Text Match
Milvus 中的 Text Match 功能能够基于特定术语实现精确的文档检索。通过使用关键词预筛选文档,可以缩小向量搜索的范围,从而提升搜索效率。该功能还可以结合标量过滤,以进一步优化查询结果。
无论是构建检索增强生成(RAG)系统,还是优化文本搜索性能,Text Match 都能提升信息检索的准确性和速度。
Text Match 关注的是查询词的精确匹配,而不对匹配文档的相关性进行评分。如果希望基于查询词的语义和重要性来检索最相关的文档,建议使用 全文搜索。
Zilliz Cloud 支持通过代码或通过 Web 控制台开启 Text Match 功能。本文着重介绍如何通过代码开启 Text Match,如需了解 Web 控制台操作,请参考管理 Collection (控制台)。
概述
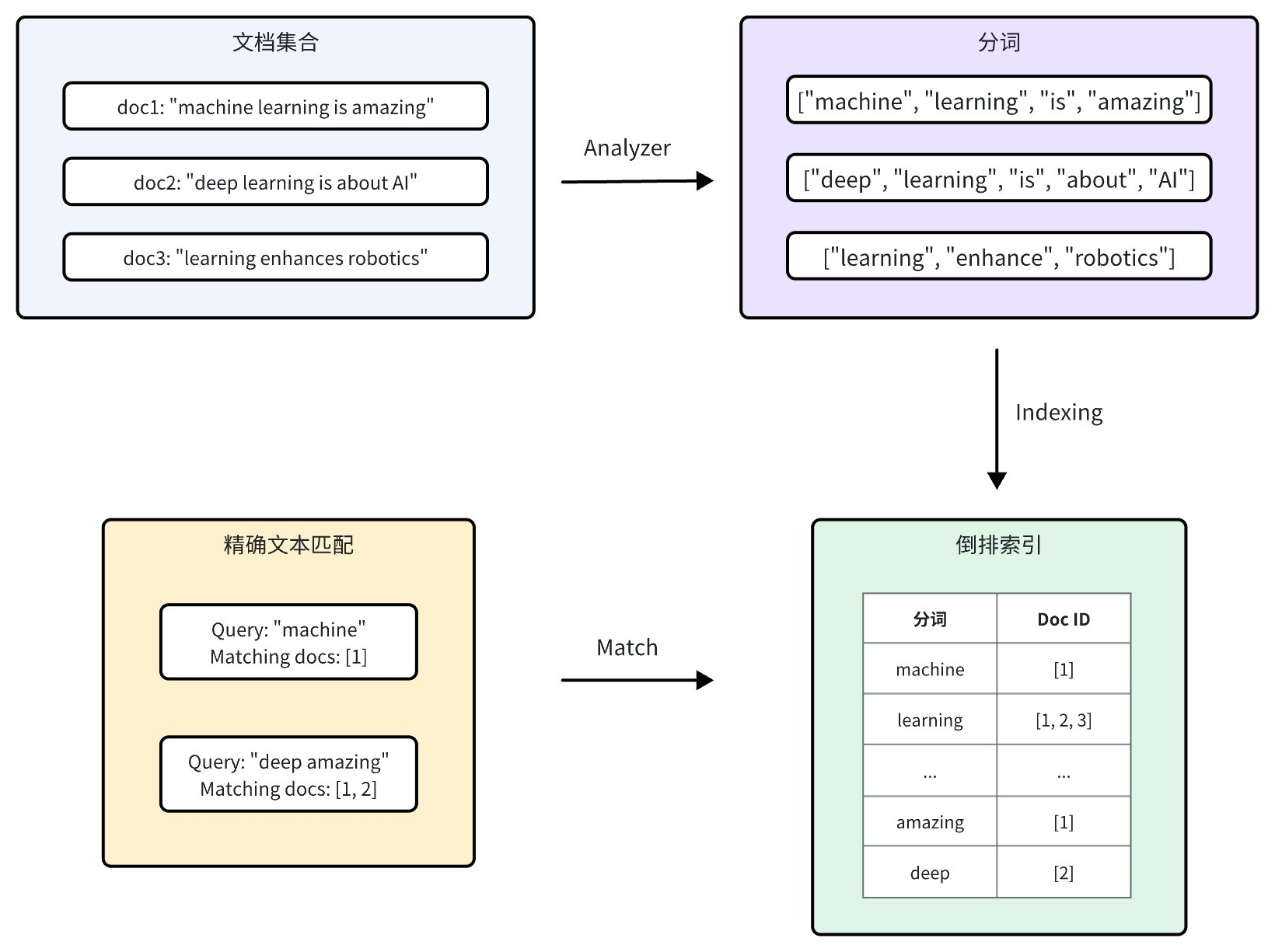
Milvus 通过集成 Tantivy 来实现 Text Match 和关键词检索,以提升搜索速度和查询效率。对于每条文本记录,Zilliz Cloud 会按照以下步骤进行索引:
-
Analyzer:Analyzer 将输入文本分解为单个单词或标记,使得系统能够基于这些分词构建索引。
-
倒排索引:完成分词后,Zilliz Cloud 会创建一个倒排索引,将每个唯一分词映射到包含该分词的文档。
当用户执行精确文本搜索时,倒排索引能够快速检索到包含这些关键词的所有文档,这比逐行搜索文档的效率更高。
开启 Text Match
Text Match 适用于 VARCHAR 字段类型,即 Zilliz Cloud 中的字符数据类型。要启用 Text Match,您需要在定义 Collection Schema 时将 enable_analyzer 和 enable_match 参数都设置为 True,并可以选择配置 Analyzer。
设置 enable_analyzer 和 enable_match
要为特定的 VARCHAR 字段启用 Text Match,在定义字段 Schema 时需将 enable_analyzer 和 enable_match 参数都设置为 True。这指示 Milvus 对文本进行分词,并为指定字段创建倒排索引,从而实现快速高效的 Text Match。
- Python
- Java
- Go
- NodeJS
- cURL
from pymilvus import MilvusClient, DataType
schema = MilvusClient.create_schema(enable_dynamic_field=False)
schema.add_field(
field_name="id",
datatype=DataType.INT64,
is_primary=True,
auto_id=True
)
schema.add_field(
field_name='text',
datatype=DataType.VARCHAR,
max_length=1000,
enable_analyzer=True, # Whether to enable text analysis for this field
enable_match=True # Whether to enable text match
)
schema.add_field(
field_name="embeddings",
datatype=DataType.FLOAT_VECTOR,
dim=5
)
import io.milvus.v2.common.DataType;
import io.milvus.v2.service.collection.request.AddFieldReq;
import io.milvus.v2.service.collection.request.CreateCollectionReq;
CreateCollectionReq.CollectionSchema schema = CreateCollectionReq.CollectionSchema.builder()
.enableDynamicField(false)
.build();
schema.addField(AddFieldReq.builder()
.fieldName("id")
.dataType(DataType.Int64)
.isPrimaryKey(true)
.autoID(true)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("text")
.dataType(DataType.VarChar)
.maxLength(1000)
.enableAnalyzer(true)
.enableMatch(true)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("embeddings")
