Weighted Ranker
Weighted Ranker 通过为每个搜索路径分配不同的重要性权重,智能地组合来自多个搜索路径的结果并进行优先级排序。就像一位技艺娴熟的厨师平衡多种食材以烹制出完美菜肴一样,Weighted Ranker 平衡不同的搜索结果,以提供最相关的结果组合。这种方法适用于当多个向量字段或模态中进行搜索的情形。因为在这些情况下,某些字段对最终排名的贡献可能会比其他字段更大。
何时使用 Weighted Ranker
Weighted Ranker 专为混合搜索场景而设计,在这些场景中,您可以将多个向量搜索路径的结果进行组合。它在以下方面特别有效:
用例 | 示例 | Weighted Ranker 为何效果良好 |
|---|---|---|
电子商务搜索 | 结合图像相似度和文本描述的产品搜索 | 允许零售商在时尚单品方面优先考虑视觉相似度,同时在技术产品方面强调文字描述 |
媒体内容搜索 | 使用视觉特征和音频转录本的视频检索 | 根据查询意图平衡视觉内容与口语对话的重要性 |
文档检索 | 企业文档搜索,不同部分采用多种嵌入方式 | 在仍考虑全文嵌入的同时,对标题和摘要嵌入赋予更高权重 |
如果您的混合搜索应用程序需要在控制多个搜索路径相对重要性的同时将它们组合起来,Weighted Ranker 是您的理想选择。
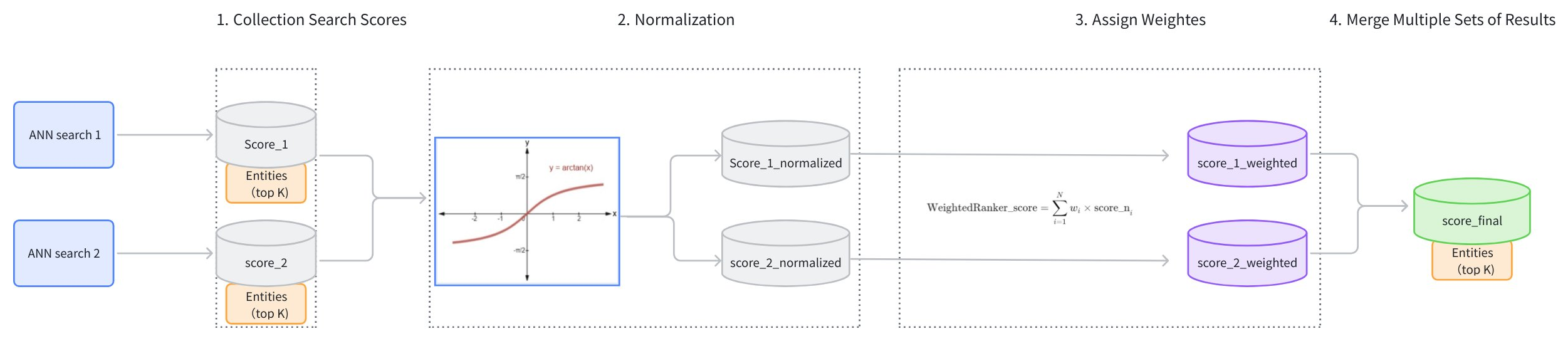
Weighted Ranker 工作机制
WeightedRanker 策略的主要工作流程如下:
-
收集搜索得分:收集向量搜索各路径的结果和得分(score_1, score_2)。
-
分数归一化:每次搜索可能使用不同的相似度度量,导致分数分布各不相同。例如,使用内积(IP)作为相似度类型可能会得到范围在 [−∞,+∞] 的分数,而使用欧几里得距离(L2)则会得到范围在 [0,+∞] 的分数。由于不同搜索的分数范围不同,无法直接比较,因此有必要对每次搜索路径的分数进行归一化处理。通常,
arctan函数被用于将分数转换到 [0, 1] 范围内(score_1_normalized、score_2_normalized)。分数越接近 1 表示相似度越高。 -
分配权重:根据分配给不同向量字段的重要性,将权重(wi)分配给归一化分数(score_1_normalized、score_2_normalized)。每条路径的权重应在 [0,1] 范围内。得到的加权分数为 score_1_weighted 和 score_2_weighted。
-
合并得分:加权得分(score_1_weighted、score_2_weighted)按从高到低的顺序排列,以生成最终得分集(score_final)。
Weighted Ranker 示例
此示例展示了一个涉及图像和文本的多模态混合搜索(topK=5),并说明了 Weighted Ranker 策略如何对两次近似最近邻(ANN)搜索的结果进行重新排序。
-
图像上的 ANN 搜索结果(topK=5):
ID
得分(图像)
101
0.92
203
0.88
150
0.85
198
0.83
175
0.8
-
文本上的 ANN 搜索结果(topK=5):
ID
得分(文本)
198
0.91
101
0.87
110
0.85
175
0.82
250
0.78
-
使用 Weighted Ranker 为图像和文本搜索结果分配权重。假设图像 ANN 搜索的权重为 0.6,文本搜索的权重为 0.4。
ID
得分(图像)
得分(文本)
加权分数
101
0.92
0.87
0.6×0.92+0.4×0.87=0.90
203
0.88
N/A
0.6×0.88+0.4×0=0.528
150
0.85
N/A
0.6×0.85+0.4×0=0.51
198
0.83
0.91
0.6×0.83+0.4×0.91=0.86
175
0.80
0.82
0.6×0.80+0.4×0.82=0.81
110
不在图像中
0.85
0.6×0+0.4×0.85=0.34
250
不在图像中
0.78
0.6×0+0.4×0.78=0.312
-
重排序后的最终结果(topK=5):
排名
ID
最终得分
1
101
0.90
2
198
0.86
3
175
0.81
4
203
0.528
5
150
0.51
使用 Weighted Ranker
使用 WeightedRanker 策略时,需要输入权重值。输入的权重值数量应与混合搜索中基本 ANN 搜索请求的数量相对应。输入的权重值应在 [0,1] 范围内,值越接近 1 表示重要性越高。
创建 Weighted Ranker
例如,假设混合搜索中有两个基本的 ANN 搜索请求:文本搜索和图像搜索。如果认为文本搜索更重要,则应赋予其更大的权重。
- Python
- Java
- NodeJS
- Go
- cURL
from pymilvus import Function, FunctionType
rerank = Function(
name="weight",
input_field_names=[], # Must be an empty list
function_type=FunctionType.RERANK,
params={
"reranker": "weighted",
"weights": [0.1, 0.9],
"norm_score": True # Optional
}
)
import io.milvus.common.clientenum.FunctionType;
import io.milvus.v2.service.collection.request.CreateCollectionReq;
CreateCollectionReq.Function rerank = CreateCollectionReq.Function.builder()
.name("weight")
.functionType(FunctionType.RERANK)
.param("reranker", "weighted")
.param("weights", "[0.1, 0.9]")
.param("norm_score", "true")
.build();
import { FunctionType } from '@zilliz/milvus2-sdk-node';
const rerank = {
name: "weight",
input_field_names: [],
function_type: FunctionType.RERANK,
params: {
reranker: "weighted",
weights: [0.1, 0.9],
norm_score: true
}
};
// Go
# Restful
参数 | 是否必填? | 描述 | 值/示例 |
|---|---|---|---|
| 是 | 此 Function 的唯一标识符 |
|
| 是 | 要应用该 Function 的向量字段列表(对于 Weighted Ranker 必须为空) | [] |
| 是 | 要调用的 Function 类型;使用 |
