使用 Partition Key
Partition Key 是一种搜索优化解决方案,通过作为 Collection 的 Namespace 来实现逻辑数据隔离。通过将特定标量字段(如租户 ID 或项目名称)指定为 Partition Key,您可以在单个 Collection 内将数据有效分割成不同的 Namespace。这使得搜索请求能够通过筛选条件限定在特定 Namespace 内,从而显著缩小搜索范围并提升整体效率。本文介绍如何实现这种基于 Namepsace 的优化以及使用 Partition Key 时的注意事项。
概述
在 Zilliz Cloud 中,您可以使用 Partition 来实现数据分组,并将搜索范围限制在若干 Partition 中来提升搜索效率。但是一个 Collection 中最多只能创建 1,024 个 Partition,使用 Partition 无法满足分组数量大于 1,024 的使用场景。
为了突破 Partition 的数量限制,Zilliz Cloud 推出了 Partition Key。在创建 Collection 时,您可以指定某个标量字段为 Partition Key。在 Collection 完成创建时,Zilliz Cloud 会在 Collection 中自动创建指定数量的 Partition。每个 Partition 对应 Parition Key 字段的某段取值范围。在插入 Entity 时,Zilliz Cloud 会先根据该 Entity 在 Partition Key 字段上的取值计算一个哈希值,然后将得到的哈希值和 partition_nums 参数值取模得到目标 Partition 的 ID,最后将 Entity 存入到该 Partition 中。

下图描述了在 Collection 未使用 Partition Key 和使用了 Partition Key 两种情况下,Zilliz Cloud 处理 Search 请求的过程。在未使用 Partition Key 时,Zilliz Cloud 会遍历全表查找与查询向量相似的结果。在使用了 Partition Key 后,Zilliz Cloud 仅遍历与请求中携带的基于 Partition Key 的过滤条件表达式相匹配的若干 Partition,搜索范围显而易见的缩小了。
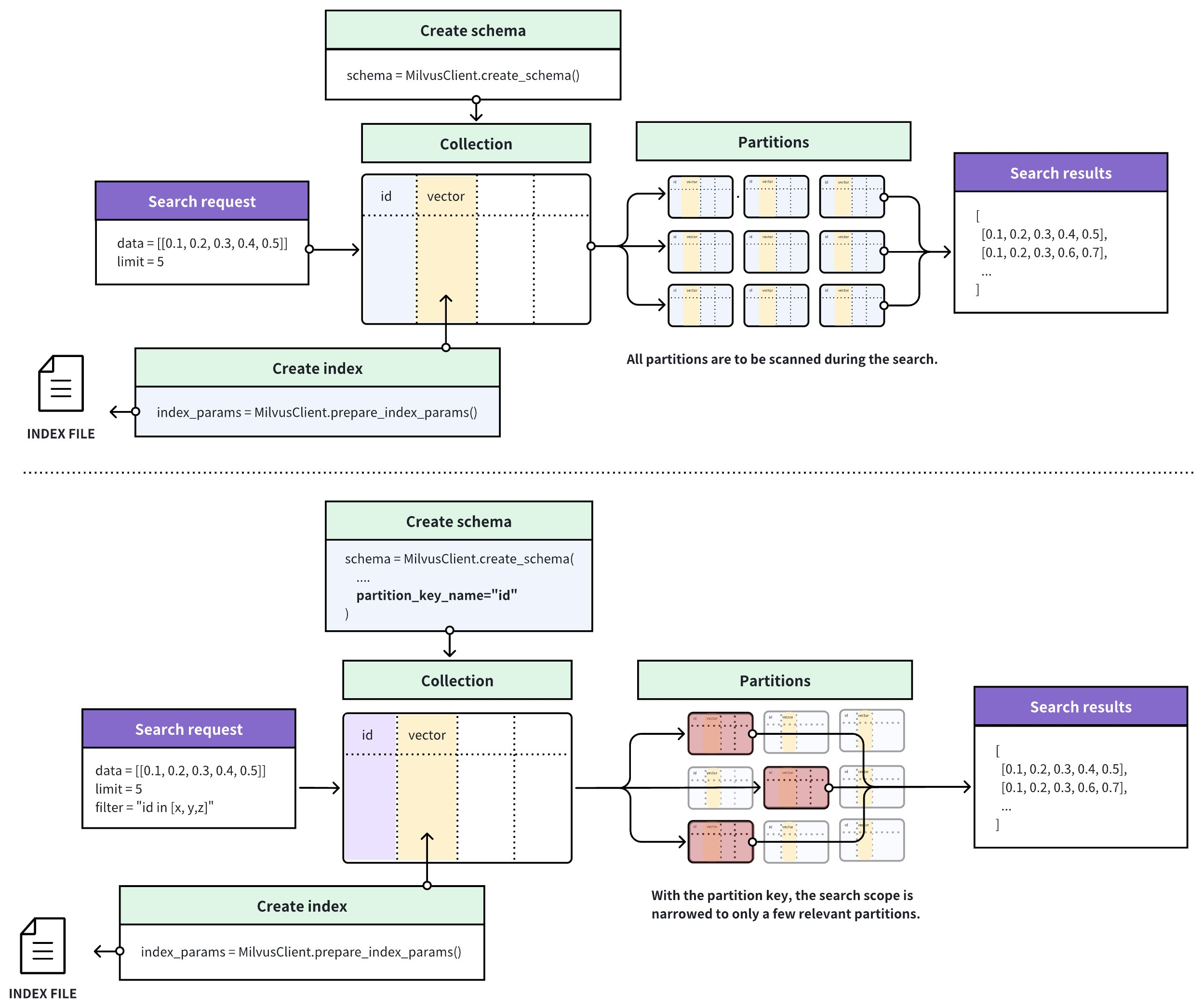
使用 Partition Key
如果您需要使用 Partition Key,需要完成如下设置:
指定 Partition Key
您需要在 Collection Schema 中添加待充当 Partition Key 的字段时,将其指定为 Partition Key。具体操作可以参考如下代码。
- Python
- Java
- Go
- NodeJS
- cURL
from pymilvus import (
MilvusClient, DataType
)
client = MilvusClient(
uri="https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530",
token="YOUR_CLUSTER_TOKEN"
)
schema = client.create_schema()
schema.add_field(field_name="id",
datatype=DataType.INT64,
is_primary=True)
schema.add_field(field_name="vector",
datatype=DataType.FLOAT_VECTOR,
dim=5)
# Add the partition key
schema.add_field(