.dataType(DataType.FloatVector)
.dimension(5)
.build());
import "github.com/milvus-io/milvus/client/v2/entity"
schema := entity.NewSchema().WithDynamicFieldEnabled(false)
schema.WithField(entity.NewField().
WithName("id").
WithDataType(entity.FieldTypeInt64).
WithIsPrimaryKey(true).
WithIsAutoID(true),
).WithField(entity.NewField().
WithName("text").
WithDataType(entity.FieldTypeVarChar).
WithEnableAnalyzer(true).
WithEnableMatch(true).
WithMaxLength(1000),
).WithField(entity.NewField().
WithName("embeddings").
WithDataType(entity.FieldTypeFloatVector).
WithDim(5),
)
const schema = [
{
name: "id",
data_type: DataType.Int64,
is_primary_key: true,
},
{
name: "text",
data_type: "VarChar",
enable_analyzer: true,
enable_match: true,
max_length: 1000,
},
{
name: "embeddings",
data_type: DataType.FloatVector,
dim: 5,
},
];
export schema='{
"autoId": true,
"enabledDynamicField": false,
"fields": [
{
"fieldName": "id",
"dataType": "Int64",
"isPrimary": true
},
{
"fieldName": "text",
"dataType": "VarChar",
"elementTypeParams": {
"max_length": 1000,
"enable_analyzer": true,
"enable_match": true
}
},
{
"fieldName": "embeddings",
"dataType": "FloatVector",
"elementTypeParams": {
"dim": "5"
}
}
]
}'
可选:配置 Analyzer
Text Match 的性能和准确性依赖于所选的 Analyzer。不同的 Analyzer 对语言和文本结构的处理方式不同,因此选择适合您用例的 Analyzer 非常重要。
默认情况下,Milvus 使用 standard analyzer。该 Analyzer 基于空格和标点符号对文本进行分词,删除超过 40 个字符的分词,并将文本转换为小写。使用 standard analyzer 无需您指定任何参数。
对于非字母语言或特定场景,您可能需要配置自定义 Analyzer。Milvus 提供针对不同语言和场景优化的多种 Analyzer。
要配置自定义 Analyzer,可以使用 analyzer_params 参数。例如,使用 Jieba 分词器处理中文文本:
- Python
- Java
- Go
- NodeJS
- cURL
analyzer_params = {
"type": "english"
}
schema.add_field(
field_name='text',
datatype=DataType.VARCHAR,
max_length=200,
enable_analyzer=True,
analyzer_params = analyzer_params,
enable_match = True,
)
Map<String, Object> analyzerParams = new HashMap<>();
analyzerParams.put("type", "english");
schema.addField(AddFieldReq.builder()
.fieldName("text")
.dataType(DataType.VarChar)
.maxLength(200)
.enableAnalyzer(true)
.analyzerParams(analyzerParams)
.enableMatch(true)
.build());
analyzerParams := map[string]any{"type": "english"}
schema.WithField(entity.NewField().
