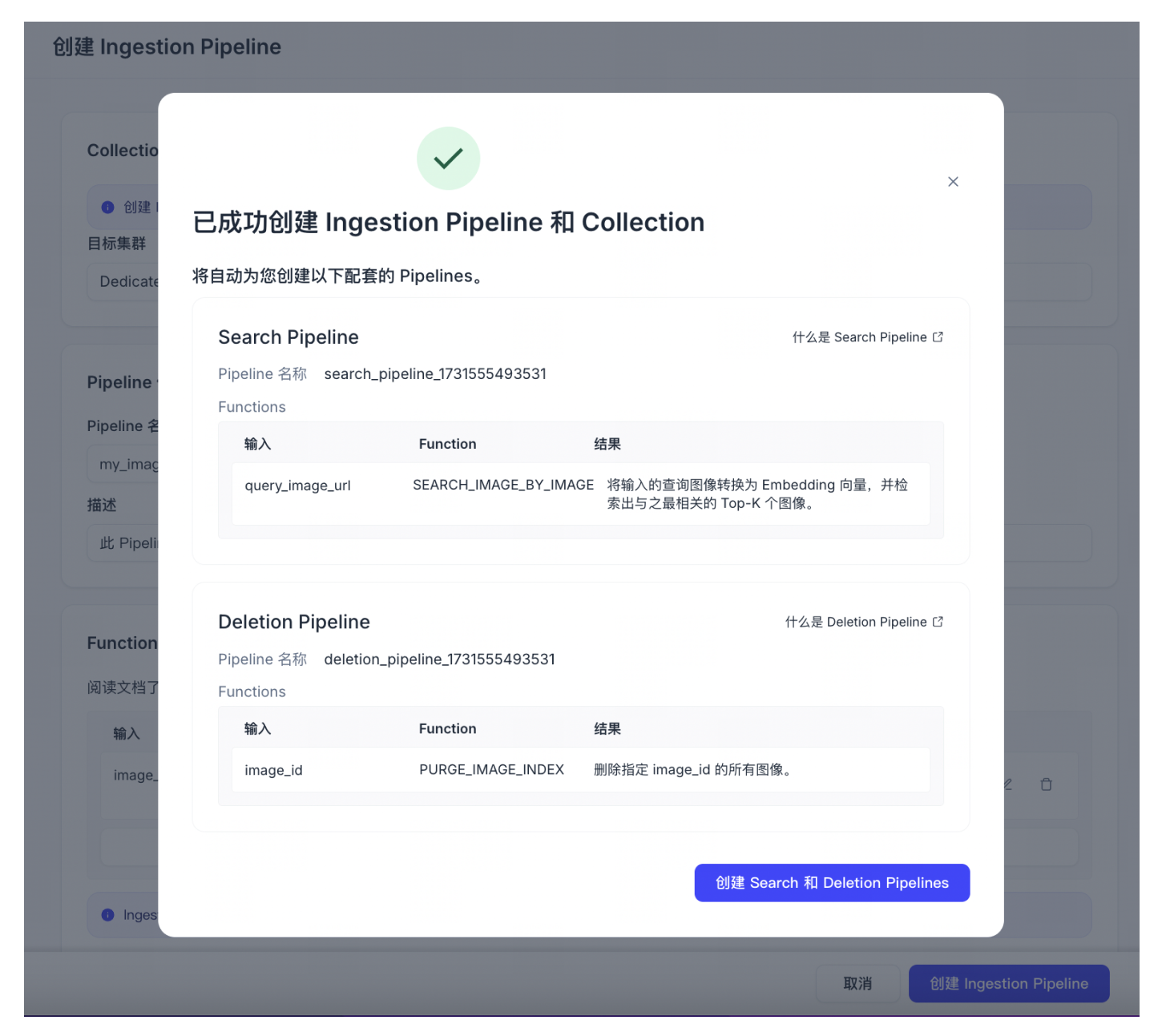
继续创建 Search pipeline 和 Deletion pipeline。创建的 Search 和 Deletion Pipeline 可适应配套刚才创建的Ingestion Pipeline。
 📘说明
📘说明自动创建的 Search Pipeline 默认关闭 Reranker 功能,如需使用 Reranker,请手动创建一个新的 Search Pipeline。
以下示例代码创建了 1 个名称为 my_image_ingestion_pipeline 的 Ingestion Pipeline,并添加了 1 个 INDEX_IMAGE Function 和 1 个 PRESERVE Function。
curl --request POST \
--header "Content-Type: application/json" \
--header "Authorization: Bearer ${YOUR_API_KEY}" \
--url "https://controller.api.{cloud-region}.cloud.zilliz.com.cn/v1/pipelines" \
-d '{
"name": "my_image_ingestion_pipeline",
"clusterId": "inxx-xxxxxxxxxxxxxxx",
"projectId": "proj-xxxx",
"collectionName": "my_collection",
"description": "A pipeline that converts an image into vector embeddings and store in efficient index for search.",
"type": "INGESTION",
"functions": [
{
"name": "index_my_image",
"action": "INDEX_IMAGE",
"embedding": "zilliz/vit-base-patch16-224"
},
{
"name": "keep_image_tag",
"action": "PRESERVE",
"inputField": "image_title",
"outputField": "image_title",
"fieldType": "VarChar"
}
]
}'
以下为参数说明:
-
YOUR_API_KEY: 验证 API 请求的鉴权信息。了解如何查看 API 密钥。 -
cloud-region: 集群所在云服务地域的 ID。目前仅支持ali-cn-hangzhou。 -
clusterId: 创建 Pipeline 所属的集群 ID。目前,仅支持部署在阿里云(杭州)的集群。了解如何获取集群 ID。 -
projectId: 创建 Pipeline 所属的项目 ID。了解如何获取项目 ID。 -
collectionName: 与 Pipeline 同步自动创建的 Collection 名称。或者,您也可以指定一个已有的 Collection。 -
name: 创建的 Pipeline 名称。Pipeline 名称应该在 3-64 个字符内,且只可包含数字、字母和下划线。 -
description(可选): 创建的 Pipeline 描述。 -
type: 创建的 Pipeline 类型。目前,可创建的 Pipeline 类型包括INGESTION、SEARCH和DELETION。 -
functions: Pipeline 中添加的 Function。1 个 Ingestion pipeline 中只可添加 1 个 INDEX Function 和至多 50 个 PRESERVE Function。-
name: Function 名称。Function 名称应该在 3-64 个字符内,且只可包含数字、字母和下划线。 -
action: Function 类型。您可以在 Ingestion Pipeline 中添加的 Function 类型包括:INDEX_DOC、INDEX_TEXT、INDEX_IMAGE和PRESERVE。 -
language: 文档语言。可选择的语言包括ENGLISH(英语) 和CHINESE(中文)。(仅INDEX_TEXT和INDEX_DOCFunction 中包含此参数。) -
embedding: 用于生成向量的 Embedding 模型。 (仅INDEXFunction 中包含此参数。)Embedding 模型
说明
zilliz/vit-base-patch16-224
Google 开源的 Vision Transformer (ViT) encoder 模型(类似于 BERT),在大量图像数据上进行预训练,可用于将图像的内容语义转化为向量空间中的 Embedding 向量。该模型托管于 Zilliz Cloud 之上,可大幅降低延时。
zilliz/clip-vit-base-patch32
OpenAI 发布的多模态模型。视觉模型和文本模型共同将图像和文本转换为同一向量空间中的 Embedding 向量,实现数据和文案信息两种模态信息的语义搜索。该模型托管于 Zilliz Cloud 之上,可大幅降低延时。
-
-
inputField: 输入字段名称。 您可以自定义输入字段名称,但需要与outputField保持一致。(仅PRESERVEFunction 中包含此参数。) -
outputField: 输出字段名称。该字段将的值将用于构成 Collection Schema。outputField字段值应该与inputField字段值保持一致。 (仅PRESERVEFunction 中包含此参数。) -
fieldType: 输入和输出字段的字段类型。可选的值包括:Bool、Int8、Int16、Int32、Int64、Float、Double和VarChar。 (仅PRESERVEFunction 中包含此参数。)📘说明在标量字段中存储日期时,我们推荐使用 Int16 的数据类型。存储时间时,我们推荐使用 Int32 的数据类型。
对于
VarChar字段类型而言,字段数据的最大长度max_length不得超过 4,000。
如果请求返回以下类似内容,则表示 Ingestion Pipeline 创建成功:
{
"code": 200,
"data": {
"pipelineId": "pipe-xxxx",
"name": "my_image_ingestion_pipeline",
"type": "INGESTION",
"createTimestamp": 1721187300000,
"clusterId": "in03-***************",
"collectionName": "my_collection"
"description": "A pipeline that converts an image into vector embeddings and store in efficient index for search.",