field_name="my_varchar",
datatype=DataType.VARCHAR,
max_length=512,
# highlight-next-line
is_partition_key=True,
)
import io.milvus.v2.client.ConnectConfig;
import io.milvus.v2.client.MilvusClientV2;
import io.milvus.v2.common.DataType;
import io.milvus.v2.service.collection.request.AddFieldReq;
import io.milvus.v2.service.collection.request.CreateCollectionReq;
MilvusClientV2 client = new MilvusClientV2(ConnectConfig.builder()
.uri("https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530")
.token("YOUR_CLUSTER_TOKEN")
.build());
// Create schema
CreateCollectionReq.CollectionSchema schema = client.createSchema();
schema.addField(AddFieldReq.builder()
.fieldName("id")
.dataType(DataType.Int64)
.isPrimaryKey(true)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("vector")
.dataType(DataType.FloatVector)
.dimension(5)
.build());
// Add the partition key
schema.addField(AddFieldReq.builder()
.fieldName("my_varchar")
.dataType(DataType.VarChar)
.maxLength(512)
// highlight-next-line
.isPartitionKey(true)
.build());
import (
"context"
"fmt"
"github.com/milvus-io/milvus/client/v2/column"
"github.com/milvus-io/milvus/client/v2/entity"
"github.com/milvus-io/milvus/client/v2/index"
"github.com/milvus-io/milvus/client/v2/milvusclient"
)
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
milvusAddr := "https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530"
client, err := milvusclient.New(ctx, &milvusclient.ClientConfig{
Address: milvusAddr,
})
if err != nil {
fmt.Println(err.Error())
// handle error
}
defer client.Close(ctx)
schema := entity.NewSchema().WithDynamicFieldEnabled(false)
schema.WithField(entity.NewField().