WithName("text").
WithDataType(entity.FieldTypeVarChar).
WithEnableAnalyzer(true).
WithEnableMatch(true).
WithAnalyzerParams(analyzerParams).
WithMaxLength(200),
)
const schema = [
{
name: "id",
data_type: DataType.Int64,
is_primary_key: true,
},
{
name: "text",
data_type: "VarChar",
enable_analyzer: true,
enable_match: true,
max_length: 1000,
analyzer_params: { type: 'english' },
},
{
name: "embeddings",
data_type: DataType.FloatVector,
dim: 5,
},
];
export schema='{
"autoId": true,
"enabledDynamicField": false,
"fields": [
{
"fieldName": "id",
"dataType": "Int64",
"isPrimary": true
},
{
"fieldName": "text",
"dataType": "VarChar",
"elementTypeParams": {
"max_length": 200,
"enable_analyzer": true,
"enable_match": true,
"analyzer_params": {"type": "english"}
}
},
{
"fieldName": "embeddings",
"dataType": "FloatVector",
"elementTypeParams": {
"dim": "5"
}
}
]
}'
有关可用分词器及其配置的更多信息,请参考 Tokenizer。
使用 Text Match
在 Collection Schema 中为 VARCHAR 字段启用 Text Match 后,您可以使用 TEXT_MATCH 表达式执行文本匹配。
TEXT_MATCH 表达式语法
TEXT_MATCH 表达式用于指定要搜索的字段和关键词,其语法如下:
TEXT_MATCH(field_name, text)
-
field_name:要搜索的 VARCHAR 字段的名称。 -
text:要搜索的关键词。多个关键词可以用空格或根据语言和配置的分词器使用其他适当的分隔符进行分隔。
默认情况下,TEXT_MATCH 使用“OR”匹配逻辑,即会返回包含任意指定关键词的文档。例如,搜索 docs 字段中包含关键词 "machine" 或 "deep" 的文档,使用以下表达式:
- Python
- Java
- Go
- NodeJS
- cURL
filter = "TEXT_MATCH(text, 'machine deep')"
String filter = "TEXT_MATCH(text, 'machine deep')";
filter := "TEXT_MATCH(text, 'machine deep')"
const filter = "TEXT_MATCH(text, 'machine deep')";
export filter="\"TEXT_MATCH(text, 'machine deep')\""
您也可以使用逻辑运算符组合多个 TEXT_MATCH 表达式,以实现“AND”匹配。
-
例如,搜索
text字段中同时包含"machine"和"deep"的文档,使用以下表达式:- Python
- Java
- Go
- NodeJS
- cURL
filter = "TEXT_MATCH(text, 'machine') and TEXT_MATCH(text, 'deep')"String filter = "TEXT_MATCH(text, 'machine') and TEXT_MATCH(text, 'deep')";filter := "TEXT_MATCH(text, 'machine') and TEXT_MATCH(text, 'deep')"const filter = "TEXT_MATCH(text, 'machine') and TEXT_MATCH(text, 'deep')"export filter="\"TEXT_MATCH(text, 'machine') and TEXT_MATCH(text, 'deep')\"" -
搜索
text字段中同时包含"machine"和"learning"但不包含"deep"的文档,使用以下表达式:- Python
- Java
- Go
- NodeJS
- cURL
filter = "not TEXT_MATCH(text, 'deep') and TEXT_MATCH(text, 'machine') and TEXT_MATCH(text, 'learning')"String filter = "not TEXT_MATCH(text, 'deep') and TEXT_MATCH(text, 'machine') and TEXT_MATCH(text, 'learning')";filter := "not TEXT_MATCH(text, 'deep') and TEXT_MATCH(text, 'machine') and TEXT_MATCH(text, 'learning')"const filter = "not TEXT_MATCH(text, 'deep') and TEXT_MATCH(text, 'machine') and TEXT_MATCH(text, 'learning')";export filter="\"not TEXT_MATCH(text, 'deep') and TEXT_MATCH(text, 'machine') and TEXT_MATCH(text, 'learning')\""
Search 时使用 Text Match
Text Match 可以与向量相似度搜索结合使用,以缩小搜索范围并提升搜索性能。通过在进行向量相似度搜索前使用 Text Match 筛选 Collection,可以减少需要搜索的文档数量,从而加快查询速度。
在以下示例中,filter 过滤了 Collection,只包括匹配指定关键词的文档。然后,在这个筛选后的文档子集中执行向量相似度搜索。
- Python
- Java
- Go
- NodeJS
- cURL
# Match entities with \`keyword1\` or \`keyword2\`
filter = "TEXT_MATCH(text, 'keyword1 keyword2')"
# Assuming 'embeddings' is the vector field and 'text' is the VARCHAR field
result = client.search(
collection_name="my_collection", # Your collection name
anns_field="embeddings", # Vector field name
data=[query_vector], # Query vector
# highlight-next-line
filter=filter,
search_params={"params": {"nprobe": 10}},
limit=10, # Max. number of results to return
output_fields=["id", "text"] # Fields to return
)
String filter = "TEXT_MATCH(text, 'keyword1 keyword2')";
SearchResp searchResp = client.search(SearchReq.builder()
.collectionName("my_collection")
.annsField("embeddings")
.data(Collections.singletonList(queryVector)))
// highlight-next-line
.filter(filter)
.topK(10)
.outputFields(Arrays.asList("id", "text"))
.build());
filter := "TEXT_MATCH(text, 'keyword1 keyword2')"
resultSets, err := client.Search(ctx, milvusclient.NewSearchOption(
"my_collection", // collectionName
10, // limit
[]entity.Vector{entity.FloatVector(queryVector)},
).WithANNSField("embeddings").