"status": "SERVING",
"totalUsage": {
"embedding": 0
},
"functions": [
{
"action": "INDEX_IMAGE",
"name": "index_my_image",
"inputFields": ["image_url", "image_id"],
"embedding": "zilliz/vit-base-patch16-224"
},
{
"action": "PRESERVE",
"name": "keep_image_tag",
"inputField": "image_title",
"outputField": "image_title",
"fieldType": "VarChar"
}
]
}
}
总用量 totalUsage 非实时更新,数据统计可能会有几小时延迟。
Ingestion Pipeline 创建成功后,Zilliz Cloud 将进行重名检查。如果集群中没有该名称的 Collection,将自动创建名称为 my_collection 的新 Collection。如果已存在同名的 Collection,Zilliz Cloud Pipelines 会继续检查该已有 Collection 的 Schema 是否与 Pipeline 中定义的一致。
该 Collection 中包含 3 个字段:2 个 INDEX_IMAGE function 的输出字段和 1 个 PRESERVE function 的输出字段。Collection Schema 如下所示:
image_id | embedding | image_title |
|---|
运行图像 Ingestion Pipeline
- Cloud Console
- cURL
-
点击 Ingestion Pipeline 右侧的 "▶︎" 按钮。 或者您可以点击 Playground 选项卡。

-
在
image_id和image_url字段中输入需要摄取的图像信息。如您添加了 PRESERVE Function,请在该 Function 定义的字段中输入需要保留的元数据信息。点击运行。 -
查看运行结果。
以下示例代码用于运行 Ingestion pipeline my_image_ingestion_pipeline。
curl --request POST \
--header "Content-Type: application/json" \
--header "Authorization: Bearer ${YOUR_API_KEY}" \
--url "https://controller.api.{cloud-region}.cloud.zilliz.com.cn/v1/pipelines/${YOUR_PIPELINE_ID}/run" \
-d '{
"data": {
"image_id": "my-img-123456",
"image_url": "xxx",
"image_title": "A cute yellow cat"
}
}'
以下为参数说明:
-
YOUR_API_KEY: 验证 API 请求的鉴权信息。了解如何查看 API 密钥。 -
cloud-region: 集群的云服务地域。目前仅支持ali-cn-hangzhou。 -
image_id: 存储在 OSS 中的图像 ID。 -
image_url: 存储在 OSS 中的图像 URL。URL 包含中文时,请勿使用编码后的 URL。您可以使用 UTF-8 编码的 URL。请确保 URL 有效期大于 1 小时。 -
image_title:需要保留的元数据字段。
请求返回以下类似内容:
{
"code": 200,
"data": {
"num_entities": 1,
"usage": {
"embedding": 1
}
}
}
搜索图像数据
搜索数据前,需要先创建并运行 Search Pipeline。与 Ingestion 和 Deletion Pipelines 不同,Search Pipeline 创建时是在 Function 级别定义集群和 Collection,而非在 Pipeline 层级。这是因为 Zilliz Cloud 支持同时从多个 Collection 搜索数据。
Zilliz Cloud 支持两种搜索图像数据的方式:以图搜图或以文本搜图。
以图搜图
创建图像 Search Pipeline
- Cloud Console
- cURL
-
打开项目。
-
点击左侧导航栏中的 Pipelines。 选中概览标签页,并切换到 Pipelines。点击 + Pipeline。
-
选择需要创建的 Pipeline 类型。点击 Search Pipeline 一栏中的 + Pipeline 按钮。
-
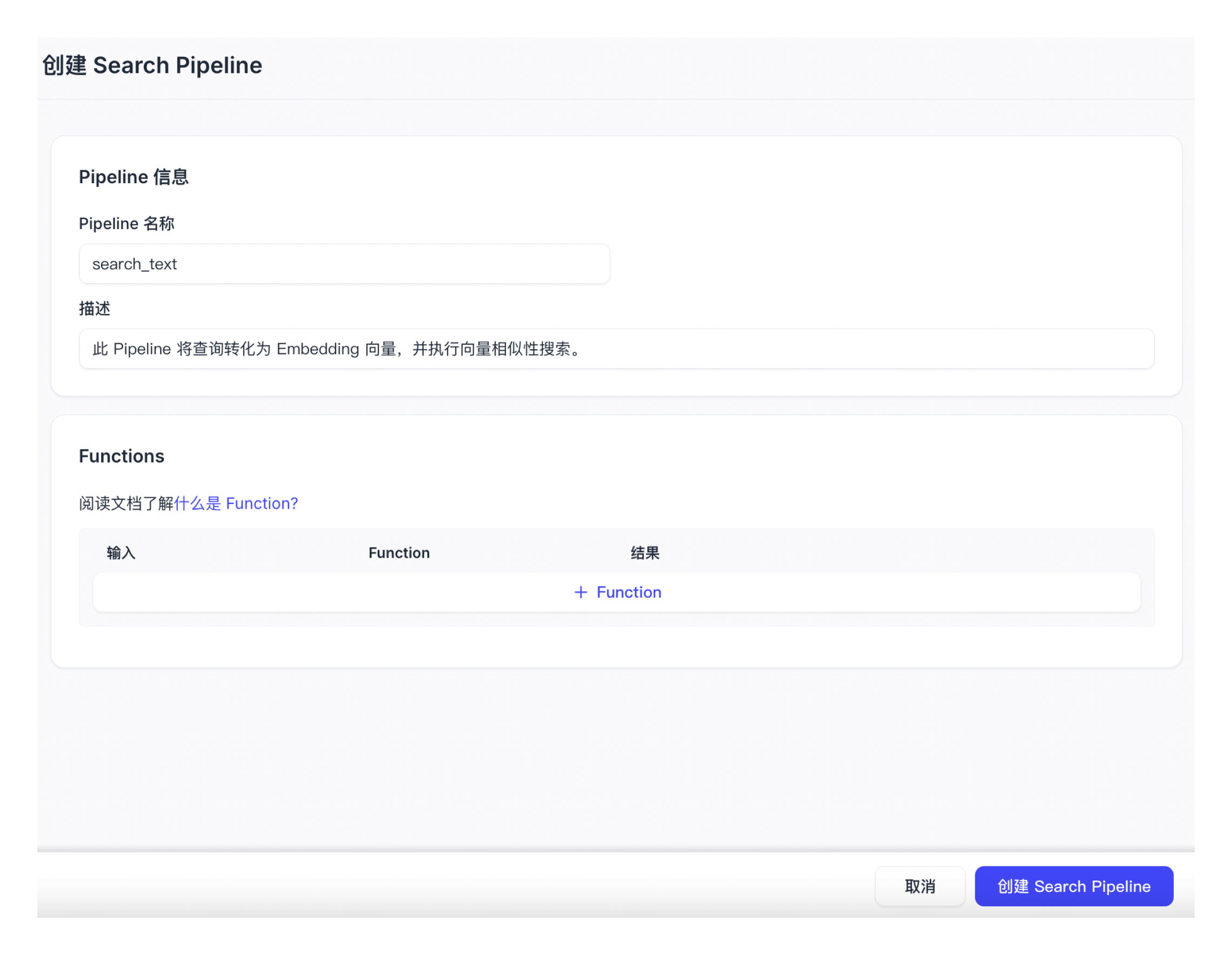
配置 Search Pipeline。
参数
说明
Pipeline 名称
新创建的 Ingestion Pipeline 的名称。名称中只可包含小写字母、数字和下划线。
描述 (可选)
对新创建的 Ingestion Pipeline 的描述。
-
点击 + Function 添加 Function。 1 个 Search pipeline 中只可添加 1 个 Function。
-
输入函数名称。
-
选择目标集群和目标 Collection。目标集群必须为部署在阿里云(杭州)的活跃集群。目标 Collection 必须为创建 Ingestion pipeline 时自动创建的 Collection,否则创建的 Search Pipeline 将不兼容。
-
Function 类型选择 SEARCH_IMAGE_BY_IMAGE。该 Function 可以将输入的查询图像转换为 Embedding 向量,并检索出与之最相关的 Top-K 个图像。
-
点击添加。

-
-
点击创建 Search Pipeline。
以下示例代码创建了 1 个名称为 my_image_search_pipeline 的 Search Pipeline,并添加了 1 个 SEARCH_IMAGE_BY_IMAGE Function。
curl --request POST \
--header "Content-Type: application/json" \
--header "Authorization: Bearer ${YOUR_API_KEY}" \
--url "https://controller.api.{cloud-region}.cloud.zilliz.com.cn/v1/pipelines" \
-d '{
"projectId": "proj-xxxx",
"name": "my_image_search_pipeline",
"description": "A pipeline that searches image by image.",
"type": "SEARCH",
"functions": [
