Schema 设计指南
信息检索系统 (IRS),也被称为搜索引擎,是各类 AI 应用的核心依赖,被广泛应用于检索增强生成(RAG)、图像搜索、产品推荐等场景中。开发一套 IRS 的第一步就是数据模型设计,涉及业务需求分析、确定信息组织方式以及为数据建立索引使其能够按语义进行查询。
Zilliz Cloud 支持通过 Collection 的 Schema 定义数据模型。Collection 是一个用于组织存放文本和图像等非结构化数据及其向量表示的容器,而各种精度的稠密和稀疏向量则常常和结构化的元数据一起用来进行语义查询。无论您的非结构化数据是文本、图像或其它类型的数据,本文都将为您理解并应用与 Schema 相关的各种核心概念来完成数据模型的设计。
数据模型
搜索系统的数据模型设计涉及分析业务需求,并将信息抽象为以 Schema 表达的数据模型。定义良好的 Schema 对于使数据模型与业务目标保持一致、确保数据展示一致性和服务质量至关重要。此外,选择合适的数据类型和索引对于经济地实现业务目标也很重要。
分析业务需求
有效满足业务需求始于分析用户将执行的查询类型,并确定最合适的搜索方法。
-
用户查询:确定用户预期执行的查询类型。这有助于确保您的 Schema 支持实际用例并优化搜索性能。这些查询可能包括:
-
检索与自然语言查询匹配的文档
-
查找与参考图像相似的图像或匹配文本描述
-
按名称、类别或品牌等属性搜索产品
-
基于结构化元数据(例如,出版日期、标签、评级)过滤项目
-
在混合查询中结合多个标准(例如,在视觉搜索中,同时考虑图像及其说明的语义相似性)
-
-
搜索方法:选择与用户将执行的查询类型相匹配的适当搜索技术。不同的方法服务于不同的目的,并且通常可以组合使用以获得更强大的结果:
-
语义搜索:利用密集向量相似度来查找含义相似的项目,非常适合文本或图像等非结构化数据。
-
全文搜索:通过关键词匹配来补充语义搜索。全文搜索可以利用词法分析,避免将长词拆分成碎片化的词元,在检索过程中把握特殊术语。
-
元数据过滤:在向量搜索的基础上,应用日期范围、类别或标签等约束条件。
-
将业务需求转化为服务于搜索的数据模型
下一步是通过确定信息的核心组件及其搜索方法,将您的业务需求转化为具体的数据模型:
-
定义你需要存储的数据,如原始内容(文本、图像、音频)、关联的元数据(标题、标签、作者信息)以及上下文属性(时间戳、用户行为等)
-
确定每个元素的适当数据类型和格式。例如:
-
文本描述 → 字符串
-
图像或文档嵌入 → 密集或稀疏向量
-
类别、标签或标志 → 字符串、数组和布尔值
-
像价格或评级这样的数值属性 → 整数或浮点数
-
结构化信息,如作者详情 -> json
-
对这些元素进行清晰定义可确保数据展示一致性、准确的搜索结果,并便于与下游应用逻辑集成。
设计 Schema
在Zilliz Cloud中,数据模型通过 Collection Schema 来表达。在 Collection Schema 中设计合适的字段是实现有效检索的关键。每个字段定义了 Collection 中存储的特定类型的数据,并在搜索过程中发挥着独特的作用。从高层次来看,Zilliz Cloud支持两种主要类型的字段:向量字段和标量字段。
现在,您可以将您的数据模型映射到一个包含向量和任何辅助标量字段的字段 Schema 中。确保每个字段与您的数据模型中的属性相关联,尤其要注意您的向量类型(密集或稀疏)及其维度。
向量字段
向量字段存储非结构化数据类型(如文本、图像和音频)的嵌入向量。这些嵌入向量可能是密集型、稀疏型或二进制型,具体取决于数据类型和所采用的检索方法。通常,密集向量用于语义搜索,而稀疏向量更适合全文或词法匹配。当存储和计算资源有限时,二进制向量很有用。一个 Collection 可能包含多个向量字段,以支持多模态或混合检索策略。有关此主题的详细指南,请参阅 Hybrid Search。
Zilliz Cloud支持以下向量数据类型:FLOAT_VECTOR 为 稠密向量,SPARSE_FLOAT_VECTOR 为 稀疏向量,以及BINARY_VECTOR 为 Binary 向量。
标量字段
标量字段存储原始的、结构化的值(通常称为元数据),如数字、字符串或日期。这些值可以与向量搜索结果一起返回,对于过滤和排序至关重要。它们允许你根据特定属性缩小搜索结果范围,例如将文档限制在特定类别或定义的时间范围内。
Zilliz Cloud支持标量类型,如BOOL、INT8/16/32/64、FLOAT、DOUBLE、VARCHAR、JSON和ARRAY,用于存储和过滤非向量数据。这些类型提高了搜索操作的精度和定制性。
在 Schema 设计中利用高级特性
在设计 Schema 时,仅仅使用支持的数据类型将数据映射到字段是不够的。必须深入理解字段之间的关系以及可用的配置策略。在设计阶段牢记关键特性,可确保 Schema 不仅能满足当前的数据处理需求,还具有可扩展性和适应性,以满足未来的需求。通过精心整合这些特性,您可以构建一个强大的数据架构,充分发挥Zilliz Cloud的功能,并支持您更广泛的数据战略和目标。以下是创建 Collection Schema 的关键特性概述:
主键
主键字段是 Schema 的基本组成部分,因为它能唯一标识 Collection 中的每个 Entity。定义主键是强制性的。它必须是整数或字符串类型的标量字段,并标记为is_primary=True。你可以选择启用 auto_id 作为主键,它会自动分配整数编号,随着更多数据被摄入 Collection 而单调递增。
如需进一步详情,请参考主键与 AutoID。
Partitions
为加快搜索速度,您可以选择开启分区功能。通过指定特定的标量字段进行分区,并在搜索过程中基于该字段指定过滤条件,可以有效地将搜索范围限制在相关分区内。这种方法通过缩小搜索域,显著提高了检索操作的效率。
有关更多详细信息,请参阅使用 Partition Key。
Analyzer
分析器是处理和转换文本数据的重要工具。其主要功能是将原始文本转换为词元,并对其进行结构化处理,以便进行索引和检索。它通过对字符串进行分词、去除停用词,并将单个单词词干化为词元来实现这一目的。
如需进一步详情,请参考Analyzer 概述。
Function
Zilliz Cloud允许您将内置 Function 定义为 Schema 的一部分,以自动派生某些字段。例如,您可以添加一个内置的 BM25 Function,该 Function 从VARCHAR字段生成稀疏向量,以支持全文搜索。这些由 Function 派生的字段简化了预处理过程,并确保 Collection 保持自包含且随时可查询。
如需进一步详情,请参考Full Text Search。
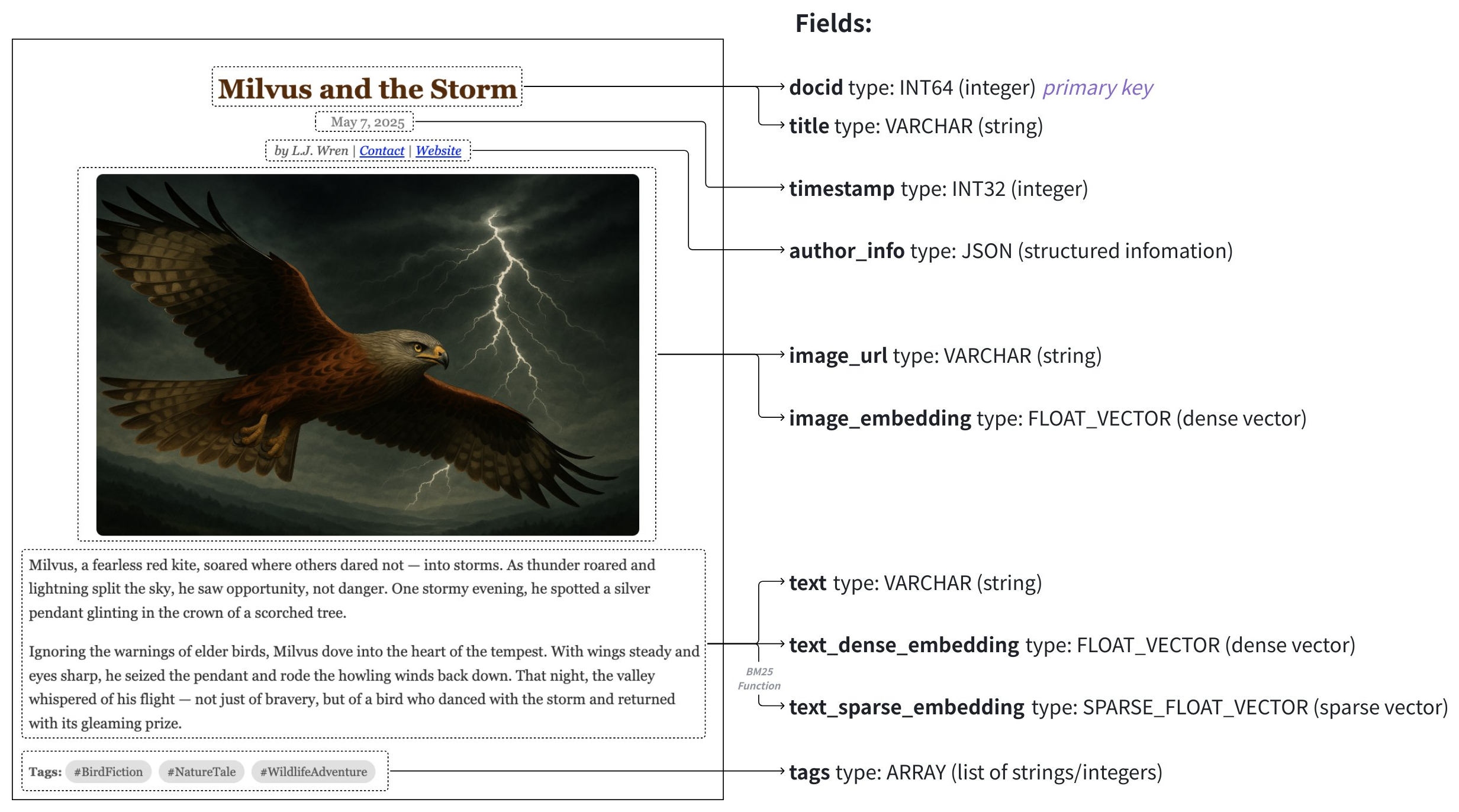
一个现实世界的例子
在本节中,我们将概述上图所示多媒体文档搜索应用程序的架构设计和代码示例。 此架构旨在管理一个数据集,该数据集包含的数据映射到以下字段的文章:
字段 | 数据源 | 使用的搜索方法 | 主键 | Partition Key | Analyzer | Function 输入/输出 |
|---|---|---|---|---|---|---|
article_id ( | 自动生成,启用 | Y | N | N | N | |
标题 ( | 文章标题 | N | N | Y | N | |
时间戳 ( | 发布日期 | N | Y | N | N | |
文本 ( | 文章的原始文本 | N | N | Y | 输入 | |
text_dense_vector ( | 由文本嵌入模型生成的密集向量 | N | N | N | N | |
text_sparse_vector ( | 由内置BM25 Function 自动生成的稀疏向量 | N | N | N | 输出 |
有关 Schema 的更多信息以及添加各种类型字段的详细指南,请参阅了解 Schema。
步骤 1:初始化 Schema
首先,我们需要创建一个空的 Schema。此步骤为我们定义数据模型建立了结构基础。
- Python
- Java
- NodeJS
- Go
- cURL
from pymilvus import MilvusClient
schema = MilvusClient.create_schema()
import io.milvus.v2.client.ConnectConfig;
import io.milvus.v2.client.MilvusClientV2;
import io.milvus.v2.service.collection.request.CreateCollectionReq;
// 1. Connect to Milvus server
ConnectConfig connectConfig = ConnectConfig.builder()
.uri("https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530")
.build();
MilvusClientV2 client = new MilvusClientV2(connectConfig);
// 2. Create an empty schema
CreateCollectionReq.CollectionSchema schema = client.createSchema();
import { MilvusClient, DataType } from "@zilliz/milvus2-sdk-node";
//Skip this step using JavaScript
import "github.com/milvus-io/milvus/client/v2/entity"
schema := entity.NewSchema()
# Skip this step using cURL
步骤 2:添加字段
在完成 Schema 创建后,下一步就是在其中添加构成您数据的字段。每个字段都有各自的数据类型和属性。
- Python
