使用 mmap
Mmap 允许在不将磁盘上的文件加载到内存的情况下通过内存访问这些文件。通过配置 mmap,Zilliz Cloud 可以根据访问频次的不同将索引和数据分别存放到内存或磁盘上,不仅优化了数据加载行为,扩大了 Collection 的容量,也不会给搜索性能带来负面影响。本文将帮助您理解 Zilliz Cloud 如何利用 mmap 实现快速高效的数据存储和检索能力及使用该能力需要注意的相关事项。
在不同订阅计划的源集群和目标集群之间迁移或还原数据时,源 Collection 的 mmap 设置不会迁移到目标集群。请手动重新配置目标集群上的 mmap 设置。
Zilliz Cloud 支持通过代码或通过 Web 控制台使用 mmap。本文着重介绍如何通过代码设置 mmap 策略,如需了解 Web 控制台操作,请参考管理 Collection (控制台)。
概述
Zilliz Cloud 使用 Collection 来组织向量数据及其元数据,并将它们按照列的形式组织成一张表格。表格中的每一行就代表一个 Entity。如下图左侧所示,在一个 Entity 中,向量列用来存放向量数据,而标量列用来存放与该向量相关的元数据信息。当您在向量列上创建索引并加载 Collection 后,Zilliz Cloud 就会将 Collection 中所有标量列中存放的原始数据及您在向量列上创建的索引文件加载到内存。
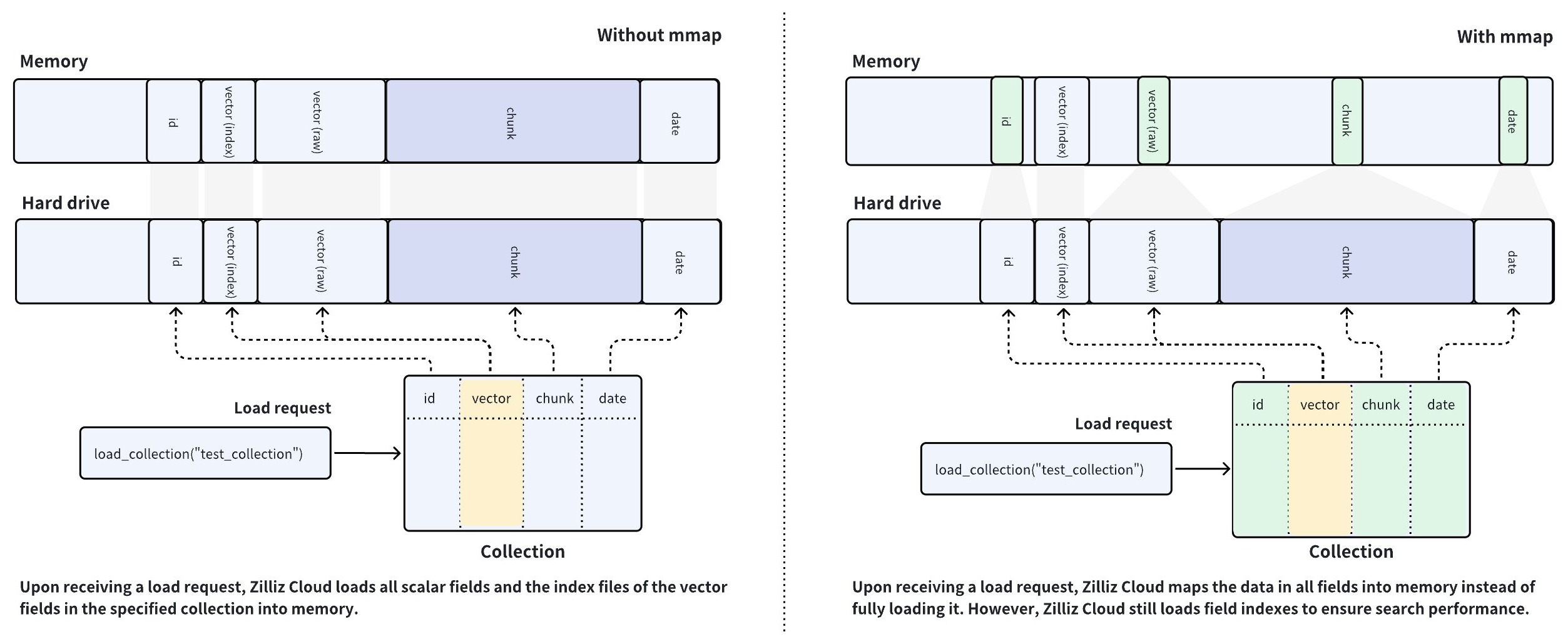
Zilliz Cloud 是一款内存密集型的数据库系统。可用内存的大小决定了 Collection 的容量。如果加载的列中存放的数据大于内存大小时,可能会遇到加载失败的情况。而加载大体积数据这种情况在 AI 驱动的应用中是比较常见的情况。
为了解决此类矛盾,Zilliz Cloud 在 Collection 中默认启用了 mmap 能力。如上图右侧所示,当您在 Zilliz Cloud 中加载 Collection 时,Zilliz Cloud 会使用 mmap 将所有列的原始数据映射到内存并加载向量列的索引文件到内存。
通过对比上图左右两侧的数据加载情况,您应该可以发现在未启用 mmap 能力时,内存压力较大,当需要加载的数据大于内存大小时,就会导致加载失败。而在启用 mmap 能力后,所有字段的原始数据都以映射的方式加载到内存。用户通过内存上的指针访问的仍旧是存放在磁盘上的数据,大大节约了内存资源的使用。
全局 mmap 策略
下表罗列了使用不同配置的集群对应的全局 mmap 策略。
Mmap 对象 | Dedicated 集群 | Free 集群 Serverless 集群 | ||
|---|---|---|---|---|
性能型 CU | 容量型 CU | 分层存储型 CU | ||
标量字段原始数据 | 默认关闭,可修改 | 默认开启,可修改 | 默认开启,不可修改 | |
标量字段索引 | 默认关闭,可修改 | 默认开启,可修改 | 默认开启,不可修改 | |
向量字段原始数据 | 默认开启,可修改 | 默认开启,可修改 | 默认开启,不可修改 | |
向量字段索引 | 默认关闭,不可修改 | 默认关闭,不可修改 | 默认开启,不可修改 | |
对于使用性能型 CU 的 Dedicated 集群而言, Zilliz Cloud 只在向量字段原始数据上启用了 mmap,并在加载 Collection 时将标量字段的原始数据及所有字段的索引都加载到内存。建议您保持全局配置,确保在搜索和查询过程中元数据过滤和检索的性能。另外,您可以考虑为不参与元数据过滤的标量字段开启 mmap,以减少内存开销,扩大 Collection 容量。
对于使用容量型 CU 的 Dedicated 集群而言,Zilliz Cloud 只在向量字段索引上关闭了 mmap 以保证索引性能,并在加载 Collection 时将标量字段索引和所有字段的原始数据都通过 mmap 的方式转存在磁盘上,从而保证了 Collection 容量的最大化。另外,您可以考虑在参与元数据过滤的标量字段和在搜索和查询请求的输出字段列表中引用的原始数据量过大的标量字段上关闭 mmap,以提升搜索和查询的响应速度,减少网络抖动,提升查询性能。
在 Free 和 Serverless 集群以及使用存储扩展型 CU 的 Dedicated 集群而言,Zilliz Cloud 默认使用 mmap 来处理所有字段的原始数据及索引文件,以最大化利用系统缓存能力,提升热数据查询性能,降低冷数据查询成本。
在 Collection 中设置 mmap
在修改 mmap 设置前,需要释放 Collection。修改完成后,需要再次加载 Collection。您可以为某个字段、某个字段的索引或某个 Collection 分别设置 mmap 策略
请谨慎修改 mmap 设置。不恰当的 mmap 策略可能会导致如下问题:
-
对于使用性能型 CU 的 Dedicated 集群而言,在加载 Collection 时,所有标量字段的原始数据和向量字段索引默认会被加载到内存以保证在搜索和查询中对标量字段的快速访问。修改默认设置可能会导致性能下降。
-
对于使用容量型 CU 的 Dedicated 集群而言,在加载 Collection时,只有向量字段索引被默认加载到内存以保障 Collection 容量的最大化。修改默认设置可能会因 Collection 缩小而出现内存不足(OOM)问题。
在字段上配置 mmap 策略
如果您的集群使用的是小规格的性能型 CU,但是某个标量字段的原始数据体积较大,可以考虑在这个标量字段上开启 mmap。
如下示例假设您连接到了一个使用性能型 CU 的 Dedicated 集群,并演示了如何在名为 doc_chunk 的 VARCHAR 字段上启用 mmap。
- Python
- Java
- NodeJS
- Go
- cURL
from pymilvus import MilvusClient, DataType
CLUSTER_ENDPOINT="https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530"
TOKEN="YOUR_CLUSTER_TOKEN"
client = MilvusClient(
uri=CLUSTER_ENDPOINT,
token=TOKEN
)
schema = MilvusClient.create_schema()
schema.add_field("id", DataType.INT64, is_primary=True, auto_id=False)
schema.add_field("vector", DataType.FLOAT_VECTOR, dim=5)
# Disable mmap on a field upon creating the schema for a collection
schema.add_field(
field_name="doc_chunk",
datatype=DataType.INT64,
max_length=512,
# highlight-next-line
mmap_enabled=False,
)
client.create_collection(collection_name="my_collection", schema=schema)
# Disable mmap on an existing field
# The following assumes that you have a collection named \`my_collection\`
client.alter_collection_field(
collection_name="my_collection",
field_name="doc_chunk",
field_params={"mmap.enabled": True}
)
import io.milvus.param.Constant;
import io.milvus.v2.client.ConnectConfig;
import io.milvus.v2.client.MilvusClientV2;
import io.milvus.v2.common.DataType;
import io.milvus.v2.service.collection.request.*;
import java.util.*;
String CLUSTER_ENDPOINT = "https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530";
String TOKEN = "YOUR_CLUSTER_TOKEN";
client = new MilvusClientV2(ConnectConfig.builder()
.uri(CLUSTER_ENDPOINT)
.token(TOKEN)
.build());
CreateCollectionReq.CollectionSchema schema = client.createSchema();
schema.addField(AddFieldReq.builder()
.fieldName("id")
.dataType(DataType.Int64)
.isPrimaryKey(true)
.autoID(false)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("vector")
.dataType(DataType.FloatVector)
.dimension(5)
.build());