{
"name": "search_image_by_image",
"action": "SEARCH_IMAGE_BY_IMAGE",
"embedding": "zilliz/vit-base-patch16-224",
"clusterId": "inxx-xxxxxxxxxxxxxxx",
"collectionName": "my_collection"
}
]
}'
以下为参数说明:
-
YOUR_API_KEY: 验证 API 请求的鉴权信息。了解如何查看 API 密钥。 -
cloud-region: 集群所在云服务地域的 ID。目前仅支持ali-cn-hangzhou。 -
projectId: 创建 Pipeline 所属的项目 ID。了解如何获取项目 ID。 -
name: 创建的 Pipeline 名称。Pipeline 名称应该在 3-64 个字符内,且只可包含数字、字母和下划线。 -
description(可选):创建的 Pipeline 描述。 -
type: 创建的 Pipeline 类型。目前,可创建的 Pipeline 类型包括INGESTION、SEARCH和DELETION。 -
functions: Pipeline 中添加的 Function。1 个 Search Pipeline 中仅可添加 1 个 Function。-
name: Function 名称。Function 名称应该在 3-64 个字符内,且只可包含数字、字母和下划线。 -
action: Function 类型。支持的类型包括:SEARCH_DOC_CHUNK、SEARCH_TEXT、SEARCH_IMAGE_BY_IMAGE、SEARCH_IMAGE_BY_TEXT。 -
inputField: 输入字段名称。您可以自由配置该字段的值。但是在运行 Pipeline 时,您需要使用现在定义的输入字段名称。 -
clusterId: 创建 Pipeline 所属的集群 ID。目前,仅支持部署在阿里云(杭州)的集群。了解如何获取集群 ID。 -
collectionName: 创建 Pipeline 所属的 Collection 名称。 -
embedding:向量搜索时使用的 Embedding 模型。该模型需要与所选 Collection 中的 Embedding 模型保持一致。
-
如果请求返回以下类似内容,则表示 Search Pipeline 创建成功:
{
"code": 200,
"data": {
"pipelineId": "pipe-xxxx",
"name": "my_image_search_pipeline",
"type": "SEARCH",
"createTimestamp": 1721187300000,
"description": "A pipeline that searches image by image.",
"status": "SERVING",
"totalUsage": {
"embedding": 0
},
"functions":
{
"action": "SEARCH_IMAGE_BY_IMAGE",
"name": "search_image_by_image",
"inputFields": ["query_image_url"],
"clusterId": "in03-***************",
"collectionName": "my_collection",
"embedding": "zilliz/vit-base-patch16-224"
}
}
}
总用量 totalUsage 非实时更新,数据统计可能会有几小时延迟。
运行图像 Search Pipeline
- Cloud Console
- cURL
-
点击 Search Pipeline 右侧的 "▶︎" 按钮。 或者您可以点击 Playground 选项卡。
-
输入查询文本。点击运行。
-
查看运行结果。
以下示例代码用于运行 Search pipeline my_image_search_pipeline。
curl --request POST \
--header "Content-Type: application/json" \
--header "Authorization: Bearer ${YOUR_API_KEY}" \
--url "https://controller.api.{cloud-region}.cloud.zilliz.com.cn/v1/pipelines/${YOUR_PIPELINE_ID}/run" \
-d '{
"data": {
"query_image_url": "xxx"
},
"params":{
"limit": 1,
"offset": 0,
"outputFields": ["image_id", "image_title"],
"filter": "id >= 0",
}
}'
以下为参数说明:
-
YOUR_API_KEY: 验证 API 请求的鉴权信息。了解如何查看 API 密钥。 -
cloud-region: 集群的云服务地域。目前仅支持ali-cn-hangzhou。 -
query_text: 语义搜索的查询文本。 -
params: 搜索相关参数。-
limit: 返回的 Entity 数量。该参数值为 1-500 之间的整数。limit和offset参数值总和应小于 1024。 -
offset: 在搜索结果中跳过的 Entity 数量。最大值为 1024。limit和offset参数值总和应小于 1024。 -
outputFields: 在搜索结果中一同返回的输出字段。id、distance和chunk_text为默认输出字段。 -
filter: 搜索时的过滤条件。
-
请求返回以下类似内容:
{
"code": 200,
"data": {
"result": [
{
"id": "my-img-123456",
"distance": 0.40448662638664246,
"image_id": "my-img-123456",
"image_title": "A cute yellow cat"
}
],
"usage": {
"embedding": 1
}
}
}
以文本搜图
创建图像 Search Pipeline
- Cloud Console
- cURL
-
打开项目。
-
点击左侧导航栏中的 Pipelines。 选中概览标签页,并切换到 Pipelines。点击 + Pipeline。
-
选择需要创建的 Pipeline 类型。点击 Search Pipeline 一栏中的 + Pipeline 按钮。
-
配置 Search Pipeline。
参数
说明
Pipeline 名称
新创建的 Ingestion Pipeline 的名称。名称中只可包含小写字母、数字和下划线。
描述 (可选)
对新创建的 Ingestion Pipeline 的描述。
-
点击 + Function 添加 Function。 1 个 Search pipeline 中只可添加 1 个 Function。