WithName("id").
WithDataType(entity.FieldTypeInt64).
WithIsPrimaryKey(true),
).WithField(entity.NewField().
WithName("my_varchar").
WithDataType(entity.FieldTypeVarChar).
WithIsPartitionKey(true).
WithMaxLength(512),
).WithField(entity.NewField().
WithName("vector").
WithDataType(entity.FieldTypeFloatVector).
WithDim(5),
)
import { MilvusClient, DataType } from "@zilliz/milvus2-sdk-node";
const address = "https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530";
const token = "YOUR_CLUSTER_TOKEN";
const client = new MilvusClient({address, token});
// 3. Create a collection in customized setup mode
// 3.1 Define fields
const fields = [
{
name: 'id',
data_type: DataType.Int64,
is_primary_key: true,
},
{
name: 'vector',
data_type: DataType.FloatVector,
dim: 5,
},
{
name: 'my_varchar',
data_type: DataType.VarChar,
max_length: 512,
// highlight-next-line
is_partition_key: true,
},
];
export schema='{
"autoId": true,
"enabledDynamicField": false,
"fields": [
{
"fieldName": "id",
"dataType": "Int64",
"isPrimary": true
},
{
"fieldName": "vector",
"dataType": "FloatVector",
"elementTypeParams": {
"dim": "5"
}
},
{
"fieldName": "my_varchar",
"dataType": "VarChar",
"isPartitionKey": true,
"elementTypeParams": {
"max_length": 512
}
}
]
}'
设置 Partition 数量
当您指定某个标量字段为 Partition Key 后,Zilliz Cloud 会在 Collection 中默认创建 16 个 Partition。您也可以根据该标量字段的取值范围决定创建 Partition 的数量,最多不超过 1,024 个。
需要注意的是,在插入 Entity 时,Zilliz Cloud 会计算该 Entity 在 Partition Key 上的取值所对应的 Hash 值,并根据该 Hash 值决定将该 Entity 存入哪个 Partition 中。如果 Partition Key 可能的所有取值的数量大于 Partition 的数量,部分或所有 Partition 中可能会存在多种在 Partition Key 上取值不同的 Entity。
如果您需要,也可以参考如下代码在创建 Collection 时设置 Partition 的数量。注意,此设置仅在您参与上一步中的示例指定了 Partition Key 时有效。
- Python
- Java
- Go
- NodeJS
- cURL
client.create_collection(
collection_name="my_collection",
schema=schema,
# highlight-next-line
num_partitions=128
)
import io.milvus.v2.service.collection.request.CreateCollectionReq;
CreateCollectionReq createCollectionReq = CreateCollectionReq.builder()
.collectionName("my_collection")
.collectionSchema(schema)
.numPartitions(128)
.build();
client.createCollection(createCollectionReq);
err = client.CreateCollection(ctx,
milvusclient.NewCreateCollectionOption("my_collection", schema).