Map<String, String> typeParams = new HashMap<String, String>() {{
put(Constant.MMAP_ENABLED, "false");
}};
schema.addField(AddFieldReq.builder()
.fieldName("doc_chunk")
.dataType(DataType.VarChar)
.maxLength(512)
.typeParams(typeParams)
.build());
CreateCollectionReq req = CreateCollectionReq.builder()
.collectionName("my_collection")
.collectionSchema(schema)
.build();
client.createCollection(req);
client.alterCollectionField(AlterCollectionFieldReq.builder()
.collectionName("my_collection")
.fieldName("doc_chunk")
.property(Constant.MMAP_ENABLED, "true")
.build());
import { MilvusClient, DataType } from '@zilliz/milvus2-sdk-node';
const CLUSTER_ENDPOINT="https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530";
const TOKEN="YOUR_TOKEN";
const client = await MilvusClient({
address: CLUSTER_ENDPOINT,
token: TOKEN
});
const schema = [
{
name: 'vector',
data_type: DataType.FloatVector
},
{
name: "doc_chunk",
data_type: DataType.VarChar,
max_length: 512,
'mmap.enabled': false,
}
];
await client.createCollection({
collection_name: "my_collection",
schema: schema
});
await client.alterCollectionFieldProperties({
collection_name: "my_collection",
field_name: "doc_chunk",
properties: {"mmap_enable": true}
});
import (
"context"
"fmt"
"github.com/milvus-io/milvus/client/v2/column"
"github.com/milvus-io/milvus/client/v2/entity"
"github.com/milvus-io/milvus/client/v2/milvusclient"
)
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
milvusAddr := "https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530"
client, err := milvusclient.New(ctx, &milvusclient.ClientConfig{
Address: milvusAddr,
})
if err != nil {
fmt.Println(err.Error())
// handle error
}
defer client.Close(ctx)
schema := entity.NewSchema().WithDynamicFieldEnabled(false)
schema.WithField(entity.NewField().
WithName("id").
WithDataType(entity.FieldTypeInt64).
WithIsPrimaryKey(true),
).WithField(entity.NewField().
WithName("vector").
WithDataType(entity.FieldTypeFloatVector).
WithDim(5),
).WithField(entity.NewField().
WithName("doc_chunk").
WithDataType(entity.FieldTypeVarChar).
WithMaxLength(512).