- Java
- NodeJS
- Go
- cURL
from pymilvus import DataType
schema.add_field(field_name="article_id", datatype=DataType.INT64, is_primary=True, auto_id=True, description="article id")
schema.add_field(field_name="title", datatype=DataType.VARCHAR, enable_analyzer=True, enable_match=True, max_length=200, description="article title")
schema.add_field(field_name="timestamp", datatype=DataType.INT32, description="publish date")
schema.add_field(field_name="text", datatype=DataType.VARCHAR, max_length=2000, enable_analyzer=True, description="article text content")
schema.add_field(field_name="text_dense_vector", datatype=DataType.FLOAT_VECTOR, dim=768, description="text dense vector")
schema.add_field(field_name="text_sparse_vector", datatype=DataType.SPARSE_FLOAT_VECTOR, description="text sparse vector")
import io.milvus.v2.common.DataType;
import io.milvus.v2.service.collection.request.AddFieldReq;
schema.addField(AddFieldReq.builder()
.fieldName("article_id")
.dataType(DataType.Int64)
.isPrimaryKey(true)
.autoID(true)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("title")
.dataType(DataType.VarChar)
.maxLength(200)
.enableAnalyzer(true)
.enableMatch(true)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("timestamp")
.dataType(DataType.Int32)
.build())
schema.addField(AddFieldReq.builder()
.fieldName("text")
.dataType(DataType.VarChar)
.maxLength(2000)
.enableAnalyzer(true)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("text_dense_vector")
.dataType(DataType.FloatVector)
.dimension(768)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("text_sparse_vector")
.dataType(DataType.SparseFloatVector)
.build());
const fields = [
{
name: "article_id",
data_type: DataType.Int64,
is_primary_key: true,
auto_id: true
},
{
name: "title",
data_type: DataType.VarChar,
max_length: 200,
enable_analyzer: true,
enable_match: true
},
{
name: "timestamp",
data_type: DataType.Int32
},
{
name: "text",
data_type: DataType.VarChar,
max_length: 2000,
enable_analyzer: true
},
{
name: "text_dense_vector",
data_type: DataType.FloatVector,
dim: 768
},
{
name: "text_sparse_vector",
data_type: DataType.SparseFloatVector
}
]
schema.WithField(entity.NewField().