-
输入函数名称。
-
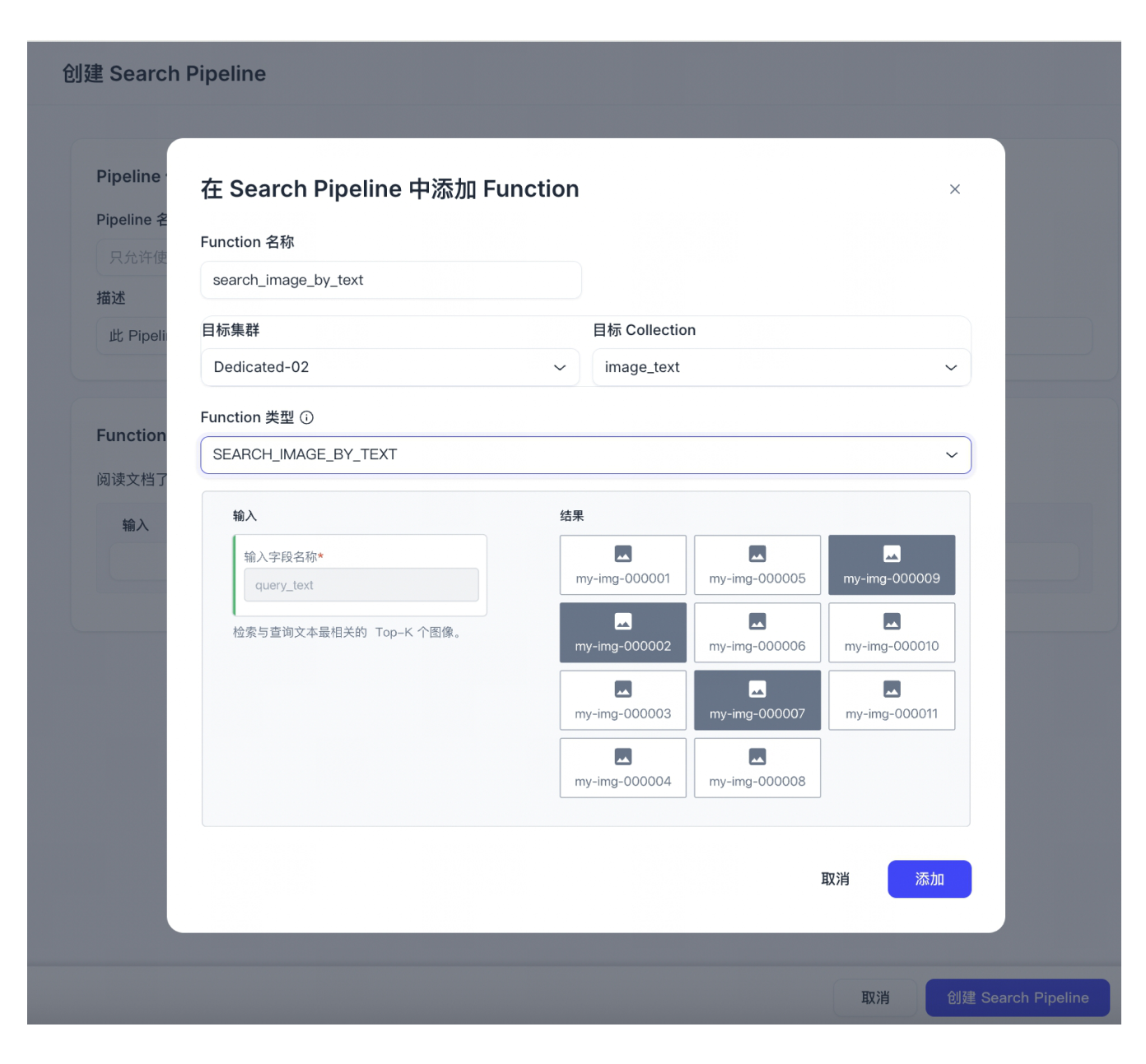
选择目标集群和目标 Collection。目标集群必须为部署在阿里云(杭州)的活跃集群。目标 Collection 必须为创建 Ingestion pipeline 时自动创建的 Collection,否则创建的 Search Pipeline 将不兼容。
📘说明仅当兼容的 Ingestion Pipeline 中使用了
zilliz/clip-vit-base-patch32embedding 模型时,才可选择 SEARCHIMAGEBYTEXT Function。 -
Function 类型选择 SEARCH_IMAGE_BY_TEXT。该 Function 可以将输入的查询文本转换为 Embedding 向量,并检索出与之最相关的 Top-K 个图像。选择 SEARCH_IMAGE_BY_TEXT Function 后,会自动应用
zilliz/clip-vit-base-patch32-multilingual-v1embedding 模型。 -
点击添加。
-
-
点击创建 Search Pipeline。
以下示例代码创建了 1 个名称为 my_image_search_pipeline 的 Search Pipeline,并添加了 1 个 SEARCH_IMAGE_BY_IMAGE Function。
curl --request POST \
--header "Content-Type: application/json" \
--header "Authorization: Bearer ${YOUR_API_KEY}" \
--url "https://controller.api.{cloud-region}.cloud.zilliz.com.cn/v1/pipelines" \
-d '{
"projectId": "proj-xxxx",
"name": "my_image_search_pipeline",
"description": "A pipeline that searches image by text.",
"type": "SEARCH",
"functions": [
{
"name": "search_image_by_text",
"action": "SEARCH_IMAGE_BY_TEXT",
"embedding": "zilliz/clip-vit-base-patch32-multilingual-v1",
"clusterId": "inxx-xxxxxxxxxxxxxxx",
"collectionName": "my_collection"
}
]
}'
以下为参数说明:
-
YOUR_API_KEY: 验证 API 请求的鉴权信息。了解如何查看 API 密钥。 -
cloud-region: 集群所在云服务地域的 ID。目前仅支持ali-cn-hangzhou。 -
projectId: 创建 Pipeline 所属的项目 ID。了解如何获取项目 ID。 -
name: 创建的 Pipeline 名称。Pipeline 名称应该在 3-64 个字符内,且只可包含数字、字母和下划线。 -
description(可选):创建的 Pipeline 描述。 -
type: 创建的 Pipeline 类型。目前,可创建的 Pipeline 类型包括INGESTION、SEARCH和DELETION。 -
functions: Pipeline 中添加的 Function。1 个 Search Pipeline 中仅可添加 1 个 Function。-
name: Function 名称。Function 名称应该在 3-64 个字符内,且只可包含数字、字母和下划线。 -
action: Function 类型。支持的类型包括:SEARCH_DOC_CHUNK、SEARCH_TEXT、SEARCH_IMAGE_BY_IMAGE、SEARCH_IMAGE_BY_TEXT。 -
inputField: 输入字段名称。您可以自由配置该字段的值。但是在运行 Pipeline 时,您需要使用现在定义的输入字段名称。 -
clusterId: 创建 Pipeline 所属的集群 ID。目前,仅支持部署在阿里云(杭州)的集群。了解如何获取集群 ID。 -
collectionName: 创建 Pipeline 所属的 Collection 名称。 -
embedding:向量搜索时使用的 Embedding 模型。如需进行以文本搜图,Embedding 模型必须为zilliz/clip-vit-base-patch32-multilingual-v1。该模型是 OpenAI 发布的 CLIP-ViT-B32 模型的多语言版本。与 CLIP-ViT-B32 的视觉模型配套使用时,可处理 50 多种语言的文本。
-
如果请求返回以下类似内容,则表示 Search Pipeline 创建成功:
{
"code": 200,
"data": {
"pipelineId": "pipe-xxxx",
"name": "my_image_search_pipeline",
"type": "SEARCH",
"createTimestamp": 1721187300000,
"description": "A pipeline that searches image by image.",
"status": "SERVING",
"totalUsage": {
"embedding": 0
},
"functions":
{
"action": "SEARCH_IMAGE_BY_TEXT",
"name": "search_image_by_text",
"inputFields": ["query_text"],
"clusterId": "in03-***************",
"collectionName": "my_collection",
"embedding": "zilliz/clip-vit-base-patch32-multilingual-v1"
}
}
}
总用量 totalUsage 非实时更新,数据统计可能会有几小时延迟。
运行图像 Search Pipeline
- Cloud Console
- cURL
-
点击 Search Pipeline 右侧的 "▶︎" 按钮。 或者您可以点击 Playground 选项卡。
-
输入查询文本。点击运行。
-
查看运行结果。
以下示例代码用于运行 Search pipeline my_image_search_pipeline。
curl --request POST \
--header "Content-Type: application/json" \
--header "Authorization: Bearer ${YOUR_API_KEY}" \
--url "https://controller.api.{cloud-region}.cloud.zilliz.com.cn/v1/pipelines/${YOUR_PIPELINE_ID}/run" \
