RTREE
RTREE 索引是一种基于树形结构的数据索引方式,用于加速 Zilliz Cloud 中 GEOMETRY(几何类型)字段 的查询。
如果你的 Collection 存储了点(Point)、线(Line)或多边形(Polygon)等以 Well-known text (WKT) 格式表示的几何对象,并希望提升空间过滤性能,那么 RTREE 是理想的选择。
工作原理
Zilliz Cloud 使用 RTREE 索引以高效地组织和过滤几何数据,主要分为两个阶段:
阶段 1:构建索引
-
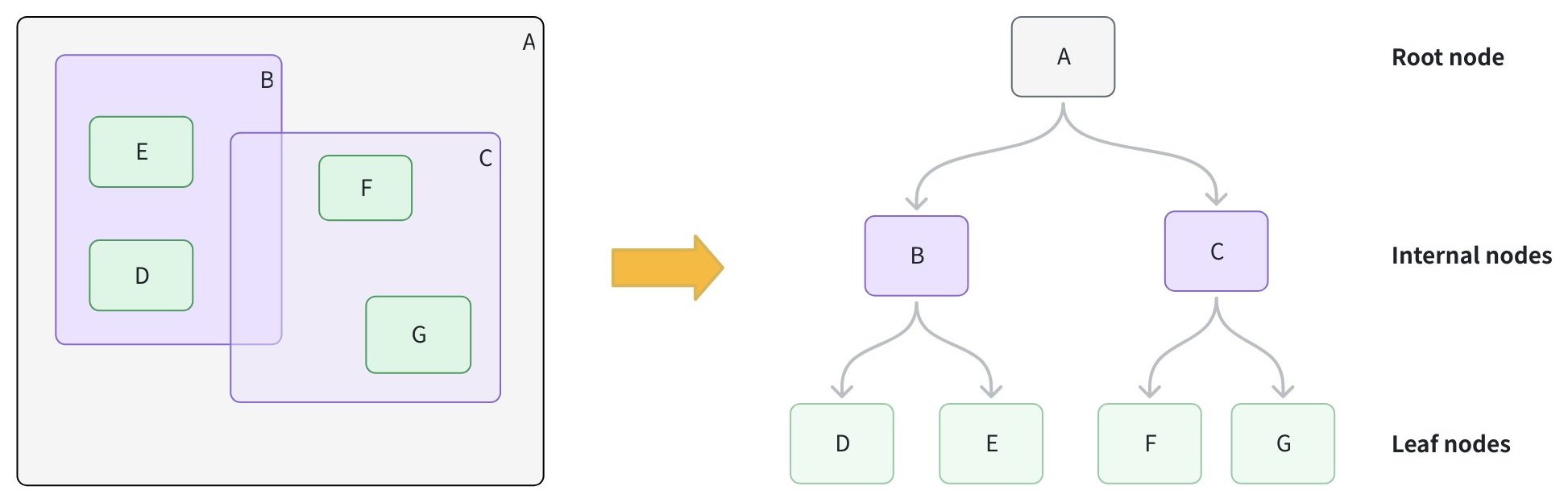
创建叶子节点:为每个几何对象计算其最小外包矩形(MBR,Minimum Bounding Rectangle),即能完全包围该对象的最小矩形,并将其作为叶子节点存储。
-
分组形成更大的矩形框:将相邻的叶子节点聚类,并为每一组计算新的 MBR,形成内部节点。例如,分组 B 包含 D 和 E;分组 C 包含 F 和 G。
-
添加根节点:为所有内部节点添加一个根节点,其 MBR 覆盖所有下属分组,从而形成一个高度平衡的树结构。
阶段 2:加速查询
-
生成查询 MBR:为查询中使用的几何对象计算其 MBR。
-
剪枝操作:从根节点开始,将查询 MBR 与每个内部节点的 MBR 进行比较,跳过所有与查询 MBR 不相交的分支。
-
收集候选节点:进入相交的分支,收集可能匹配的叶子节点。
-
精确匹配:对候选节点执行精确的空间谓词判断,以确定真正的匹配对象。
创建 RTREE 索引
你可以在 Collection 的 GEOMETRY 字段上创建 RTREE 索引。
from pymilvus import MilvusClient
client = MilvusClient(uri="https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530") # Replace with your server address
# Assume you have defined a GEOMETRY field named "geo" in your collection schema
# Prepare index parameters
index_params = client.prepare_index_params()
# Add RTREE index on the "geo" field
# highlight-start
index_params.add_index(
field_name="geo",
index_type="RTREE", # Spatial index for GEOMETRY
index_name="rtree_geo", # Optional, name your index
params={} # No extra params needed
)
# highlight-end
# Create the index on the collection
client.create_index(
collection_name="geo_demo",
index_params=index_params
)
使用 RTREE 查询
在过滤表达式中使用几何运算符(geometry operator)进行过滤。当目标 GEOMETRY 字段存在 RTREE 索引时,Zilliz Cloud 会自动利用索引进行候选剪枝;
若不存在索引,则会退化为全量扫描。
完整的几何运算符列表参见 Geometry 操作符。
示例 1:数据过滤
查找位于指定多边形范围内的所有几何对象:
filter_expr = "ST_CONTAINS(geo, 'POLYGON ((0 0, 10 0, 10 10, 0 10, 0 0))')"
res = client.query(
collection_name="geo_demo",
filter=filter_expr,
output_fields=["id", "geo"],
limit=10
)
print(res) # Expected: a list of rows where geo is entirely inside the polygon
示例 2:向量搜索 + 空间过滤
查找与指定线段相交的最近向量:
# Assume you've also created an index on "vec" and loaded the collection.
query_vec = [[0.1, 0.2, 0.3, 0.4, 0.5]]
filter_expr = "ST_INTERSECTS(geo, 'LINESTRING (1 1, 2 2)')"
hits = client.search(
collection_name="geo_demo",
data=query_vec,
limit=5,
filter=filter_expr,
output_fields=["id", "geo"]
)
print(hits) # Expected: top-k by vector similarity among rows whose geo intersects the line
更多关于 GEOMETRY 字段的使用方法,请参见 Geometry 类型。
删除索引
您也可以使用 drop_index() 从 Collection 中删除指定字段上的索引。
如果您的集群与 Milvus v2.6.x 兼容,您可以删除标量字段上的索引,无须对 Collection 执行 Release 操作。
client.drop_index(
collection_name="geo_demo", # Name of the collection
index_name="rtree_geo" # Name of the index to drop
)