WithNumPartitions(128))
if err != nil {
fmt.Println(err.Error())
// handle error
}
await client.create_collection({
collection_name: "my_collection",
schema: schema,
num_partitions: 128
})
export params='{
"partitionsNum": 128
}'
export CLUSTER_ENDPOINT="https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530"
export TOKEN="YOUR_CLUSTER_TOKEN"
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/collections/create" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
-d "{
\"collectionName\": \"my_collection\",
\"schema\": $schema,
\"params\": $params
}"
创建基于 Partition Key 的过滤条件表达式
在使用 Partition Key 进行搜索时, Search 请求中需要携带一个基于 Partition Key 的过滤条件表达式。在过滤条件表达式中,您既可以把搜索范围限定在某一个 Partition Key 值对应的 Partition 内,也可以将其限定在多个 Partition Key 值对应的 Partition 内。
执行删除操作时,建议包含指定单个 Partition Key 的过滤条件表达式,以实现更高效的删除。这种方法将删除操作限制在特定分区,减少压缩期间的写放大,并为压缩和索引节省资源。
如下代码演示了 Search 请求中需要携带的两种过滤条件表达式:一种是基于一个 Partition Key 值进行过滤,另一个是基于多个 Partition Key 值进行过滤。
- Python
- Java
- Go
- NodeJS
- cURL
# Filter based on a single partition key value, or
filter='partition_key == "x" && <other conditions>'
# Filter based on multiple partition key values
filter='partition_key in ["x", "y", "z"] && <other conditions>'
// Filter based on a single partition key value, or
String filter = "partition_key == 'x' && <other conditions>";
// Filter based on multiple partition key values
String filter = "partition_key in ['x', 'y', 'z'] && <other conditions>";
// Filter based on a single partition key value, or
filter = "partition_key == 'x' && <other conditions>"
// Filter based on multiple partition key values
filter = "partition_key in ['x', 'y', 'z'] && <other conditions>"
// Filter based on a single partition key value, or
const filter = 'partition_key == "x" && <other conditions>'
// Filter based on multiple partition key values
const filter = 'partition_key in ["x", "y", "z"] && <other conditions>'
# Filter based on a single partition key value, or
export filter='partition_key == "x" && <other conditions>'
# Filter based on multiple partition key values
export filter='partition_key in ["x", "y", "z"] && <other conditions>'
使用 Partition Key Isolation