-d '{
"data": {
"query_text": "Can you show me the image of a cat?",
},
"params":{
"limit": 1,
"offset": 0,
"outputFields": ["image_id", "image_title"],
"filter": "id >= 0"
}
}'
以下为参数说明:
-
YOUR_API_KEY: 验证 API 请求的鉴权信息。了解如何查看 API 密钥。 -
cloud-region: 集群的云服务地域。目前仅支持ali-cn-hangzhou。 -
query_text: 语义搜索的查询文本。 -
params: 搜索相关参数。-
limit: 返回的 Entity 数量。该参数值为 1-100 之间的整数。limit和offset参数值总和应小于 1024。 -
offset: 在搜索结果中跳过的 Entity 数量。最大值为 1024。limit和offset参数值总和应小于 1024。 -
outputFields: 在搜索结果中一同返回的输出字段。id、distance和chunk_text为默认输出字段。 -
filter: 搜索时的过滤条件。
-
请求返回以下类似内容:
{
"code": 200,
"data": {
"result": [
{
"id": "my-img-123456",
"distance": 0.40448662638664246,
"image_id": "my-img-123456",
"image_title": "A cute yellow cat"
}
],
"usage": {
"embedding": 1
}
}
}
删除图像数据
如需删除数据,请先创建并运行 Deletion Pipeline。
创建图像 Deletion Pipeline
- Cloud Console
- cURL
-
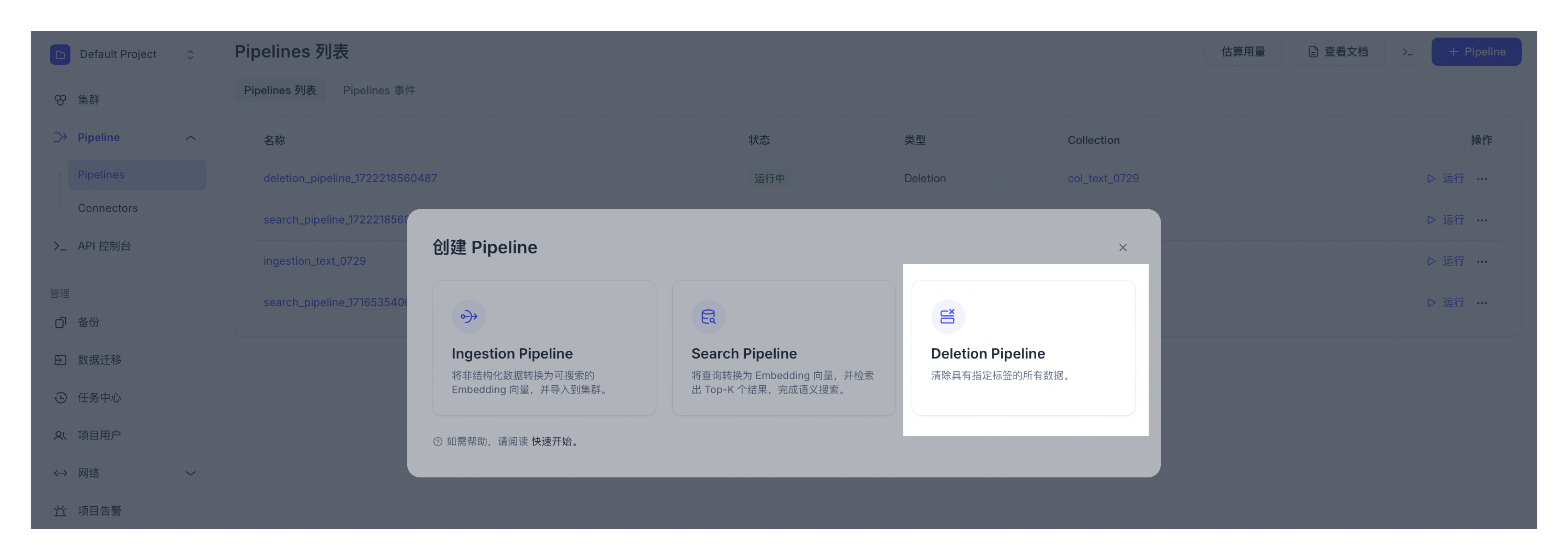
打开项目。
-
点击左侧导航栏中的 Pipelines。 选中概览标签页,并切换到 Pipelines。点击 + Pipeline。
-
选择需要创建的 Pipeline 类型。点击 Deletion Pipeline 一栏中的 + Pipeline 按钮。
-
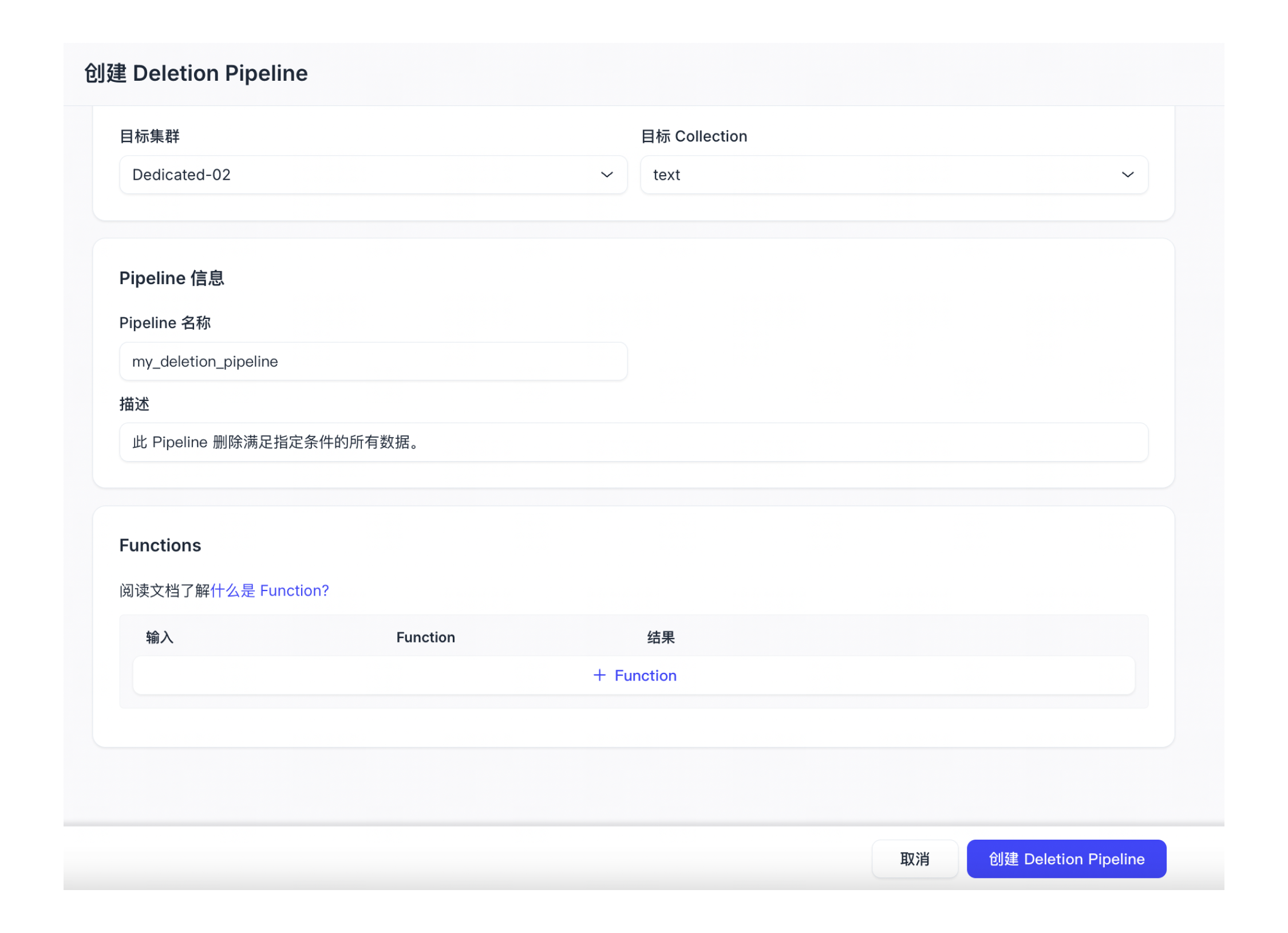
配置 Deletion Pipeline。
参数
说明
Pipeline 名称
新创建的 Deleltion Pipeline 名称。名称中只可包含小写字母、数字和下划线。
描述 (可选)
对新创建的 Deletion Pipeline 的描述。
-
点击 + Function 添加 Function。您只可添加 1 个 Function。
-
输入 Function名称。
-
从 PURGE_IMAGE_INDEX 或 PURGE_BY_EXPRESSION 中选择 1 个作为 Function 类型。 PURGE_IMAGE_INDEX Function 可以删除指定 image_id 的所有图像。PURGE_BY_EXPRESSION Function 可以删除符合指定过滤条件的所有文本 Entity。
-
点击添加。
-
-
点击创建 Deletion Pipeline。
以下示例代码创建了 1 个名称为 my_image_deletion_pipeline 的 Deletion Pipeline,并添加了 1 个 PURGE_IMAGE_INDEX Function。
curl --request POST \
--header "Content-Type: application/json" \
--header "Authorization: Bearer ${YOUR_API_KEY}" \
--url "https://controller.api.{cloud-region}.cloud.zilliz.com.cn/v1/pipelines" \
-d '{
"projectId": "proj-xxxx",
"name": "my_image_deletion_pipeline",
"description": "A pipeline that deletes image by id",
"type": "DELETION",
"functions": [
{
"name": "purge_image_by_id",
"action": "PURGE_IMAGE_INDEX"
}
],
"clusterId": "inxx-xxxxxxxxxxxxxxx",
"collectionName": "my_collection"
}'
以下为参数说明:
-
YOUR_API_KEY: 验证 API 请求的鉴权信息。了解如何查看 API 密钥。 -
cloud-region: 集群所在云服务地域的 ID。目前仅支持ali-cn-hangzhou。 -
projectId: 创建 Pipeline 所属的项目 ID。了解如何获取项目 ID。 -
name: 创建的 Pipeline 名称。Pipeline 名称应该在 3-64 个字符内,且只可包含数字、字母和下划线。 -
description(可选): 创建的 Pipeline 描述。 -
type: 创建的 Pipeline 类型。目前,可创建的 Pipeline 类型包括INGESTION、SEARCH和DELETION。 -
functions: Pipeline 中添加的 Function。1 个 Deletion Pipeline 中仅可添加 1 个 Function。-
name: Function 名称。Function 名称应该在 3-64 个字符内,且只可包含数字、字母和下划线。 -
action: Function 类型。可选择的 Function 类型包含:PURGE_DOC_INDEX、PURGE_TEXT_INDEX、PURGE_BY_EXPRESSION和PURGE_IMAGE_INDEX。
-
-
clusterId: 创建 Pipeline 所属的集群 ID。目前,仅支持部署在阿里云(杭州)的集群。了解如何获取集群 ID。 -
collectionName: 创建 Pipeline 所属的 Collection 名称。
如果请求返回以下类似内容,则表示 Deletion Pipeline 创建成功:
{
"code": 200,
"data": {
"id": 0,
"name": "my_image_deletion_pipeline",
"type": "DELETION",
"createTimestamp": 1721187655000,
"description": "A pipeline that deletes image by id",
"status": "SERVING",
"functions": [
{
"name": "purge_image_by_id",