WithTypeParams(common.MmapEnabledKey, "false"),
)
err = client.CreateCollection(ctx,
milvusclient.NewCreateCollectionOption("my_collection", schema))
if err != nil {
fmt.Println(err.Error())
// handle error
}
err = client.AlterCollectionFieldProperty(ctx, milvusclient.NewAlterCollectionFieldPropertiesOption("my_collection", "doc_chunk").
WithProperty(common.MmapEnabledKey, "true"))
if err != nil {
fmt.Println(err.Error())
// handle error
}
#restful
export TOKEN="YOUR_CLUSTER_TOKEN"
export CLUSTER_ENDPOINT="https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530"
export idField='{
"fieldName": "id",
"dataType": "Int64",
"isPrimary": true,
"auto_id": false
}'
export vectorField='{
"fieldName": "vector",
"dataType": "FloatVector",
"elementTypeParams": {
"dim": 5
}
}'
export docChunkField='{
"fieldName": "doc_chunk",
"dataType": "Varchar",
"elementTypeParams": {
"max_length": 512,
"mmap.enabled": false
}
}'
export schema="{
\"autoID\": false,
\"fields\": [
$idField,
$docChunkField,
$vectorField
]
}"
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/collections/create" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
--data "{
\"collectionName\": \"my_collection\",
\"schema\": $schema
}"
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/collections/fields/alter_properties" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
-d '{
"collectionName": "my_collection",
"fieldName": "doc_chunk",
"fieldParams":{
"mmap.enabled": true
}
}'
当加载使用上述 Schema 的 Collection 时,Zilliz Cloud 会将 doc_field 字段的原始数据转移到硬盘上。对于修改已有字段的 mmap 设置前,需要先释放该字段所在的 Collection,并在修改完成后再加载该 Collection。
在标量索引上配置 mmap 策略
对于参与元数据过滤或在搜索或查询请求的输入字段列表中引用的标量字段,可以考虑在加载 Collection 时将这些字段加载到内存。
如下示例假设您连接到一个使用了容量型 CU 的 Dedicated 集群,并演示了如果在名为 title 的 VARCHAR 字段的索引上关闭 mmap 来加速对该字段的访问。
- Python
- Java
- NodeJS
- Go
- cURL
# Add a varchar field
schema.add_field(
field_name="title",
datatype=DataType.VARCHAR,
max_length=512
)
index_params = MilvusClient.prepare_index_params()
# Create index on the varchar field with mmap settings
index_params.add_index(
field_name="title",
index_type="AUTOINDEX",
# highlight-next-line
params={ "mmap.enabled": "false" }
)
# Change mmap settings for an index
# The following assumes that you have a collection named \`my_collection\`
client.alter_index_properties(
collection_name="my_collection",
index_name="title",
properties={"mmap.enabled": True}
)
schema.addField(AddFieldReq.builder()
.fieldName("title")
.dataType(DataType.VarChar)
.maxLength(512)
.build());
List<IndexParam> indexParams = new ArrayList<>();
Map<String, Object> extraParams = new HashMap<String, Object>() {{
put(Constant.MMAP_ENABLED, false);
}};
indexParams.add(IndexParam.builder()
.fieldName("title")
.indexType(IndexParam.IndexType.AUTOINDEX)
.extraParams(extraParams)
.build());
client.alterIndexProperties(AlterIndexPropertiesReq.builder()
.collectionName("my_collection")
.indexName("title")
.property(Constant.MMAP_ENABLED, "true")
.build());
// Create index on the varchar field with mmap settings
await client.createIndex({
collection_name: "my_collection",
field_name: "title",
params: { "mmap.enabled": false }
});
// Change mmap settings for an index
// The following assumes that you have a collection named \`my_collection\`
await client.alterIndexProperties({
collection_name: "my_collection",
index_name: "title",
properties:{"mmap.enabled": true}
});
schema.WithField(entity.NewField().
WithName("title").
WithDataType(entity.FieldTypeVarChar).
WithMaxLength(512),
)
indexOption := milvusclient.NewCreateIndexOption("my_collection", "title",
index.NewInvertedIndex())
indexOption.WithExtraParam(common.MmapEnabledKey, "false")
err = client.AlterIndexProperties(ctx, milvusclient.NewAlterIndexPropertiesOption("my_collection", "title").
