RRF Ranker
RRF (互反排名融合) Ranker 是 Zilliz Cloud 混合搜索的一种重排序策略,它根据多个向量搜索路径的排名位置而非原始相似度得分来平衡结果。就像体育锦标赛会考虑选手的排名而非个人统计数据一样,RRF Ranker 根据每个项目在不同搜索路径中的排名高低来合并搜索结果,从而生成一个公平且平衡的最终排名。
何时使用 RRF Ranker
RRF Ranker 专为混合搜索场景而设计,在这些场景中,你可以平衡来自多个向量搜索路径的结果,而无需分配明确的重要性权重。它在以下方面特别有效:
用例 | 示例 | 为什么RRF Ranker 效果良好 |
|---|---|---|
同等重要性的多模态搜索 | 图像文本搜索,两种模态同等重要 | 平衡结果,无需进行任意权重分配 |
集成向量搜索 | 结合不同嵌入模型的结果 | 民主地合并排名,不偏袒任何特定模型的评分分布 |
跨语言搜索 | 跨多种语言查找文档 | 公平地对结果进行排名,而不考虑特定语言的嵌入特征 |
专家建议 | 整合多个专家系统的建议 | 当不同系统使用不可比的评分方法时,创建共识排名 |
如果您的混合搜索应用程序需要在不分配明确权重的情况下民主地平衡多个搜索路径,RRF Ranker 是您的理想选择。
RRF Ranker 工作机制
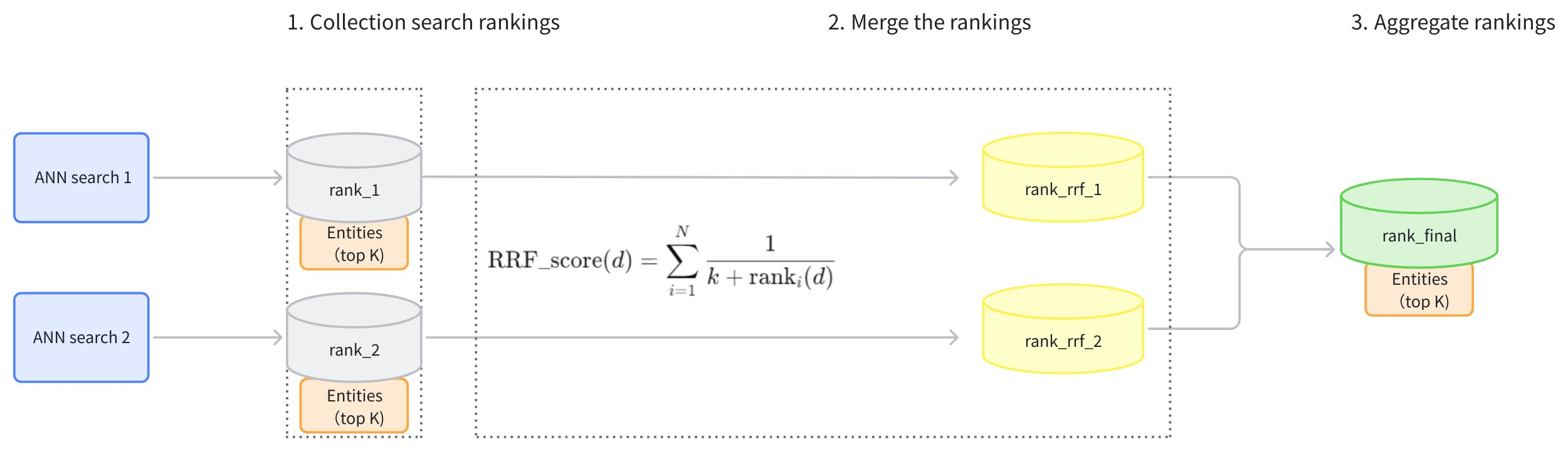
RRF Ranker 策略的主要工作流程如下:
-
收集搜索排名:收集向量搜索各路径结果的排名(rank_1、rank_2)。
-
合并排名:根据公式转换每条路径的排名(rank_rrf_1、rank_rrf_2)。
计算公式涉及 N,表示检索次数。ranki(d)是由第 i 个检索器生成的文档 d 的排名位置。k 是一个平滑参数,通常设置为 60。
-
聚合排名:根据组合排名对搜索结果进行重新排序,以生成最终结果。
RRF Ranker 示例
此示例展示了在稀疏-密集向量上进行的混合搜索(topK=5),并说明了 RRF Ranker 策略如何对两次近似最近邻(ANN)搜索的结果进行重排序。
-
文本稀疏向量的 ANN 搜索结果(topK=5):
ID
排名(稀疏)
101
1
203
2
150
3
198
4
175
5
-
文本密集向量的 ANN 搜索结果(topK=5):
ID
排名(密集)
198
1
101
2
110
3
175
4
250
5
-
使用RRF重新排列两组搜索结果的排名。假设平滑参数
k设置为60。ID
得分(稀疏)
得分(密集)
最终得分
101
1
2
1/(60+1)+1/(60+2) = 0.03252247
198
4
1
1/(60+4)+1/(60+1) = 0.03201844
175
5
4
1/(60+5)+1/(60+4) = 0.03100962
203
2
N/A
1/(60+2) = 0.01612903
150
3
N/A
1/(60+3) = 0.01587302
110
N/A
3
1/(60+3) = 0.01587302
250
N/A
5
1/(60+5) = 0.01538462
-
重排序后的最终结果(topK=5):
排名
ID
最终得分
1
101
0.03252247
2
198
0.03201844
3
175
0.03100962
4
203
0.01612903
5
150
0.01587302
5
110
0.01587302
使用 RRF Ranker
使用 RRF Ranker 策略时,需要配置参数 k。它是一个平滑参数,可以有效改变全文搜索与向量搜索的相对权重。该参数的默认值为 60,可在 (0, 16384) 范围内调整。取值应为浮点数,建议值在 [10, 100] 之间。虽然 k=60 是常见选择,但最优 k 值可能因具体应用和数据集而异。我们建议根据具体用例测试和调整此参数,以实现最佳性能。
创建一个 RRF Ranker
在您的集合设置了多个向量字段后,使用适当的平滑参数创建一个RRF排序器:
- Python
- Java
- NodeJS
- Go
- cURL
from pymilvus import Function, FunctionType
rerank = Function(
name="rrf",
input_field_names=[], # Must be an empty list
function_type=FunctionType.RERANK,
params={
"reranker": "rrf",
"k": 100 # Optional
}
)
import io.milvus.common.clientenum.FunctionType;
import io.milvus.v2.service.collection.request.CreateCollectionReq;
CreateCollectionReq.Function rerank = CreateCollectionReq.Function.builder()
.name("rrf")
.functionType(FunctionType.RERANK)
.param("reranker", "rrf")
.param("k", "100")
.build();
import { FunctionType } from "@zilliz/milvus2-sdk-node";
const rerank = {
name: "rrf",
input_field_names: [],
function_type: FunctionType.RERANK,
params: {
reranker: "rrf",
k: 100,
},
};
// Go
# Restful
参数 | 必填? | 描述 | 值/示例 |
|---|---|---|---|
| 是 | 此函数的唯一标识符 |
|
| 是 | 要应用该函数的向量字段列表(对于RRF Ranker 而言必须为空) | [] |
| 是 | 要调用的函数类型;使用 |
|
| 是 | 指定要使用的重排序方法。 必须设置为 |
|
| 否 | 平滑参数,用于控制文档排名的影响;较高的 详情请参考 RRF排序器的机制。 |
|
在混合搜索中使用
RRF Ranker 专为结合多个向量字段的混合搜索操作而设计。以下是在混合搜索中使用它的方法:
- Python
- Java
- NodeJS
- Go
- cURL
from pymilvus import MilvusClient, AnnSearchRequest
# Connect to Milvus server
milvus_client = MilvusClient(uri="https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530")
# Assume you have a collection setup
# Define text vector search request
text_search = AnnSearchRequest(
data=["modern dining table"],
anns_field="text_vector",
param={},
limit=10
)
# Define image vector search request
image_search = AnnSearchRequest(
data=[image_embedding], # Image embedding vector
anns_field="image_vector",
param={},
limit=10
)
# Apply RRF Ranker to product hybrid search
# The smoothing parameter k controls the balance
hybrid_results = milvus_client.hybrid_search(
collection_name,
[text_search, image_search], # Multiple search requests
# highlight-next-line
ranker=rerank, # Apply the RRF ranker
limit=10,
output_fields=["product_name", "price", "category"]
)
import io.milvus.v2.client.ConnectConfig;
import io.milvus.v2.client.MilvusClientV2;
import io.milvus.v2.service.vector.request.AnnSearchReq;
import io.milvus.v2.service.vector.request.HybridSearchReq;
import io.milvus.v2.service.vector.response.SearchResp;
import io.milvus.v2.service.vector.request.data.EmbeddedText;
import io.milvus.v2.service.vector.request.data.FloatVec;
MilvusClientV2 client = new MilvusClientV2(ConnectConfig.builder()
.uri("https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530")
.build());
List<AnnSearchReq> searchRequests = new ArrayList<>();
searchRequests.add(AnnSearchReq.builder()
.vectorFieldName("text_vector")
.vectors(Collections.singletonList(new EmbeddedText("\"modern dining table\"")))
.limit(10)
.build());
searchRequests.add(AnnSearchReq.builder()
.vectorFieldName("image_vector")
.vectors(Collections.singletonList(new FloatVec(imageEmbedding)))
.limit(10)
.build());
HybridSearchReq hybridSearchReq = HybridSearchReq.builder()
.collectionName(COLLECTION_NAME)
.searchRequests(searchRequests)
.ranker(rerank)
.limit(10)
.outputFields(Arrays.asList("product_name", "price", "category"))
.build();
SearchResp searchResp = client.hybridSearch(hybridSearchReq);
import { MilvusClient, FunctionType } from "@zilliz/milvus2-sdk-node";
const milvusClient = new MilvusClient({ address: "https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530" });
const text_search = {
data: ["modern dining table"],
anns_field: "text_vector",
param: {},
limit: 10,
};
const image_search = {
data: [image_embedding],
anns_field: "image_vector",
param: {},
limit: 10,
};
const search = await milvusClient.search({
collection_name: collection_name,
data: [text_search, image_search],
output_fields: ["product_name", "price", "category"],
limit: 10,
rerank: rerank,
});
// go
# restful
有关混合搜索的更多信息,请参阅多向量混合搜索。