"action": "PURGE_IMAGE_INDEX",
"inputFields": ["image_id"]
}
],
"clusterId": "in03-xxxx",
"collectionName":" my_collection"
}
}
运行图像 Deletion Pipeline
- Cloud Console
- cURL
-
点击 Deletion Pipeline 右侧的 "▶︎" 按钮。或者您可以点击 Playground 选项卡。
-
输入过滤表达式,点击运行。
-
查看运行结果。
以下示例代码用于运行 Deletion Pipeline my_image_deletion_pipeline。
curl --request POST \
--header "Content-Type: application/json" \
--header "Authorization: Bearer ${YOUR_API_KEY}" \
--url "https://controller.api.{cloud-region}.cloud.zilliz.com.cn/v1/pipelines/${YOUR_PIPELINE_ID}/run" \
-d '{
"data": {
"image_id": "my-img-123456"
}
}'
以下为参数说明:
-
YOUR_API_KEY: 验证 API 请求的鉴权信息。了解如何查看 API 密钥。 -
cloud-region: 集群的云服务地域。目前仅支持ali-cn-hangzhou。 -
image_id: 需要删除的图像 ID。
请求返回以下类似内容:
{
"code": 200,
"data": {
"num_deleted_entities": 1
}
}
以下操作可用于管理此前创建的 Pipeline。
查看 Pipeline
- Cloud Console
- cURL
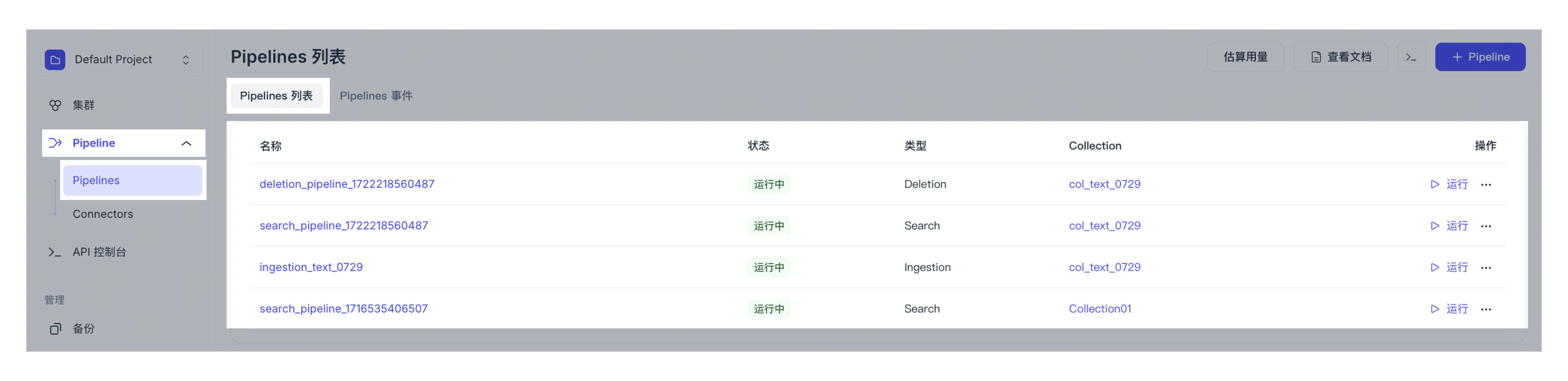
点击左侧导航栏中的 Pipelines。选中 Pipelines 选项卡。您可以查看所有已创建的 Pipelines 及其详情、用量等。
您还可以查看所有 Pipelines 相关事件。
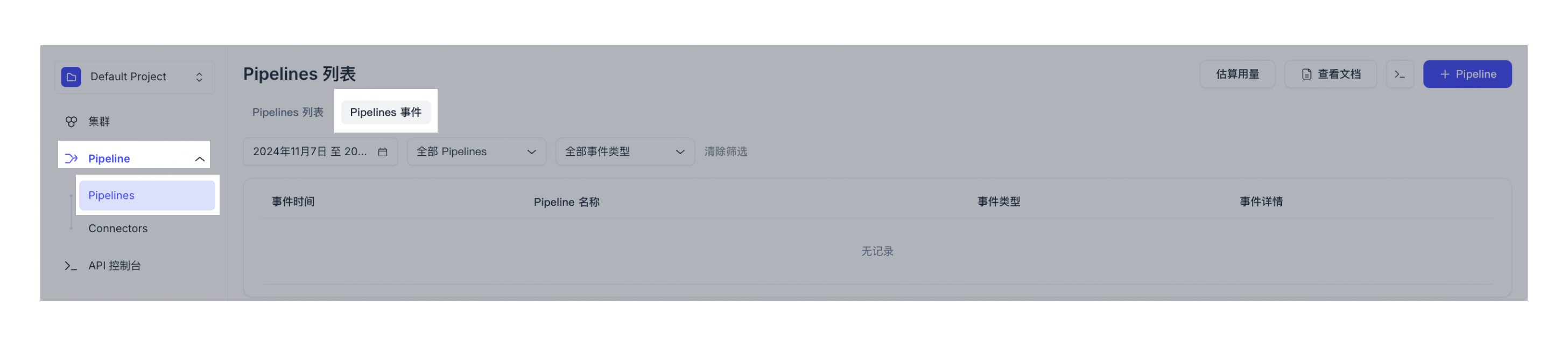
调用以下 API 查看所有 Pipelines 或查看某一特定 Pipeline 详情。
-
查看所有 Pipelines
根据以下示例并指定项目 ID
projectId。了解如何获取项目 ID。curl --request GET \
--header "Content-Type: application/json" \
--header "Authorization: Bearer ${YOUR_API_KEY}" \
--url "https://controller.api.{cloud-region}.cloud.zilliz.com.cn/v1/pipelines?projectId=proj-xxxx"如果请求返回以下类似内容,则表示操作成功:
{
"code": 200,
"data": [
{
"pipelineId": "pipe-xxxx",
"name": "my_text_ingestion_pipeline",
"type": "INGESTION",
"clusterId": "in03-***************",
"collectionName": "my_collection"
"description": "A pipeline that generates text embeddings and stores additional fields.",
"status": "SERVING",
"functions": [
{
"action": "INDEX_TEXT",
"name": "index_my_text",
"inputFields": ["text_list"],
"language": "ENGLISH",
"embedding": "zilliz/bge-base-en-v1.5"
},
{
"action": "PRESERVE",
"name": "keep_text_info",
"inputField": "source",
"outputField": "source",
"fieldType": "VarChar"
}
]
},
{
"pipelineId": "pipe-xxxx",
"name": "my_text_search_pipeline",
"type": "SEARCH",
"description": "A pipeline that receives text and search for semantically similar texts",
"status": "SERVING",
"functions":
{
"action": "SEARCH_TEXT",
"name": "search_text",
"inputFields": "query_text",
"clusterId": "in03-***************",
"collectionName": "my_collection",
"embedding": "zilliz/bge-base-en-v1.5",
"reranker": "zilliz/bge-reranker-base"
}
},
{
"pipelineId": "pipe-xxxx",
"name": "my_text_deletion_pipeline",
"type": "DELETION",
"description": "A pipeline that deletes entities by expression",
"status": "SERVING",
"functions":
{
"action": "PURGE_BY_EXPRESSION",
"name": "purge_data_by_expression",
"inputFields": ["expression"]
},
"clusterId": "in03-***************",
"collectionName": "my_collection"
}
]
} -
查看特定 Pipeline 详情
根据以下示例查看某一 Pipeline 详情。
curl --request GET \
--header "Content-Type: application/json" \
--header "Authorization: Bearer ${YOUR_API_KEY}" \
--url "https://controller.api.{cloud-region}.cloud.zilliz.com.cn/v1/pipelines/${YOUR_PIPELINE_ID}"如果请求返回以下类似内容,则表示操作成功:
{
"code": 200,
"data": {
"pipelineId": "pipe-xxxx",