WithFilter(filter).
WithOutputFields("id", "text"))
if err != nil {
fmt.Println(err.Error())
// handle error
}
// Match entities with \`keyword1\` or \`keyword2\`
const filter = "TEXT_MATCH(text, 'keyword1 keyword2')";
// Assuming 'embeddings' is the vector field and 'text' is the VARCHAR field
const result = await client.search(
collection_name: "my_collection", // Your collection name
anns_field: "embeddings", // Vector field name
data: [query_vector], // Query vector
// highlight-next-line
filter: filter,
params: {"nprobe": 10},
limit: 10, // Max. number of results to return
output_fields: ["id", "text"] //Fields to return
);
export filter="\"TEXT_MATCH(text, 'keyword1 keyword2')\""
export CLUSTER_ENDPOINT="https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530"
export TOKEN="YOUR_CLUSTER_TOKEN"
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/search" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
-d '{
"collectionName": "my_collection",
"annsField": "embeddings",
"data": [[0.19886812562848388, 0.06023560599112088, 0.6976963061752597, 0.2614474506242501, 0.838729485096104]],
"filter": '"$filter"',
"searchParams": {
"params": {
"nprobe": 10
}
},
"limit": 10,
"outputFields": ["text","id"]
}'
Query 时使用 Text Match
Text Match 还可以用于查询操作中的标量过滤。通过在 query() 方法的 expr 参数中指定 TEXT_MATCH 表达式,可以检索到匹配给定关键词的文档。
以下示例中,查询 text 字段中包含关键词 "keyword1" 和 "keyword2"的文档:
- Python
- Java
- NodeJS
- cURL
# Match entities with both \`keyword1\` and \`keyword2\`
filter = "TEXT_MATCH(text, 'keyword1') and TEXT_MATCH(text, 'keyword2')"
result = client.query(
collection_name="YOUR_COLLECTION_NAME",
filter=filter,
output_fields=["id", "text"]
)
String filter = "TEXT_MATCH(text, 'keyword1') and TEXT_MATCH(text, 'keyword2')";
QueryResp queryResp = client.query(QueryReq.builder()
.collectionName("YOUR_COLLECTION_NAME")
.filter(filter)
.outputFields(Arrays.asList("id", "text"))
.build()
);
// Match entities with both \`keyword1\` and \`keyword2\`
const filter = "TEXT_MATCH(text, 'keyword1') and TEXT_MATCH(text, 'keyword2')";
const result = await client.query(
collection_name: "YOUR_COLLECTION_NAME",
filter: filter,
output_fields: ["id", "text"]
)
export filter="\"TEXT_MATCH(text, 'keyword1') and TEXT_MATCH(text, 'keyword2')\""
export CLUSTER_ENDPOINT="https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530"
export TOKEN="YOUR_CLUSTER_TOKEN"
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/query" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
-d '{
"collectionName": "demo2",
"filter": '"$filter"',
"outputFields": ["id", "text"]
}'
注意事项
-
为字段启用 Text Match 时,会创建倒排索引,这会占用存储资源。启用该功能时请考虑存储影响,因为这取决于文本大小、唯一分词数量以及使用的分词器。
-
一旦在 Schema 中定义了分词器配置,该配置就会固定在 Collection 上。如果您认为其他分词器更适合您的需求,可以考虑删除现有的 Collection 并创建一个包含所需分词器配置的新 Collection。