在诸如多租户的场景下,建议您将用于标识租户身份的字段设置为 Parition Key。这时,过滤条件表达式中一般只会基于某一个租户身份进行过滤。为了进一步缩小搜索范围,Zilliz Cloud 对 Partition Key 功能做了进一步增强,推出了 Partition Key Isolation 功能。
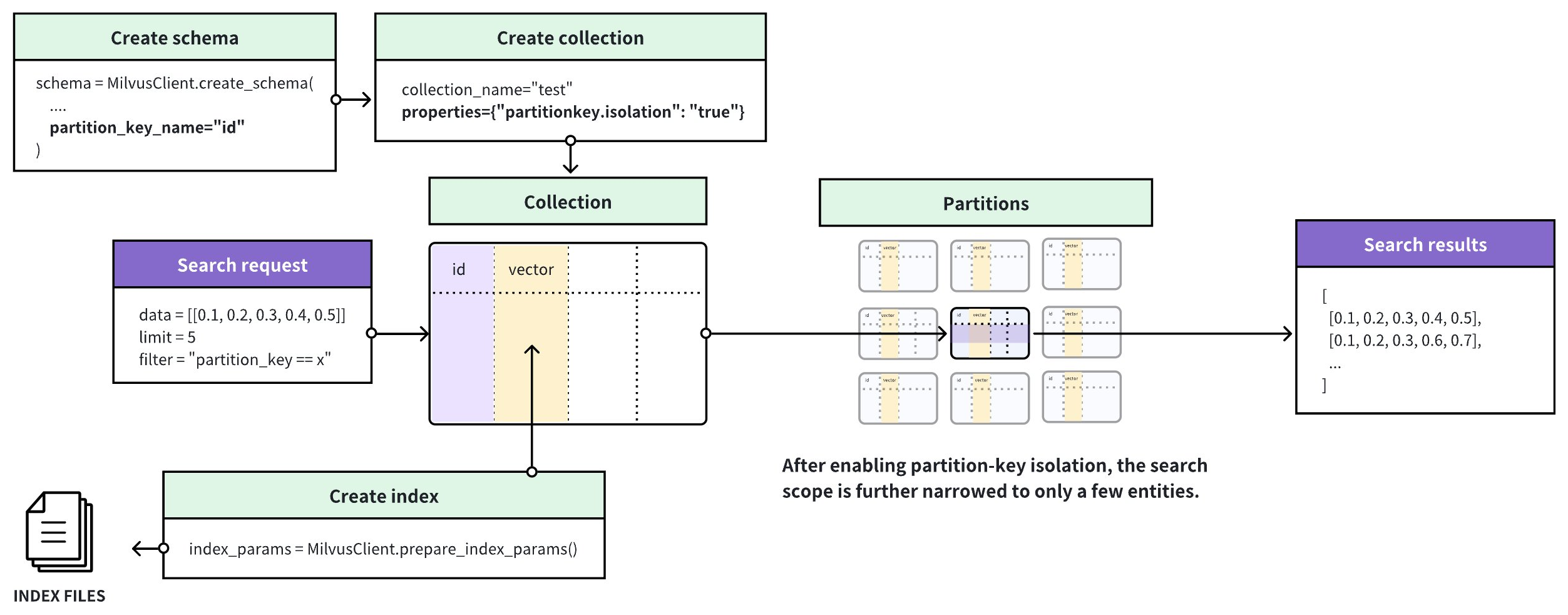
如上图所示,当您在创建或修改 Collection 时打开了 Partition Key Isolation 功能后,Zilliz Cloud 会根据 Entity 中 Partition Key 的值为 Entity 分组,并为指定的向量字段在每组 Entity 中创建一个独立的索引。在收到 Search 请求后,Zilliz Cloud 会根据过滤条件表达式中指定的 Partition Key 值找到对应的索引文件,并在该索引文件覆盖的所有 Entity 中进行相似最近邻搜索(ANN Search)。这样一来,Zilliz Cloud 就真正避免了在执行 Search 请求时扫描无关记录,进一步缩小了搜索范围,提升了搜索效率。
值得注意的是,在开启了 Partition Key Isolation 后,您仅能基于一个确定的 Partition Key 值创建过滤表达式,从而让 Zilliz Cloud 将搜索范围控制在该值对应的索引文件所覆盖的所有 Entity 内。
开启 Partition Key Isolation
如果您需要使用 Partition Key Isolation 功能,可以参考如下代码在创建 Collection 时手动开启该功能。
- Python
- Java
- Go
- NodeJS
- cURL
client.create_collection(
collection_name="my_collection",
schema=schema,
# highlight-next-line
properties={"partitionkey.isolation": True}
)
import io.milvus.v2.service.collection.request.CreateCollectionReq;
Map<String, String> properties = new HashMap<>();
properties.put("partitionkey.isolation", "true");
CreateCollectionReq createCollectionReq = CreateCollectionReq.builder()
.collectionName("my_collection")
.collectionSchema(schema)
.properties(properties)
.build();
client.createCollection(createCollectionReq);
err = client.CreateCollection(ctx,
milvusclient.NewCreateCollectionOption("my_collection", schema).
WithProperty("partitionkey.isolation", true))
if err != nil {
fmt.Println(err.Error())
// handle error
}
res = await client.alterCollection({
collection_name: "my_collection",
properties: {
"partitionkey.isolation": true
}
})
export params='{
"partitionKeyIsolation": true
}'
export CLUSTER_ENDPOINT="https://{cluster-id}.{region}.vectordb.zilliz.com.cn:19530"
export TOKEN="YOUR_CLUSTER_TOKEN"
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/collections/create" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
-d "{
\"collectionName\": \"my_collection\",
\"schema\": $schema,
\"params\": $params
}"
在开启 Partition Key Isolation 后,您仍旧可以参考使用 Partition Key 一节中的描述指定 Partition Key 和设置 Partition 数量。但在创建基于 Partition Key 的过滤条件表达式时,您仅能基于一个确定的 Partition Key 值创建过滤表达式,从而让 Zilliz Cloud 将搜索范围控制在该值对应的索引文件所覆盖的所有 Entity 内。