"name": "my_text_ingestion_pipeline",
"type": "INGESTION",
"clusterId": "in03-***************",
"collectionName": "my_collection"
"description": "A pipeline that generates text embeddings and stores additional fields.",
"status": "SERVING",
"functions": [
{
"action": "INDEX_TEXT",
"name": "index_my_text",
"inputFields": ["text_list"],
"language": "ENGLISH",
"embedding": "zilliz/bge-base-en-v1.5"
},
{
"action": "PRESERVE",
"name": "keep_text_info",
"inputField": "source",
"outputField": "source",
"fieldType": "VarChar"
}
]
}
}
删除 Pipeline
您可以删除不再需要使用的 Pipelines。该操作仅删除 Pipeline,不会影响自动创建的 Collection。
该操作仅删除 Pipeline,不会影响自动创建的 Collection。
Pipeline 一旦删除后不可恢复,请谨慎操作。
删除 Ingestion pipeline 时不会影响其相关联的 Collection。您的数据十分安全。
- Cloud Console
- cURL
如需删除不再使用的 Pipeline,请点击操作栏中的**“...”按钮并选择删除**。
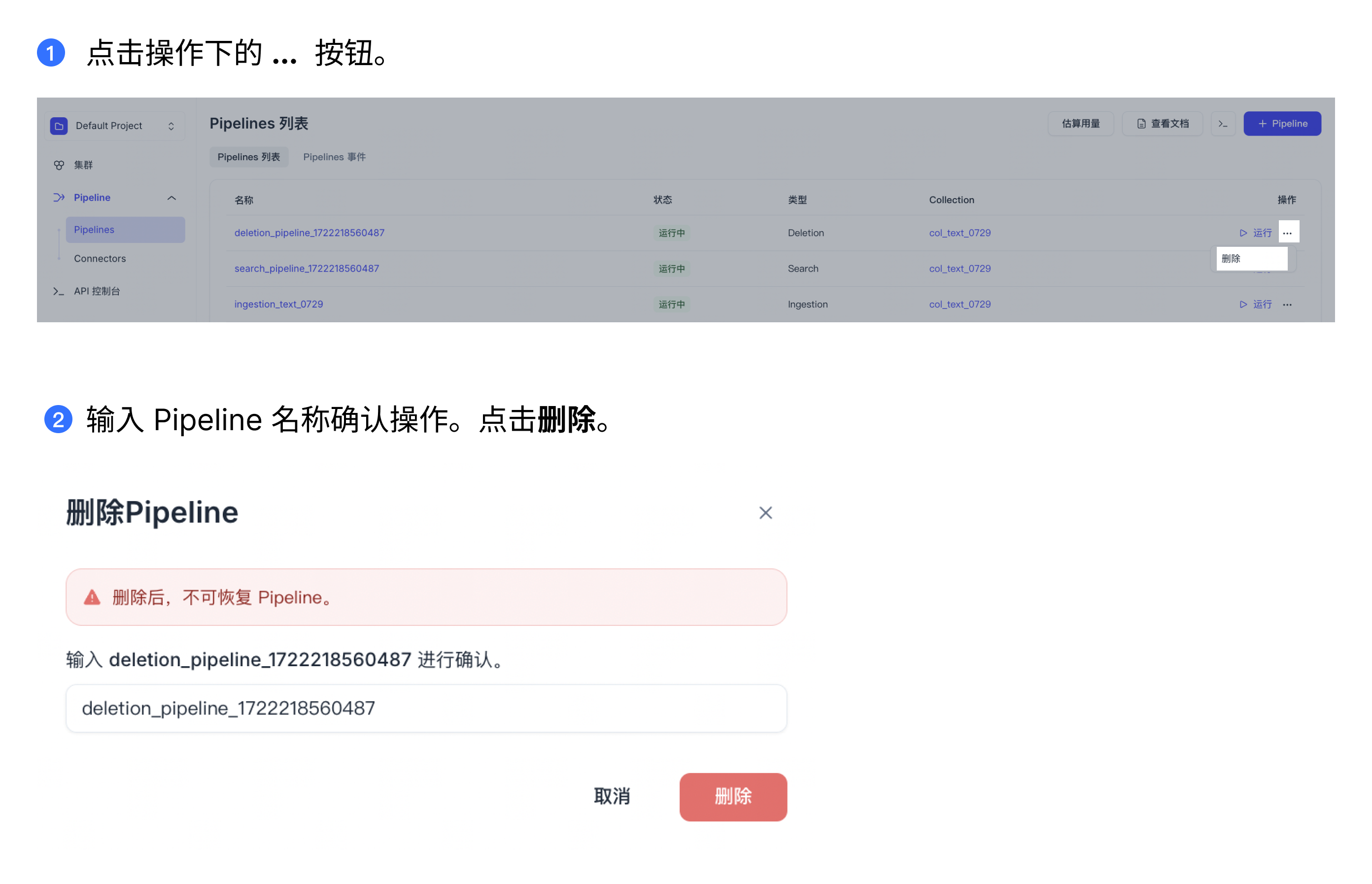
根据以下示例删除 Pipelines。
curl --request GET \
--header "Content-Type: application/json" \
--header "Authorization: Bearer ${YOUR_API_KEY}" \
--url "https://controller.api.{cloud-region}.cloud.zilliz.com.cn/v1/pipelines/${YOUR_PIPELINE_ID}"
如果请求返回以下类似内容,则表示操作成功:
{
"code": 200,
"data": {
"pipelineId": "pipe-6ca5dd1b4672659d3c3487",
"name": "my_doc_ingestion_pipeline",
"type": "INGESTION",
"description": "A pipeline that splits a text file into chunks and generates embeddings. It also stores the publish_year with each chunk.",
"status": "SERVING",
"functions": [
{
"action": "INDEX_DOC",
"name": "index_my_doc",
"inputField": "doc_url",
"language": "ENGLISH",
"chunkSize": 500,
"embedding": "zilliz/bge-base-en-v1.5"
},
{
"action": "PRESERVE",
"name": "keep_doc_info",
"inputField": "publish_year",
"outputField": "publish_year",
"fieldType": "Int16"
}
],
"clusterId": "in03-***************",
"newCollectionName": "my_collection"
}
}
管理 Pipeline
以下操作可用于管理此前创建的 Pipeline。
查看 Pipeline
- Cloud Console
- cURL
点击左侧导航栏中的 Pipelines。选中 Pipelines 选项卡。您可以查看所有已创建的 Pipelines。
点击特定 Pipeline 名称,还可以查看其详情,包括基本信息、总用量、Functions、关联的 Connectors 等。
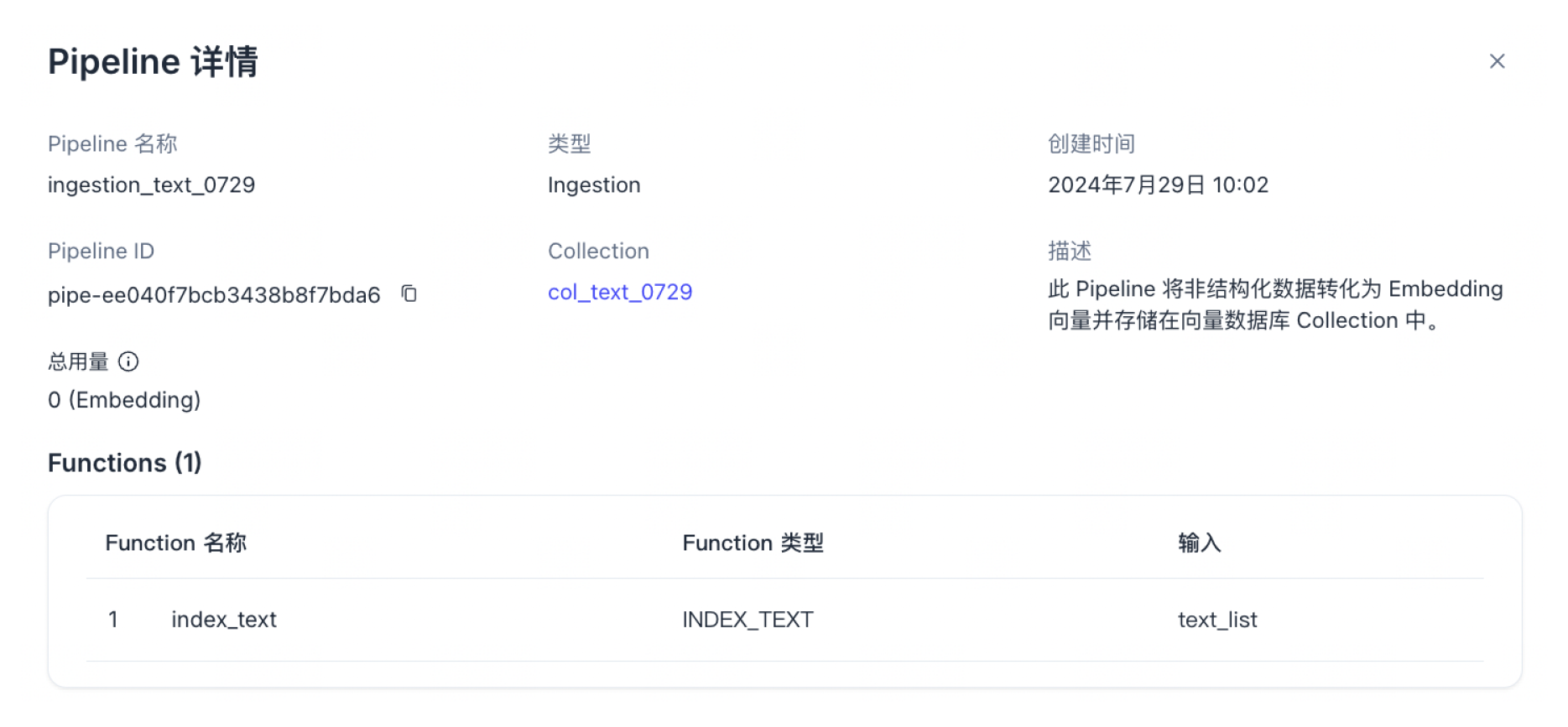
总用量非实时更新,数据统计可能会有几小时延迟。
您还可以查看所有 Pipelines 相关事件。
调用以下 API 查看所有 Pipelines 或查看某一特定 Pipeline 详情。
-
查看所有 Pipelines
根据以下示例并指定项目 ID
projectId。了解如何获取项目 ID。curl --request GET \
--header "Content-Type: application/json" \
--header "Authorization: Bearer ${YOUR_API_KEY}" \
--url "https://controller.api.{cloud-region}.cloud.zilliz.com.cn/v1/pipelines?projectId=proj-xxxx"如果请求返回以下类似内容,则表示操作成功:
{
"code": 200,
"data": [
{
"pipelineId": "pipe-xxxx",
"name": "my_text_ingestion_pipeline",
"type": "INGESTION",
"createTimestamp": 1721187655000,
"clusterId": "in03-***************",
"collectionName": "my_collection"
"description": "A pipeline that generates text embeddings and stores additional fields.",
"status": "SERVING",
"totalUsage": {
"embedding": 0
},
"functions": [
{
"action": "INDEX_TEXT",
"name": "index_my_text",
"inputFields": ["text_list"],
"language": "ENGLISH",
"embedding": "zilliz/bge-base-en-v1.5"
},
{
"action": "PRESERVE",
"name": "keep_text_info",
"inputField": "source",
"outputField": "source",
"fieldType": "VarChar"
}
]
},
{
"pipelineId": "pipe-xxxx",