WithProperty(common.MmapEnabledKey, "true"))
if err != nil {
fmt.Println(err.Error())
// handle error
}
# restful
export TOKEN="YOUR_CLUSTER_TOKEN"
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/indexes/create" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
-d '{
"collectionName": "my_collection",
"indexParams": [
{
"fieldName": "title",
"params": {
"index_type": "AUTOINDEX",
"mmap.enabled": false
}
}
]
}'
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/indexes/alter_properties" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
-d '{
"collectionName": "my_collection",
"indexName": "title",
"properties": {
"mmap.enabled": true
}
}'
在加载使用上述索引参数的 Collection 时,Zilliz Cloud 会将 title 字段的索引加载到内存。对于修改已有字段索引的 mmap 设置前,需要先释放该字段所在的 Collection,并在修改完成后再加载该 Collection。
在 Collection 中配置 mmap 策略
您可以在 Collection 设置中关闭 mmap,以便让 Zilliz Cloud 在加载 Collection 时将所有字段的原始数据加载到内存。
如下示例假设您连接了一个性能型的 Dedicated 集群,并演示了如何在创建 Collection 时禁用 mmap。
- Python
- Java
- NodeJS
- Go
- cURL
# Enable mmap when creating a collection
client.create_collection(
collection_name="my_collection",
schema=schema,
properties={ "mmap.enabled": "false" }
)
CreateCollectionReq req = CreateCollectionReq.builder()
.collectionName("my_collection")
.collectionSchema(schema)
.property(Constant.MMAP_ENABLED, "false")
.build();
client.createCollection(req);
await client.createCollection({
collection_name: "my_collection",
scheme: schema,
properties: { "mmap.enabled": false }
});
err = client.CreateCollection(ctx,
milvusclient.NewCreateCollectionOption("my_collection", schema).
WithProperty(common.MmapEnabledKey, "false"))
if err != nil {
fmt.Println(err.Error())
// handle error
}
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/collections/create" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
--data "{
\"collectionName\": \"my_collection\",
\"schema\": $schema,
\"params\": {
\"mmap.enabled\": \"false\"
}
}"
您也可以参考如下示例修改现有 Collection 的 mmap 配置。
- Python
- Java
- NodeJS
- Go
- cURL
# Release collection before change mmap settings
client.release_collection("my_collection")
# Ensure that the collection has already been released
# and run the following
client.alter_collection_properties(
collection_name="my_collection",
properties={
"mmap.enabled": false
}
)
# Load the collection to make the above change take effect
client.load_collection("my_collection")
client.releaseCollection(ReleaseCollectionReq.builder()
.collectionName("my_collection")
.build());
client.alterCollectionProperties(AlterCollectionPropertiesReq.builder()
.collectionName("my_collection")
.property(Constant.MMAP_ENABLED, "false")
.build());
client.loadCollection(LoadCollectionReq.builder()
.collectionName("my_collection")
.build());
// Release collection before change mmap settings
await client.releaseCollection({
collection_name: "my_collection"
});
// Ensure that the collection has already been released
// and run the following
await client.alterCollectionProperties({
collection_name: "my_collection",
properties: {
"mmap.enabled": false
}
});
// Load the collection to make the above change take effect
await client.loadCollection({
collection_name: "my_collection"
});
err = client.ReleaseCollection(ctx, milvusclient.NewReleaseCollectionOption("my_collection"))
if err != nil {
fmt.Println(err.Error())
// handle error
}
err = client.AlterCollectionProperties(ctx, milvusclient.NewAlterCollectionPropertiesOption("my_collection").
WithProperty(common.MmapEnabledKey, "false"))
if err != nil {
fmt.Println(err.Error())
// handle error
}
_, err := client.LoadCollection(ctx, milvusclient.NewLoadCollectionOption("my_collection"))
if err != nil {
fmt.Println(err.Error())
// handle err
}
# restful
export CLUSTER_ENDPOINT="https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530"
export TOKEN="YOUR_CLUSTER_TOKEN"
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/collections/release" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
-d '{
"collectionName": "my_collection"
}'
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/collections/alter_properties" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
-d '{
"collectionName": "my_collection",
"properties": {
"mmmap.enabled": false
}
}'
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/collections/load" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
-d '{
"collectionName": "my_collection"
}'
在修改 Collection 属性前,您需要 Release 目标 Collection,并在完成修改后,重新 Load 该 Collection。