|
| 是 | 指定要使用的重排序方法。 必须设置为 |
|
| 是 | 对应每个搜索路径的权重数组;值∈ [0,1]。 详情请参考 Weighted Ranker 机制。 |
|
| 否 | 是否在加权前对原始分数进行归一化处理(使用反正切函数)。 详情请参考Weighted Ranker 机制。 |
|
在混合搜索中使用
Weighted Ranker 专为结合多个向量字段的混合搜索操作而设计。在执行混合搜索时,必须为每个搜索路径指定权重:
- Python
- Java
- NodeJS
- Go
- cURL
from pymilvus import MilvusClient, AnnSearchRequest
# Connect to Milvus server
milvus_client = MilvusClient(
uri="https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530",
token="YOUR_CLUSTER_TOKEN"
)
# Assume you have a collection setup
# Define text vector search request
text_search = AnnSearchRequest(
data=["modern dining table"],
anns_field="text_vector",
param={},
limit=10
)
# Define image vector search request
image_search = AnnSearchRequest(
data=[image_embedding], # Image embedding vector
anns_field="image_vector",
param={},
limit=10
)
# Apply Weighted Ranker to product hybrid search
# Text search has 0.8 weight, image search has 0.3 weight
hybrid_results = milvus_client.hybrid_search(
collection_name,
[text_search, image_search], # Multiple search requests
# highlight-next-line
ranker=rerank, # Apply the weighted ranker
limit=10,
output_fields=["product_name", "price", "category"]
)
import io.milvus.v2.client.ConnectConfig;
import io.milvus.v2.client.MilvusClientV2;
import io.milvus.v2.service.vector.request.AnnSearchReq;
import io.milvus.v2.service.vector.request.HybridSearchReq;
import io.milvus.v2.service.vector.response.SearchResp;
import io.milvus.v2.service.vector.request.data.EmbeddedText;
import io.milvus.v2.service.vector.request.data.FloatVec;
MilvusClientV2 client = new MilvusClientV2(ConnectConfig.builder()
.uri("https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530")
.token("YOUR_CLUSTER_TOKEN")
.build());
List<AnnSearchReq> searchRequests = new ArrayList<>();
searchRequests.add(AnnSearchReq.builder()
.vectorFieldName("text_vector")
.vectors(Collections.singletonList(new EmbeddedText("\"modern dining table\"")))
.limit(10)
.build());
searchRequests.add(AnnSearchReq.builder()
.vectorFieldName("image_vector")
.vectors(Collections.singletonList(new FloatVec(imageEmbedding)))
.limit(10)
.build());
HybridSearchReq hybridSearchReq = HybridSearchReq.builder()
.collectionName(COLLECTION_NAME)
.searchRequests(searchRequests)
.ranker(ranker)
.limit(10)
.outputFields(Arrays.asList("product_name", "price", "category"))
.build();
SearchResp searchResp = client.hybridSearch(hybridSearchReq);
import { MilvusClient, FunctionType } from "@zilliz/milvus2-sdk-node";
const milvusClient = new MilvusClient({
address: "https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530",
token: "YOUR_CLUSTER_TOKEN"
});
const text_search = {
data: ["modern dining table"],
anns_field: "text_vector",
param: {},
limit: 10,
};
const image_search = {
data: [image_embedding],
anns_field: "image_vector",
param: {},
limit: 10,
};
const search = await milvusClient.search({
collection_name: collection_name,
limit: 10,
data: [text_search, image_search],
rerank: rerank,
output_fields = ["product_name", "price", "category"],
});
// go
# restful
有关混合搜索的更多信息,请参阅多向量混合搜索。