"name": "my_text_search_pipeline",
"type": "SEARCH",
"createTimestamp": 1721187655000,
"description": "A pipeline that receives text and search for semantically similar texts",
"status": "SERVING",
"totalUsage": {
"embedding": 0,
"rerank": 0
},
"functions":
{
"action": "SEARCH_TEXT",
"name": "search_text",
"inputFields": "query_text",
"clusterId": "in03-***************",
"collectionName": "my_collection",
"embedding": "zilliz/bge-base-en-v1.5",
"reranker": "zilliz/bge-reranker-base"
}
},
{
"pipelineId": "pipe-xxxx",
"name": "my_text_deletion_pipeline",
"type": "DELETION",
"createTimestamp": 1721187655000,
"description": "A pipeline that deletes entities by expression",
"status": "SERVING",
"functions":
{
"action": "PURGE_BY_EXPRESSION",
"name": "purge_data_by_expression",
"inputFields": ["expression"]
},
"clusterId": "in03-***************",
"collectionName": "my_collection"
}
]
}📘说明总用量
totalUsage非实时更新,数据统计可能会有几小时延迟。 -
查看特定 Pipeline 详情
根据以下示例查看某一 Pipeline 详情。
curl --request GET \
--header "Content-Type: application/json" \
--header "Authorization: Bearer ${YOUR_API_KEY}" \
--url "https://controller.api.{cloud-region}.cloud.zilliz.com.cn/v1/pipelines/${YOUR_PIPELINE_ID}"如果请求返回以下类似内容,则表示操作成功:
{
"code": 200,
"data": {
"pipelineId": "pipe-xxx",
"name": "my_text_ingestion_pipeline",
"type": "INGESTION",
"createTimestamp": 1721187300000,
"description": "A pipeline that generates text embeddings and stores additional fields.",
"status": "SERVING",
"totalUsage": {
"embedding": 0
},
"functions": [
{
"name": "index_my_text",
"action": "INDEX_TEXT",
"inputFields": ["text_list"],
"language": "ENGLISH",
"embedding": "zilliz/bge-base-en-v1.5"
},
{
"name": "keep_text_info",
"action": "PRESERVE",
"inputField": "source",
"outputField": "source",
"fieldType": "VarChar"
}
],
"clusterId": "inxx-xxxx",
"collectionName": "my_collection"
}
}📘说明总用量
totalUsage非实时更新,数据统计可能会有几小时延迟。
删除 Pipeline
您可以删除不再需要使用的 Pipelines。该操作仅删除 Pipeline,不会影响自动创建的 Collection。
该操作仅删除 Pipeline,不会影响自动创建的 Collection。
Pipeline 一旦删除后不可恢复,请谨慎操作。
删除 Ingestion pipeline 时不会影响其相关联的 Collection。您的数据十分安全。
- Cloud Console
- cURL
如需删除不再使用的 Pipeline,请点击操作栏中的**“...”按钮并选择删除**。
根据以下示例删除 Pipelines。
curl --request GET \
--header "Content-Type: application/json" \
--header "Authorization: Bearer ${YOUR_API_KEY}" \
--url "https://controller.api.{cloud-region}.cloud.zilliz.com.cn/v1/pipelines/${YOUR_PIPELINE_ID}"
如果请求返回以下类似内容,则表示操作成功:
{
"code": 200,
"data": {
"pipelineId": "pipe-xxx",
"name": "my_text_ingestion_pipeline",
"type": "INGESTION",
"createTimestamp": 1721187300000,
"description": "A pipeline that generates text embeddings and stores additional fields.",
"status": "SERVING",
"totalUsage": {
"embedding": 0
},
"functions": [
{
"name": "index_my_text",
"action": "INDEX_TEXT",
"inputFields": ["text_list"],
"language": "ENGLISH",
"embedding": "zilliz/bge-base-en-v1.5"
},
{
"name": "keep_text_info",
"action": "PRESERVE",
"inputField": "source",
"outputField": "source",
"fieldType": "VarChar"
}
],
"clusterId": "inxx-xxxx",
"collectionName": "my_collection"
}
}
总用量 totalUsage 非实时更新,数据统计可能会有几小时延迟。