WithName("article_id").
WithDataType(entity.FieldTypeInt64).
WithIsPrimaryKey(true).
WithIsAutoID(true).
WithDescription("article id"),
).WithField(entity.NewField().
WithName("title").
WithDataType(entity.FieldTypeVarChar).
WithMaxLength(200).
WithEnableAnalyzer(true).
WithEnableMatch(true).
WithDescription("article title"),
).WithField(entity.NewField().
WithName("timestamp").
WithDataType(entity.FieldTypeInt32).
WithDescription("publish date"),
).WithField(entity.NewField().
WithName("text").
WithDataType(entity.FieldTypeVarChar).
WithMaxLength(2000).
WithEnableAnalyzer(true).
WithDescription("article text content"),
).WithField(entity.NewField().
WithName("text_dense_vector").
WithDataType(entity.FieldTypeFloatVector).
WithDim(768).
WithDescription("text dense vector"),
).WithField(entity.NewField().
WithName("text_sparse_vector").
WithDataType(entity.FieldTypeSparseVector).
WithDescription("text sparse vector"),
)
export fields='[
{
"fieldName": "article_id",
"dataType": "Int64",
"isPrimary": true
},
{
"fieldName": "title",
"dataType": "VarChar",
"elementTypeParams": {
"max_length": 200,
"enable_analyzer": true,
"enable_match": true
}
},
{
"fieldName": "timestamp",
"dataType": "Int32"
},
{
"fieldName": "text",
"dataType": "VarChar",
"elementTypeParams": {
"max_length": 2000,
"enable_analyzer": true
}
},
{
"fieldName": "text_dense_vector",
"dataType": "FloatVector",
"elementTypeParams": {
"dim": 768
}
},
{
"fieldName": "text_sparse_vector",
"dataType": "SparseFloatVector",
}
]'
export schema="{
\"autoID\": true,
\"fields\": $fields
}"
在这个示例中,为字段指定了以下属性:
-
主键:
article_id用作主键,可自动为传入 Entity 分配主键。 -
Partition Key:
timestamp被指定为 Partition Key,允许按 Partition 进行过滤。 -
文本 Analyzer:文本 Analyzer 分别应用于两个字符串字段(
title和text),以支持 Text Match 和Full Text Search。
步骤 3:(可选)添加 Function
为增强数据查询能力,可将 Function 纳入 Schema 中。例如,可以创建一个 Function 来处理与特定字段相关的内容。
- Python
- Java
- NodeJS
- Go
- cURL
from pymilvus import Function, FunctionType
bm25_function = Function(
name="text_bm25",
input_field_names=["text"],
output_field_names=["text_sparse_vector"],
function_type=FunctionType.BM25,
)
schema.add_function(bm25_function)
import io.milvus.common.clientenum.FunctionType;
import io.milvus.v2.service.collection.request.CreateCollectionReq.Function;
import java.util.*;
schema.addFunction(Function.builder()
.functionType(FunctionType.BM25)
.name("text_bm25")
.inputFieldNames(Collections.singletonList("text"))
.outputFieldNames(Collections.singletonList("text_sparse_vector"))
.build());
import FunctionType from "@zilliz/milvus2-sdk-node";
const functions = [
{
name: 'text_bm25',
description: 'bm25 function',
type: FunctionType.BM25,
input_field_names: ['text'],
output_field_names: ['text_sparse_vector'],
params: {},
},
];
function := entity.NewFunction().
WithName("text_bm25").
WithInputFields("text").
WithOutputFields("text_sparse_vector").
WithType(entity.FunctionTypeBM25)
schema.WithFunction(function)
export myFunctions='[
{
"name": "text_bm25",
"type": "BM25",
"inputFieldNames": ["text"],
"outputFieldNames": ["text_sparse_vector"],
"params": {}
}
]'
export schema="{
\"autoID\": true,
\"fields\": $fields
\"functions\": $myFunctions
}"
此示例在 Schema 中添加了一个内置的 BM25 Function,利用文本字段作为输入,并将生成的稀疏向量存储在text_sparse_vector 字段中。